Mysql索引实现原理及相关优化策略
数据库索引
数据库索引是什么?
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed.
数据库索引的本质是数据结构,这种数据结构能够帮助我们快速的获取数据库中的数据。
数据库为什么要使用索引?
从定义中我们就知道,使用索引就是为了提高效率。下面的例子能让我们直观的看到索引的作用。
我们有下面一张employees表,大概三十万行。
+--------+------------+------------+--------------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+--------------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 |
| 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10007 | 1957-05-23 | Tzvetan | Zielinski | F | 1989-02-10 |
| 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 |
| 10009 | 1952-04-19 | Sumant | Peac | F | 1985-02-18 |
| 10010 | 1963-06-01 | Duangkaew | Piveteau | F | 1989-08-24 |
| . | . | . | . | . | . |
| . | . | . | . | . | . |
| . | . | . | . | . | . |
| 499999 | 1958-05-01 | Sachin | Tsukuda | M | 1997-11-30 |
| 499998 | 1956-09-05 | Patricia | Breugel | M | 1993-10-13 |
| 499997 | 1961-08-03 | Berhard | Lenart | M | 1986-04-21 |
| 499996 | 1953-03-07 | Zito | Baaz | M | 1990-09-27 |
| 499995 | 1958-09-24 | Dekang | Lichtner | F | 1993-01-12 |
| 499994 | 1952-02-26 | Navin | Argence | F | 1990-04-24 |
| 499993 | 1963-06-04 | DeForest | Mullainathan | M | 1997-04-07 |
| 499992 | 1960-10-12 | Siamak | Salverda | F | 1987-05-10 |
| 499991 | 1962-02-26 | Pohua | Sichman | F | 1989-01-12 |
| 499990 | 1963-11-03 | Khaled | Kohling | M | 1985-10-10 |
+--------+------------+------------+--------------+--------+------------+
我们想找到first_name为Chirstian的结果,下面比较一下加上索引前后查询所耗费的时间,从结果我们可以看出使用索引可以使查询效率提高20倍。
mysql> select * from employees where first_name = 'Chirstian';
mysql> alter table employees add index first_name (first_name);
mysql> select * from employees where first_name = 'Chirstian';
mysql> SHOW PROFILES;
+----------+------------+---------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------+
| 1 | 0.17415400 | select * from employees where first_name = 'Chirstian' |
| 2 | 1.03130100 | alter table employees add index first_name (first_name) |
| 3 | 0.00869100 | select * from employees where first_name = 'Chirstian' |
+----------+------------+---------------------------------------------------------+
既然索引的作用这么大,那我们给每列都加上索引不就可以使效率最大化了吗?
答案是否定的,具体原因要我们了解索引的实现原理才能明白。
MySQL索引实现
写在前面
我们了解MySQL索引是什么以及如何实现的目的是为了更高效的使用MySQL,而不是为了去真的实现一个数据库。所以我们这里只介绍MySQL的两个常用引擎Myisam以及Innodb的实现原理。
Myisam和Innodb引擎都是使用B+树作为索引结构,实现上略有差别,所以我们先看看什么是B+树。选择B+树而不是其他数据结构的原因主要是因为数据是保存在硬盘上而不是内存中,所以减少磁盘IO次数才是提升效率的关键。如果对具体原理感兴趣,可以自行google,这对我们如何优化作用有限所以就不展开说了。
B+树索引
一图胜万言,下面就是一个B+树。
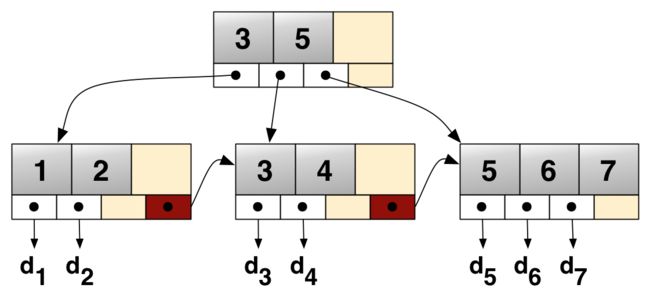
- 节点
与二叉树不同的是,B+中的节点可以有多个元素及多个子节点。在B+索引树中,非叶子节点由索引元素和指向子节点的指针组成,他们的作用就是找到叶子节点,因为只有叶子节点中有最终要找的数据信息。从图中可以看出每个节点中指针的数量比索引元素数量多一个,在叶子节点中,因为没有子节点,多出的那个指针指向下一个叶子节点,这样把所有叶子节点串联起来,这对于范围搜索很有用。在实际应用中一个节点的大小是固定的通常等于磁盘一个页的大小,这样存取一个节点只需要一次磁盘IO,一般节点可存上百个元素,所以索引几百万数据B+树高不会超过3。
- 搜索
搜索类似于二叉查找树,从根节点开始自顶向下遍历,直到叶子节点,在节点内部典型的是使用二分查找来确定位置。如果是范围查找,对于B+树而言是非常方便的,因为叶子节点是有序且连续的。
- 插入
首先对树进行搜索找到应该存入的叶子节点。之前我们提到节点的大小是固定的,如果节点内还没放满,则直接插入。如果节点满了,则创建新节点把原节点插入新元素后的一半放入新节点,然后把新节点最小的元素插入父节点。如果父节点满了,进行同样的操作,根节点也不例外。
- 删除
首先对树进行搜索找到叶子节点并删除元素。当删除后的叶子节点不满一半时:如果兄弟节点过半数则借一个过来,并更新父节点中子节点的分界值;如果等于半数则合并,因为父节点中有两个指针指向这两个兄弟节点,所以需要删除多余的一个来更新父节点,如果删除后父节点不满一半,继续递归以上步骤,直到根节点。
从B+树的特点可以看出,虽然B+树索引能够让我们在有限次磁盘IO次数内快速的查询到数据,但是在插入和删除时也要付出维护B+树的代价,这也是为什么在开始说的不能把每列都加上索引的原因之一。
为了帮助大家更好的理解,这个网站通过动画展示了B+树的查询、插入、删除操作的实现过程。这个视频分3集讲解了B+树和在索引中的实现,不过因为在youtube上,才能看。
Myisam与Innodb索引的区别
虽然它们都是用B+树实现的索引,但是实现上略有差别,主要有两点。
- 叶子节点存储数据内容的差别
Myisam存储的是存放真实数据的地址,而Innodb存储的是真实的数据。其实Innodb存储的数据本身就是主键的B+树索引,因为索引内存储着真实的数据。
- 辅助索引叶子节点存储数据内容的差别
Mysiam存储的还是真实数据的地址,与主索引一样。Innodb存储的是主键的值。
题外话:在一般后端工程师的面试中都会有关于MySQL的问题,其中比较Myisam和Innodb引擎就是常问的一个。网上的答案也都比较陈旧而且只有结论没有验证。比如比较中有一项是否支持Full-text索引,其实Innodb在MySQL5.6中就已经支持了,不过大多数答案都没有更新。还有完全不考虑实际情况就说Myisam在查、Innodb在增删改上更快,我在网上很久也没有找到支撑这些结论的理论或者实验基础。
就我个人而言我更推荐使用Innodb引擎,所以前面我没有深入的比较它们索引的差别。推荐Innodb不单单是因为它在5.5版本之后成为MySQL的默认引擎,还有它拥有支持事务、外键、MVCC、行锁这些更先进的引擎技术。为了类似于不带where的count时Myisam速度更快这样模棱两可的性能差别,而抛弃这些先进的技术,很不值得。而且即使真的像上面所说的Innodb在查时性能稍差于Myisam,我也不认为会因此成为整个架构性能的瓶颈所在,如果真的需要更换引擎来提升性能了,那在架构其他地方的问题可能更大。
MySQL索引类型及优化策略
索引类型
- 唯一索引(unique index)
看见名字我们就知道,唯一索引列中的值必须是唯一的。不过有一个例外,可以有且可以有多个Null。
- 普通索引(index)
普通索引可以包括不止一列,一般把多个列组成的普通索引叫组合索引,也有把普通索引看成是只有一列的组合索引的。此外,在索引字符串时,可以只把前几位作为索引来提升效率。
- 主键(primary key)
主键必须唯一,不同的是不能有Null。而且一个表只能有一个主键。有很多人认为主键是唯一索引的一种,其实是不准确的。主键也可以是组合索引,只要组合的每条结果是唯一的。这在某些场景非常实用,比如一个多对多关系中的枢纽表就非常适合使用复合主键。下图就是一个典型的用户权限功能的实现,用户和角色、角色和权限都是多对多的关系,需要枢纽表来记录他们之间的对应关系,而这些关系都是唯一的,所以这种枢纽表用复合主键非常合适。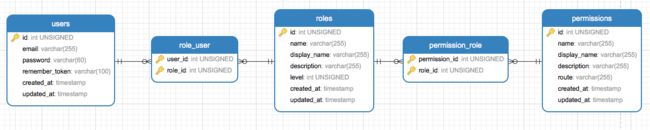
优化策略
最左前缀匹配原则
还拿前面的employees表举例,比如我们建立一个(birth_date, first_name, last_name ) 的组合索引。
mysql> alter table employees add index bd_fn_ln (birth_date, first_name, last_name);
下面的查询是用到索引的:
mysql> select * from employees where birth_date = '1954-05-01' and first_name = 'Chirstian' and last_name = 'Koblick';
mysql> select * from employees where birth_date = '1954-05-01' and first_name = 'Chirstian';
mysql> select * from employees where birth_date = '1954-05-01' and last_name = 'Koblick';
下面是这三个查询explain结果。
mysql> explain select * from employees where birth_date = '1954-05-01' and first_name = 'Chirstian' and last_name = 'Koblick';
+----+-------------+-----------+------+---------------+----------+---------+-------------------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+----------+---------+-------------------+------+-----------------------+
| 1 | SIMPLE | employees | ref | bd_fn_ln | bd_fn_ln | 97 | const,const,const | 1 | Using index condition |
+----+-------------+-----------+------+---------------+----------+---------+-------------------+------+-----------------------+
1 row in set (0.00 sec)
mysql> explain select * from employees where birth_date = '1954-05-01' and first_name = 'Chirstian' ;
+----+-------------+-----------+------+---------------+----------+---------+-------------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+----------+---------+-------------+------+-----------------------+
| 1 | SIMPLE | employees | ref | bd_fn_ln | bd_fn_ln | 47 | const,const | 1 | Using index condition |
+----+-------------+-----------+------+---------------+----------+---------+-------------+------+-----------------------+
1 row in set (0.01 sec)
mysql> explain select * from employees where birth_date = '1954-05-01' and last_name = 'Koblick';
+----+-------------+-----------+------+---------------+----------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+----------+---------+-------+------+-----------------------+
| 1 | SIMPLE | employees | ref | bd_fn_ln | bd_fn_ln | 3 | const | 60 | Using index condition |
+----+-------------+-----------+------+---------------+----------+---------+-------+------+-----------------------+
1 row in set (0.00 sec)
虽然结果都是一条,不过前两个查询都用到了联合索引。最后一个只用到了birth_date这一个索引,所以会在birth_date = 1954-05-01 的60结果中遍历last_name来找到等于Koblick的结果。还有, 如果where中都是精确匹配(使用’=’号),那它们的顺序不会影响索引的使用。
而下面这个查询因为没用到组合索引的最左列,所以不会用到索引而是遍历了所有的数据,这就是最左前缀匹配:
mysql> select * from employees where first_name = 'Chirstian' and last_name = 'Koblick';
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 |
+--------+------------+------------+-----------+--------+------------+
1 row in set (0.18 sec)
mysql> explain select * from employees where first_name = 'Chirstian' and last_name = 'Koblick';
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 299468 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
1 row in set (0.00 sec)
选择区分度高的列作为索引
区分度:count(distinct col)/count(*)。 区分度是一个介于0和1之间的小数,越接近1区分度越高,越适合做索引。 原因很容易理解,比如一个辞典中全是以a和b开头的单词,那么按照首字母简历一个目录(索引),那么目录上一共就两条,每条的范围对应差不多半本辞典,那这个目录(索引)毫无用处。相反,一个班级的学生信息以学号做索引,那么区分度为1,只要找到学号就能直接找到相对应的学生信息,这个索引就非常有效。
不要在比较运算符左侧使用函数或进行计算
在SQL语句的比较运算符左侧使用函数或进行计算会使索引失效。
mysql> explain select * from employees where emp_no + 1 = 10005;
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 299468 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
1 row in set (0.11 sec)
mysql> explain select * from employees where emp_no = 10005-1;
+----+-------------+-----------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | employees | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-----------+-------+---------------+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
事例数据库
以上用做事例的employees表来自MySQL官方事例数据库-employees,里面有安装说明,数据库大小合适,非常适合练习。