Hadoop-2.7.6集群搭建(最清晰易懂)
Hadoop集群结构
核心:HDFS+MapReduce
集群搭建步骤
准备三台虚拟机,这里使用的是ubuntu16.04,将虚拟机的网络进行桥接配置,使他们之间能够互相访问。
- 更改虚拟机的主机名以及配置网址域名和它的IP地址的映射关系
- 配置ssh免密登录
- 为虚拟机安装好jdk
- 安装hadoop并配置相应文件
- 初始化HDFS
- 批量启动HDFS
过程
1.为3台虚拟机配置好IP地址以及映射关系
#sudo gedit /etc/hosts
在最上面添加主机和从机的IP地址及网址域名:
我这里添加的是
192.168.101.125 master
192.168.101.126 slave1
192.168.101.127 slave2
添加好后,再将主机名修改为master,否则可能会使输入的命令无法被识别
#sudo gedit /etc/hostname
将原来的主机名替换为master
2.配置ssh免密登录
#sudo apt-get install openssh-server
安装完成之后,接下来配置免密
#/etc/init.d/ssh restart
#ssh-keygen -t rsa
如果你已经生成过key,那么他会提醒你id_rsa已经存在;那么你需要重新生成一个免密的key,如果没有生成过,那么每一步都需要按回车确认。
完成之后,将公钥添加到.ssh/authorized_keys
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
配置完成后,尝试一下是否能登录成功
#ssh localhost
登录成功,如图所示

注意:在ssh中输入的命令,与虚拟机中相同,每次登录过后记得执行exit退出
3.安装jdk
检查是否已经安装了jdk
#java -version
在网上找到jdk1.8.0_162(版本相近的jdk都可以),下载好了之后,执行解压安装命令,这里我jdk的目录为 /usr/local/java/jdk1.8.0_162
#sudo gedit /etc/profile
在最后面的位置为jdk配置环境变量,加入以下代码
export JAVA_HOME=/usr/local/java/jdk1.8.0_162
export PATH= P A T H : PATH: PATH:HOME/bin:$JAVA_HOME/bin
然后保存退出,执行以下代码
#source /etc/profile
每次登录系统时才会重新读取环境变量,这里的操作是为了避免重启,但是在退出界面后就会失效,所以建议配置完环境之后重启虚拟机使环境生效。
然后再次检查一下jdk是否安装成功
#java -version
如图所示,

4.安装hadoop-2.7.6并配置相应文件
第一步,安装hadoop。
下载好安装包后,上传到虚拟机解压安装,
#tar zxf hadoop-2.7.6.tar.gz
#sudo mv hadoop-2.7.6 /usr/local/
这里,将解压好的文件hadoop-2.7.6移动到 /usr/local/ 的目录下。下一步就是为hadoop配置环境变量。
#sudo gedit /etc/profile
在配置文件的最下面添加上:
export HADOOP_HOME=/usr/local/hadoop-2.7.6
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin
如图所示,
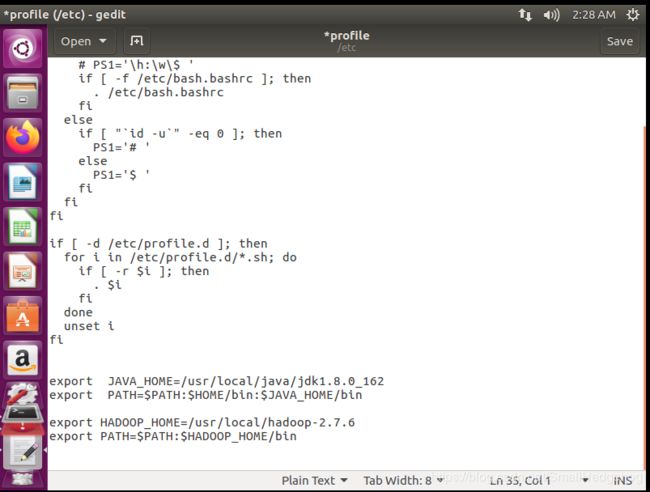
同之前的jdk一样,配置好环境之后需要执行source /etc/profile,使环境生效。
接下来,测试hadoop是否安装成功。
#hadoop version
如图所示,hadoop安装完成。

第二步,配置hadoop的配置文件
首先,进入文件目录
cd /usr/local/hadoop-2.7.6/etc/hadoop/
在这里面需要配置的文件有:
1、hadoop-env.sh:用来配置hadoop所需要的jdk的环境,是hadoop可以调用本机的jdk。
2、core-site.xml :里面的参数
fs.defaultFS,用来说明hadoop使用什么文件系统。
hadoop.tmp.dir,hadoop文件存储目录。
还有两个参数一般不做修改,
fs.checkpoint.period,表示多长时间记录一次hdfs的镜像,默认是1小时。
fs.checkpoint.size,表示镜像文件快大小,默认64M。
3、hdfs-site.xml:用来指定namenode和datanode的存放目录,还有存放数据的副本数,一般默认为3。
4、mapred-site.xml:mapreduce的参数。
5、yarn-site.xml :集群资源管理系统参数。
6、slaves:需要启动datanode和nodemanager的虚拟机
修改内容如下:
#sudo gedit hadoop-env.sh

#sudo gedit core-site.xml
>
>
>fs.defaultFS >
>hdfs://master:9000 >
>指定HDFS的(NameNode)的地址 >
>
>
>hadoop.tmp.dir >
>file:/usr/local/hadoop-2.7.6/dfs/tmp >
>指定hadoop运行时产生文件的存储目录 >
>
>
#sudo gedit hdfs-site.xml
>
>
>dfs.replication >
>3 >
>指定HDFS副本的数量 >
>
>
>dfs.namenode.name.dir >
>file:/usr/local/hadoop-2.7.6/dfs/name >
>namenode的存储路径 >
>
>
>dfs.datenode.date.dir >
>file:/usr/local/hadoop-2.7.6/dfs/date >
>指定datenode的路径 >
>
>
#mv mapred-site.xml.template mapred-site.xml
#sudo gedit mapred-site.xml
>
>
>mapreduce.framework.name >
>yarn >
>
>
#sudo gedit yarn-site.xml
>
>
>yarn.resourcemanager.hostname >
>master >
>
>
>yarn.nodemanager.aux-services >
>mapreduce_shuffle >
>
>
#sudo gedit slaves
在里面添加两台从机,

完成配置。
5、初始化HDFS
回到根目录下,然后在主机上初始化namenode,
#cd /
#hdfs namenode -format
6、启动HDFS
#start-all.sh
#jps
如图所示,主机显示情况

在从机上输入jps查看,没有NameNode和SecondaryNameNode,存在DataNode。
以上就是搭建集群的全部过程。
接下来有几点注意事项:
1、如果DataNode没有启动,那就说明你可能原本DataNode的目录被使用过了,里面的对于NameNode的编号与现在的不一致。解决方法:如果DataNode文件夹里存在数据,那么你需要修改Current下的version,使其与DataNode上的保持一致。如果DataNode里面没有数据,是刚搭建的,那么可以先将HDFS关闭,然后删除DataNode文件夹,再次打开HDFS,这样的话,DataNode就会重新获取NameNode的信息,就可以连接上了。
2、免密登录时必不可少的,那么要求每一台设备之间都可以互相访问,这就需要每一台设备里面的~/.ssh/id_rsa.pub 和 ~/.ssh/authorized_keys 都保持一致,只要这样才可以互相访问成功。
3、有一点很特殊的地方,在你ssh访问登录时,会保留你此时登录该域名的信息。举个例子,在你第一次ssh slave1时,这样的登录会被保留下来,以slave1的形式。那么在你下次将另一台设备设置为slave1时,就无法完成登录,因为映射表中已经存在了信息,那么你就需要根据反馈的信息将原先的删除后才可以使用。