特征工程:转换器与估计器,估计器的工作原理
目录
1.转换器与估计器
1_当转换器与估计器输入数据集不一致时
2_当省略估计器时会报错
3_其他估计器的API接口
4_估计器的工作流程
参考文章
1.转换器与估计器
fit_transform()这个函数实际分为两步
fit():估计器,输入数据集后,先计算平均值,方差,标准差。
transform():只有估计器工作后,才能进行数据转换
1_当转换器与估计器输入数据集不一致时
值得注意的是,当数估计器和转换器的输入数据集不一样时,转换器会以估计器输入的数据集来计算平均值和标准差,从而导致输出结果出问题。所以分步执行时,一定要确保估计器与转换器的输入数据集一致。
from sklearn.preprocessing import StandardScaler
st=StandardScaler()
st.fit([[7,8,9],[10,11,12]])
data=st.transform([[1,2,3],[4,5,6]])
data2=st.fit_transform([[1,2,3],[4,5,6]])
print("转换器与估计器输入值不一致\n",data)
print("转换器与估计器输入值一致\n",data2)可以看到输出结果为:
转换器与估计器输入值不一致
[[-5. -5. -5.]
[-3. -3. -3.]]
转换器与估计器输入值一致
[[-1. -1. -1.]
[ 1. 1. 1.]]
2_当省略估计器时会报错
注释掉st.fit([[1,2,3],[4,5,6]]),看看不使用估计器的结果
sklearn.exceptions.NotFittedError: This StandardScaler instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
3_其他估计器的API接口
在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
sklearn 估计器是进行机器学习的面向对象
1_用于分类的估计器:
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
- sklearn.tree 决策树与随机森林
2_用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
3_用于无监督学习的估计器`x
- sklearn.cluster.KMeans 聚类
用法示例
from sklearn.neighbors import KNeighborsClassifier ba= KNeighborsClassifier #x_train是数据集,y_train是目标值 ba.fit(x_train,y_train)
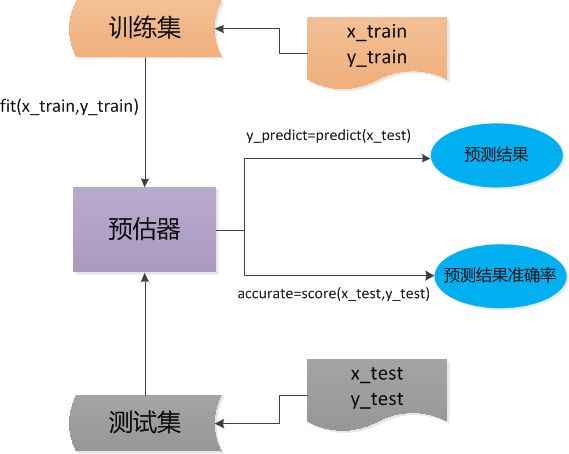
4_估计器的工作流程
如图所示,x_train数据集,y_train目标值作为输入,调给fit()估计器,建立模型(模型=数据+目标值)。
经过数据训练(下图中没有体现)后,得到可用的数据模型。
既然数据模型已经建立,就需要一组测试集来做验证,这里是x_test(数据集)和y_test(目标值),这里面的工作方式是,通过训练集生成的模型,对测试集进行目标值预测,输出预测结果(目标值)。
然后拿输入的y_test(真实目标值)与预测结果比对,通常较为score值,当score值较大时(1代表100%),预测结果越准。
当socre值较小时,我们就要加大训练集的数量或者调整算法参数,甚至更换算法,以此来提高预测准确度。
参考文章
机器学习之转换器和估计器https://blog.csdn.net/Charles_TheGod/article/details/84382944
转换器和估计器https://www.cnblogs.com/shenjianping/p/12952104.html