数栈-离线数据开发学习笔记
个人博客原文链接
离线任务开发
离线任务开发模块主要是设计数据计算流程,并实现为多个相互依赖的任务,供调度系统自动执行的主要操作页面。
对象
在数据开发阶段,DTinsightBatch提供了4种对象:任务、脚本、资源和函数。它们之间的项目关系如下图所示:
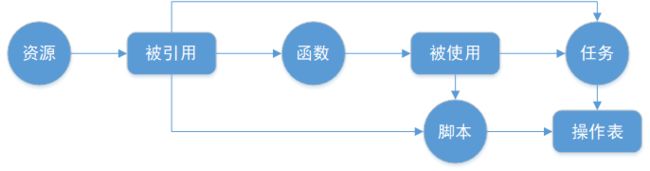
任务:数据开发的主要对象,包含周期属性和依赖关系,是数据计算的主要载体,支持多种类型的任务和节点适应不同场景,详情请参见任务类型。
脚本:数据开发的辅助对象,不包含周期属性和依赖关系,主要用于实现非周期的临时数据处理,如临时表的增删改等,详情请参见脚本开发。
函数和资源:任务中的代码运行时需要引用的一些文件和计算函数,在任务正式执行前需要上传,详情请参见资源管理和函数管理。
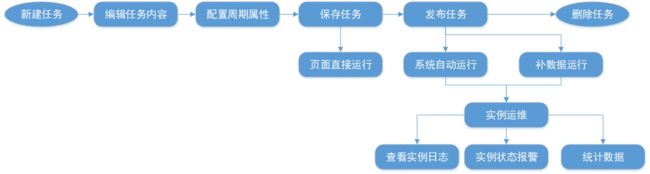
流程
一个任务的开发和使用流程如下图所示:
任务类型
- SQL任务
SQL任务支持直接在Web端编辑和维护SQL代码,并可方便地调试运行和协作开发。DTinsightBatch还支持代码内容的版本管理和上下游依赖自动解析等功能。
DTinsightBatch的SQL任务的代码内容遵循Hive的语法。 - MR任务
MR任务用于在Spark的MapReduce编程接口(Java API)基础上实现的数据处理程序的周期运行。
DTinsightBatch完全按照Spark官方的编程接口,将代码打包成为JAR类型的资源文件上传到DTinsightBatch中,然后配置MR任务。 - 数据同步任务
数据同步任务主要完成数据在不同存储单元之间的迁移。 - PySpark任务
Python任务用于在Spark的Python编程接口(Python API)基础上实现的数据处理程序的周期运行。
DTinsightBatch完全按照Spark官方的编程接口,您可以将代码打包,并以资源文件的形式上传到DTinsightBatch中,然后配置Python任务。 - 虚节点任务
虚拟节点属于控制类型节点,它不产生任何数据的空跑节点,常用于多个任务统筹节点的根节点。 - shell
Shell类型任务支持标准的Shell语法,不支持交互式语法。 - 深度学习
目前支持TensorFlow、MXNet2种深度学习框架,用户可编写基于深度学习框架的代码,由DTinsightBatch提交到对应的框架中运行,并可以与DTinsightBatch中的其他任务配合形成调度依赖关系。 - 原生Python
目前支持Python2、Python3的代码,由DTinsightBatch提交运行,支持在页面中直接运行Python代码或打包上传运行,可以与DTinsightBatch中的其他任务配合形成调度依赖关系。
新建任务
1.新建SQL任务
进入“数据开发”菜单,点击“新建离线任务”按钮,并填写新建任务弹出框中的配置项。
任务名称:需输入英文字母、数字、下划线组成,不超过64个字符。
任务类型:可选择SQL、MR、数据同步、Python、虚节点。
存储位置:此任务在页面左侧的任务存储结构中的位置。
描述:此任务的描述,可输入长度不超过200个的任意字符。
如下图所示:

2.编辑SQL任务代码
SQL任务创建好后,可以在代码编辑器中编写SQL语句(该SQL的语法为Hive SQL)。
3.配置节点任务的调度属性
DTinsightBatch提供了丰富的时间周期和依赖关系支持,并提供了基于时间的系统参数和自定义参数支持。
代码和参数配置调试完毕后,一个周期任务需要发布以后才会触发调度系统按配置周期定时产生运行实例并执行代码。
为使周期任务运行并在每次运行时适应上下文环境,需要配置时间周期和参数。
注:由于节点任务有周期调度属性,因此内容建议以计算类语句为主,表操作语句建议使用可视化建表和脚本开发等其他功能来运行和维护。
如下图所示:
创建表
1.可视化建表
进入项目以后,数据模型>模型设计>建表
2.SQL建表
新建一个类型为SQL的脚本文件,在编辑区填写任意SQL语句(包括新建或修改表的DDL语句)并单击直接运行。
建表语法如下:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
lifecycle N;
注:DTinsightBatch的建表语句与通用的Hive不同,建表时需要指定生命周期。
3.查找数据
点击数据模型>模型设计,搜索表名,找到新建的表进行查询。
如图所示:
表查询
在数据开发页面,表查询模块下,默认会展示当前项目的表,单击表名即可看到表的列信息、分区信息以及数据预览。
注:表查询中不支持新建目录,将表放到目录下分类。
注:数据预览的数据是实时的。
如图所示:

任务运行
DTinsightBatch提供了3种运行方式,以使任务中的计算语句生效,适用场景和限制条件如下:
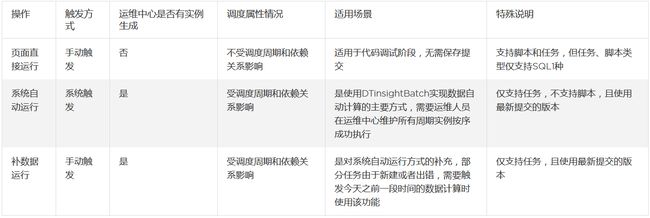
发布任务
提交任务操作,使得一个周期任务的代码和周期配置进入调度系统,从第二天开始,调度系统将根据该任务的周期配置每天生成实例并定时运行,直到该任务被删除,调度系统才会停止为该任务生成实例并运行。
注:新增或修改任务时,如果当天22:00前发布成功,则在第二天的实例中即可看到结果;如果当天22:00后发布成功,则在第三天的实例中才会看到结果。
注:一个周期任务只有发布成功后才会进入调度系统,从而使得调度系统按配置周期定时产生实例并运行。
- 发布SQL任务
单击打开该任务,在右上角点击“提交”按钮,可输入发布的备注信息,点击“确定”。 - 查看任务历史版本
发布任务之后,系统会产生一条版本记录,通过点击任务开发-任务属性-历史发布版本中查看发布的时间和备注信息的。
如图所示:

- 对比任务版本
在SQL任务的历史发布版本中,可以查看到曾经提交过的代码。选择查看某个代码版本,点击代码,系统可对比当前代码与选中版本的代码的差别。
冻结任务
如果需要让某个任务停止运行一段时间,可以在任务开发模块打开某任务,在右侧调度依赖面板中勾选冻结,表示此任务进入冻结状态。

- 处于冻结状态的任务,其周期实例依然会生成,但不会运行。
- 对于存在依赖关系的多个任务,如果将上游任务A冻结,则下游任务B也会进入“冻结”状态,B任务的实例也会产生,但不会运行,在B任务的执行日志中会打印出是由于A任务被冻结才没有运行的。
- 周期任务的冻结,是第二天生效的,且冻结状态的任务,生成的实例也是冻结状态,不会直接运行,必须将实例解冻后再单击重跑,才会运行;如果需要紧急冻结任务,可以在周期实例中进行冻结操作。
注:依然可以对冻结状态的任务执行补数据,补数据实例会正常运行。
删除任务
如果在编辑过程中想要放弃一个任务编辑版本,或者周期任务提交后想从调度系统中去掉该任务的自动运行,可以在左侧的任务面板中右键点击此任务,选择删除。
- 如果此任务被其他任务依赖(是其他任务的上游任务),则此任务不能被删除,您需要先解除依赖关系再进行删除。
- 任务删除后,已生成的任务实例不会被删除,但会运行失败。
搜索任务
当任务数量很多时,可以在数据开发界面中的上方点击搜索,或按下Ctrl+P快捷键,通过输入任务名称并按下回车搜索并打开任务。
调度属性配置
任务的时间属性目前支持月、周、天、小时和分钟5种配置方式。
注1:上游依赖的实例没有全部运行成功并且定时运行时间已到,则实例不会运行。
注2:上游依赖的实例全部运行成功并且定时运行时间还未到,则实例不会运行。
注3:上游依赖的实例全部运行成功并且定时运行时间已到,则实例具备了运行的条件,待其获得集群的计算资源后即可以开始运行,集群资源的分配由Spark集群分配,用户不可干预。
调度属性
调度属性的配置包括如下内容:此任务接受调度还是停止调度?此任务在什么时间生效?多长时间间隔运行一次?具体什么时候运行?如下图所示:
- 调度状态
选中“冻结”,表示此任务停止调度,不会进行实际的计算(通常此功能用于暂时不需要运行,但也不想删除的任务); 若勾选“冻结”,任务每天仍会产生实例,但调度时会直接返回失败状态,不会真正运行任务逻辑。 - 生效日期:任务只在生效日期内执行;
- 调度周期:分为{天;周;月;小时;分钟},若选中“天”,则表示此任务每天执行一次;
- 起调时间:用户设定调度周期后,还需要设定具体在哪个时刻点启动任务。根据用户选择的调度周期不同,起调时间需要配置不同的参数。
任务实例的生成
DTinsightIDE在每天22:00统一生成第二天所有需要的任务实例,基于以上设计,任务开发时需要注意任务的提交时间,这里以一个天周期调度任务A为例:

任务被配置为冻结是否生成实例?
答:处于冻结状态的任务,其周期实例依然会生成,但不会运行。
对于存在依赖关系的多个任务,如果将上游任务A冻结,则下游任务B也会进入“冻结”状态,B任务的实例也会产生,但不会运行,在B任务的执行日志中会打印出是由于A任务被冻结才没有运行的。
任务被删除是否会影响实例的运行?
答:如果此任务被其他任务依赖(是其他任务的上游任务),则此任务不能被删除,您需要先解除依赖关系再进行删除。
任务删除后,已生成的任务实例不会被删除,但会运行失败 。
想在每月的最后一天计算当月数据怎么办?
答:目前系统不支持配置每月最后一天,因此如果时间周期选择每月31日,那么在有31日的月份会有一天调度,其他日期都是生成实例然后直接设为运行成功。
需要统计每个月的数据时,建议选择每月的1日运行,计算上个月的数据。
参数配置
为使任务自动周期运行时能动态适配环境变化,DTinsightIDE提供了参数配置的功能。
应用场景:某任务为每天调度一次,需要统计昨天的历史数据,那么可以在SQL或MR任务中添加业务日期变量,此变量需要随着系统时间而变化,即实现“今天的任务处理昨天的数据”。
1.系统参数
DTinsightIDE提供了4个系统参数,定义如下:
${bdp.system.cyctime}:一个实例的定时运行时间,默认格式为:yyyyMMddHHmmss。
${bdp.system.bizdate}:一个实例计算时对应的业务日期,业务日期默认为定时运行日期的前一天,以yyyyMMdd的格式显示。
${bdp.system.currmonth}:一个实例的定时运行时间所在的月份,默认以yyyyMM的格式显示。
${bdp.system.premonth}:一个实例的定时运行时间的上一个月,以yyyyMM的格式显示。
从定义可知,运行时间和业务日期有如下计算公式:运行时间=(业务日期+1)+定时时间。
注:若使用系统参数,无需在编辑框设置,直接在代码中引用 b d p . s y s t e m . b i z d a t e 和 {bdp.system.bizdate}和 bdp.system.bizdate和{bdp.system.cyctime}即可,系统将自动替换代码中对这两个参数的引用字段。
2.自定义参数
使用自定义参数的使用方式:需要先在代码中编辑 k e y 1 , {key1}, key1,{key2},然后在任务参数面板中输入“key1=value1 key2=value2”方可生效。
常量:直接替换的字符串或数字,例如“key1=123 key2=abc”。
变量:基于bdp.system.cyctime取值计算出的取值,例如“key1=${yyyy}”表示按bdp.system.cyctime的值取年的部分作为结果替换该参数。
变量的格式:变量的格式支持yyyyMMddHHmmss,其中MM表示月份,mm表示分钟,HH表示24小时制的小时。
常用变量参数配置列表:
后N周:yyyyMMdd+7N
前N周:yyyyMMdd-7N
后N天:yyyyMMdd+N
前N天:yyyyMMdd-N
后N小时:HHmmss+N/24
前N小时:HHmmss-N/24
后N分钟:HHmmss+N/24/60
前N分钟:HHmmss-N/24/60
依赖关系
在调度配置中,会需要配置两个任务级别的依赖:任务间依赖和跨周期依赖。
1.任务间依赖
若某任务B必须在任务A完成后运行,则A为B的上游任务,这种依赖关系可通过如下方式配置:在“上游任务”输入框,输入任务关键字,在列出的可选任务中选中某个任务,此任务被添加到上游任务列表中,即完成了A、B间的依赖关系配置。
注:一个任务可以依赖多个上游任务,同样,一个任务可被多个任务依赖。依赖属性为非必填项,当下游任务需依赖上游任务产出数据,则可配置依赖关系。
注:上游任务失败后,下游任务不会运行,但其状态会被置为失败状态。
2.跨周期依赖
配置任务的跨周期依赖,如:天调度任务中,今天需要执行的数据依赖本任务昨天执行的数据,那么可以配置依赖昨天任务的周期,这样一来,昨天的实例必须先执行成功,今天的实例才可以调度起来,这种依赖主要是体现在任务调度实例的依赖。
注:依赖属性配置的调度依赖是同周期依赖和跨周期依赖不冲突。任务A可以配置依赖属性依赖任务B,也可以配置跨周期依赖依赖B,如此任务A既依赖任务B,本周期也依赖任务B上周期。
脚本开发
脚本文件是对周期任务的补充,通常用于辅助数据开发过程,主要用于实现非周期的临时数据处理,如临时表的增删改等,因此不包含周期属性和依赖关系。
脚本文件仅支持SQL类型,并且仅支持页面直接运行生效,不支持发布,主要使用流程如下图所示:

1.新建脚本
选中左侧的脚本管理面板,点击新建脚本按钮,填写新建脚本文件弹出框中的配置,如图所示:

脚本名称:需输入英文字母、数字、下划线组成,不超过20个字符。
任务类型:目前仅支持SQL类型的脚本,不支持其他类型脚本。
存储位置:此任务在页面左侧的任务存储结构中的位置。
描述:此任务的描述,可输入长度不超过200个的任意字符。
脚本信息输入完毕后,单击确认,脚本文件创建成功。打开创建好的脚本文件,即可进行脚本编辑。
2.编辑脚本
脚本文件通常用于实现非周期的临时数据处理,如临时表的增删改,一次性的数据初始化或查询任务等。脚本编辑完成后,单击保存,下次打开网页时即可看到最近一次保存的内容。
3.运行代码
保存完毕后,可以选中部分代码单击运行。也可以不选中任何代码而直接运行,那么将运行全部代码。
4.查看日志
任务触发运行后,在编辑区下方会显示日志页,如果有语句的运行结果返回了数据集,则在日志页旁显示结果页,也支持结果下载。
无论运行几次,日志页只有一个,仅显示最近一次触发运行的日志信息,之前的日志会被覆盖。结果页可以存在多个,按语句执行顺序依次显示,最多可以显示20个结果页,方便您进行对比数据等操作。
多个语句触发执行时,这些语句将串行执行,日志内容依次显示在日志页中。结果则按每个语句的执行顺序分别显示在不同的结果页中。
5.删除脚本
右键单击选中的脚本,选择删除即可。
资源管理
如果在代码或函数中需要使用.jar等资源文件,那么需要先将资源上传至该项目的项目空间下,然后在函数中进行引用,如图所示:
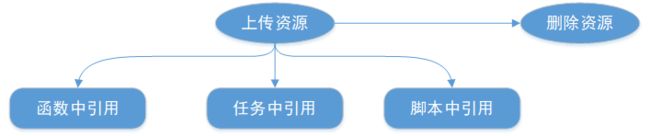
注:资源管理通常使用在UDF等自定义函数的场景中,因此可以将资源管理理解为函数管理的一个步骤。
1.上传资源
可上传jar/Python类型的资源,上传后资源会同步至DTinsightIDE中。
资源名称:需输入英文字母、数字、下划线组成,不超过20个字符。
资源类型:目前仅支持jar或Python类型的资源,不支持其他类型资源。
存储位置:此资源在页面左侧的资源管理存储结构中的位置。
描述:此资源的描述,可输入长度不超过200个的任意字符。
注:DTinsightIDE不支持批量上传资源,同时也请您注意上传资源的大小,超过100M的文件,无法上传。
2.在函数中引用资源
如果现有的系统内置函数无法满足您的需求,DTinsightIDE支持创建自定义函数,实现个性化处理逻辑。将实现逻辑的Jar包上传至项目空间下,便可在创建自定义函数的时候进行引用。
3.不支持在代码中引用资源
DTinsightIDE不支持在代码中引用资源,只支持在函数中引用资源。
4.删除资源
如果需要删除一个资源,在资源管理中右键单击该资源,选择删除即可。
注:删除资源后,引用该资源的函数或代码在运行时会报错,故请慎重操作。如有改动,尽量通知到依赖该资源的其他对象的负责人。
函数管理
1.函数的使用
目前DTinsightIDE的工作对象大部分为SQL类型的脚本和任务。在编辑SQL类型的脚本和任务的代码时,常需要使用各种函数对数据做标准化处理。
函数管理,是DTinsightIDE提供的专用于对SQL 编辑时需要的系统函数和自定义函数进行管理的功能,在此页面可以进行新建目录、新建函数的操作。
函数管理模块下显示的全部函数,无论是系统默认的还是自定义函数,仅用于SQL类型的任务和脚本。
函数的具体应用场景:

2.系统函数
系统默认提供以下几类系统函数:
1.日期函数
2.数学函数
3.字符函数
4.聚合函数
3.自定义函数
用户自定义函数(User Defined Function,简称 UDF),是用户除了使用 DTinsightIDE提供的内建函数外,自行创建的函数,用于满足个性化的计算需求。自定义函数在使用上与普通的内建函数类似。
创建自定义函数流程:

具体操作步骤:
- 在本地编写代码并编译为Jar包
在本地Java环境中按照Spark的UDF框架编写Java代码实现函数,本示例的代码如下所示
将以上代码编译成Jar包。import org.apache.hadoop.hive.ql.exec.UDF; public class HelloUDF extends UDF{ public String evaluate(String str){ try{ return "helloWorld" + str; }catch (Exception e){ return null; } } } - 上传资源到DTinsightIDE
在任务开发模块,点击左侧的资源管理面板并上传资源文件。在目录树中选择一个文件夹,然后右键选择上传资源。
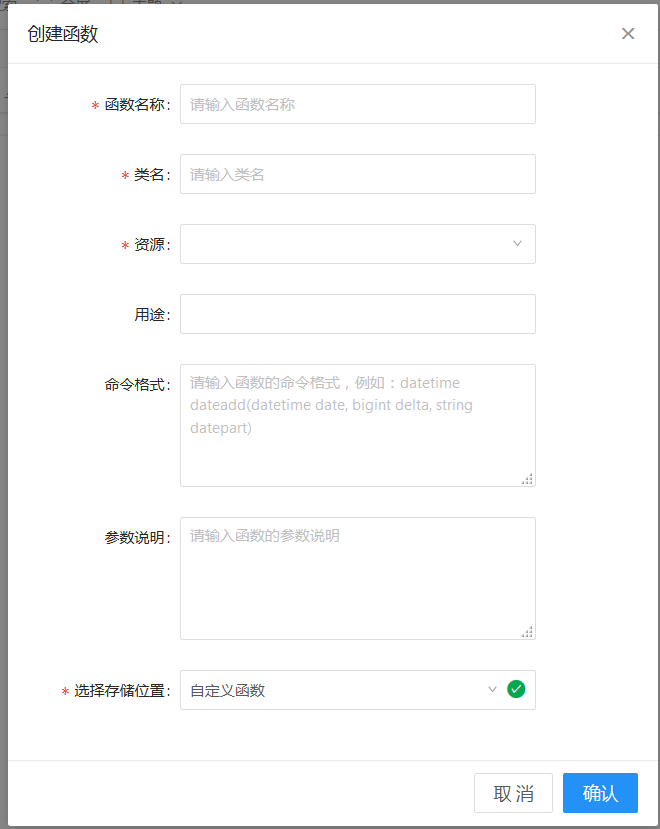
填写资源上传弹出框中的各配置项,提交后资源创建成功。 - 新建自定义函数并引用资源
进入DTinsightIDE的数据开发模块,打开左侧的函数管理面板。在目录树中选择一个文件夹,然后右键选择新建函数,填写弹出框中的各配置项。
- 在SQL任务或脚本中使用函数
4.查看函数
单击函数名,可以查看函数的类型、命令格式以及参数说明,如下图所示:

5.删除函数
在函数管理页面找到需要删除的函数,右键单击,在菜单栏选择删除,即可删除该函数。仅自定义函数可以被删除,系统函数无法被删除。
导入本地数据
DTinsightIDE支持将保存在本地的文本文件中的数据上传到项目空间的表中。
本地文本文件上传的限制如下:
- 文件类型:仅支持.txt、.csv和.log格式。
- 文件大小:不超过100M。
- 操作对象:导入分区表时,分区不允许为中文。
操作步骤
1.单击导入,选择导入本地数据。
2.选择本地数据文件,配置导入信息,单击下一步。
3.如果导入数据的表已存在,搜索表名即可。
4.如果没有创建导入数据的表,则可以单击去新建表,输入建表语句后,单击确认。
5.选择导入数据的表名后,选择字段匹配方式(按位置匹配或按名称匹配)。选择按位置匹配以后,如果是分区表,则会提示分区的选择,同时可以点击检测按钮,测试分区是否存在,检测后单击导入。