微服务架构 实时流架构
物联网的现代开源复杂事件处理
这个系列的博客文章详细介绍了我的发现,因为我将复杂事件处理(简称CEP)的完整形式带入了生产。 在从财务到零售和物联网应用的许多应用中,自动化需要实时采取行动的任务的巨大价值。 撇开支持该功能的IT系统和框架,这显然是有用的功能。
在本系列的第一篇文章中 ,我将解释CEP如何满足此要求,以及如何在现代大数据环境中满足CEP的要求。 简而言之,我提出了一种基于现代体系结构,微服务和Kafka式流消息传递的最佳实践的方法,以及一个最新的开源业务规则引擎。
在第二部分中,我将更加具体,并使用我建议的系统通过一个工作示例进行工作。 让我们开始吧。
智慧城市交通监控
我们制作了一个工作演示,其代码将在MapR GitHub上发布。 它可以在MapR沙箱上运行,也可以使用真实的MapR集群运行。 我们的演示计划发布,因此请继续关注并检查www.mapr.com的最新消息。
在此示例中,我们将使用一个非常简单的“智能城市”用例进行流量监控。 在这种情况下,我们将对单个传感器建模,该传感器可以测量通过它的汽车的速度。 使用这样的传感器数据,实时检测交通拥堵将非常容易,从而可以比其他情况更快地通知警察采取行动。
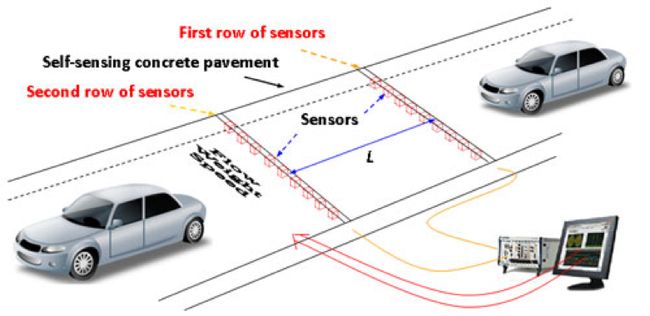
其他一些类型的用例很容易设想。 我们可以从公共的实时天气反馈中添加数据,并连接到道路上的信息面板,并在无需任何人工干预的情况下为驾驶员提供建议。 通过将道路状况传感器与天气数据相结合,我们可以向驾驶员提供有关道路状况的咨询反馈,并Swift警告公众。 此外,通过添加历史事故数据并使用预测分析,我们可以想象道路安全措施可以实时部署到发生事故可能性更高的区域。
老实说,我只是在摸索这种智慧之路可以做些什么,以使通勤者的生活更轻松,更安全,同时又为城市省钱。 但是,如何在不使系统变得极其复杂和昂贵的情况下构建这种系统的原型呢?
如何构建基于规则引擎的CEP系统
因此,我们现在有一个适当的具体目标。 事实证明,如果我们决定以从Kafka风格的流(即持久性,可伸缩性和高性能)中读取数据为基础来构建系统,那么我们自然会得到一个非常酷的现代CEP微服务。
这里的重点不是要显示如何构建超级复杂的企业体系结构,而是要通过选择一些简单的技术并以合理的方式构建我们的演示,我们自然就可以得到这种优雅,现代且简单的体系结构 。
为简单起见,我决定在MapR沙箱上实现我的原型( 在此处免费获得 )。 这是因为它将包括流消息传递系统MapR Streams,我只需很少的配置就可以通过Kafka 0.9 API使用它,并且知道它在生产MapR 5.1+集群上也可以使用。
最后,应该注意的是,Apache Kafka集群也可以使用相同的设计和代码,仅需进行一些额外的工作即可启动并运行。
高级架构视图

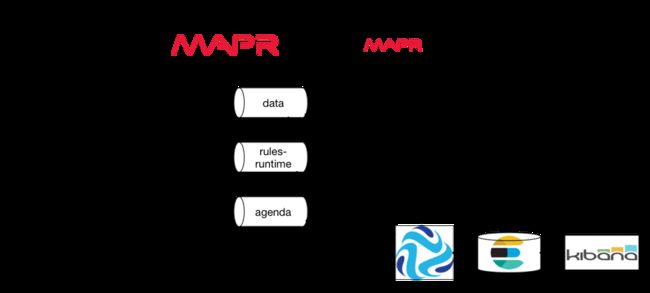
如上图所示,该流程是将传感器数据汇总到生产者网关,该生产者网关会将数据转发到主题为“ data”的流。 数据将采用JSON格式,因此易于操作,易于阅读,并且可以按原样轻松发送到Elasticsearch以使用Kibana仪表板进行监视。
消费者方将执行两项任务:从流中读取数据并托管KieSession的实例,规则引擎可以在将事实添加到事实时将规则应用于事实。
在Workbench GUI(一个Java Web应用程序)中编辑规则,该Web应用程序可以在Java应用程序服务器(如WildFly或Tomcat)上运行 。
消费者应用程序使用Drools框架提供的适当方法从工作台中获取规则,这些方法完全基于Maven存储库。
现在,我们可以在以下各节中更详细地研究所提议的系统。
使用的技术清单
我们将要使用的技术如下:
- MapR沙盒5.2
- Java编程语言(任何JVM语言都可以)
-
Jackson 2库与JSON相互转换
- MapR Streams或Apache Kafka流消息传递系统
- Wildfly 10应用程序服务器托管工作台
- JBoss Drools作为我们选择的OSS业务规则引擎
- Log Synth为我们的原型生成一些综合数据
- Streamsets 1.6连接MapR流和Elasticsearch
- 用于监控的Elasticsearch 2.4和Kibana 4
交通监控原型架构
当我构建此演示以便在MapR沙盒上运行时,我正在使用CentOS 6.X(RHEL 6.X的开源版本)的说明。 CentOS 7的说明几乎相同,而为Ubuntu找到类似的说明将非常简单,并留给读者。
要构建交通监控系统的核心,我们将需要两个基本部分:
- 将传感器数据输入到MapR Streams / Kafka中的程序。 这部分将使用由Log Synth编码的车辆模拟模型建模的伪造数据。 我们将使用MapR Kafka-rest代理实现(仅在MEP 2.0中引入)来通过Python添加数据。
- 一个JVM语言应用程序,它将从流中读取数据并将其传递给KieSession。 使此工作正常的最少代码非常少。
要编辑规则,我们在Wildfly 10上部署工作台,这是一个相当简单的过程。 查看此博客文章以获取说明,或阅读Drools文档。 安装Wildfly非常简单; 有关如何在Centos / RHEL上将其作为服务安装的重要说明, 请参见此博客 (适用于Wildfly,但相同的说明适用于9和10)。
我们对Wildfly进行了单个配置更改。 我们将端口更改为28080,而不是8080,因为沙箱已经使用了该端口。 Wildfly以独立模式运行,因此配置文件位于WILDFLY_HOME / standalone / configuration / standalone.xml中。
为了进行监视,我们让流式体系结构为我们工作。 我们使用开源的Streamset数据收集器轻松地将传感器数据重定向到Elasticsearch,以便我们实际上可以使用带有Kibana的漂亮仪表板监视系统。 要使用MapR Streams设置Streamset,需要对1.6版进行一些工作( 有关此版本的出色博客文章 ,或来自Streamsets官方文档 )。
最后, 在Centos / RHEL上详细记录了Elasticsearch和Kibana的安装和设置。
对于生产而言,所有这些部分都可以轻松分离以在单独的服务器上运行。 它们可以在群集节点或边缘节点上运行。 如果是MapR集群,则安装MapR Client并将其指向集群CLDB节点将是对流进行完全访问所需的所有配置。 对于Apache Kafka集群,请参阅官方Kafka文档 。
交通监控原型–如何
使用maprcli创建流
第一个任务是为我们的应用程序创建流和主题。 为此,最佳做法是首先为流创建一个卷。 作为用户映射器,从命令行键入:
maprcli volume create -name streams -path /streams
maprcli stream create -path /streams/traffic -produceperm p -consumerperm p
maprcli stream topic create -path /streams/traffic -topic data
maprcli stream topic create -path /streams/traffic -topic agenda
maprcli stream topic create -path /streams/traffic -topic rule-runtime注意:MapR Streams更像是Kafka的超集,而不仅仅是一个克隆。 除了更快之外,MapR Streams还可以利用MapR File System的所有优点 ,例如卷(具有权限和配额等)和复制。 集群不仅限于定义主题,还可以定义多个流,每个流可以具有多个主题。 因此,MapR流具有path:topic符号,而不是主题名称。 在这里,我们的数据流的全名是“ / streams / traffic:data”。 您可以在Jim Scott的白板演练中详细了解MapR Streams与Kafka的优势。
生成伪数据
我使用了Log-Synth工具为该原型生成数据。 Log-Synth使用架构与Sampler类结合使用,以非常灵活和简单的方式生成数据。
我的架构:
[
{"name":"traffic", "class":"cars", "speed": "70 kph", "variance": "10 kph", "arrival": "25/min", "sensors": {"locations":[1, 2, 3, 4, 5, 6, 7,8,9,10], "unit":"km"},
"slowdown":[{"speed":"11 kph", "location":"2.9 km - 5.1 km", "time": "5min - 60min"}]}
]生成数据的命令是:
synth -count 10K -schema my-schema.json >> output.json一次生成一辆车的数据,每个数据点都是传感器的读数。 该数据将模拟以70公里/小时的速度行驶的汽车流量,达到每分钟25辆汽车的速度。 在模拟开始后5分钟到60分钟之间,速度会在2.9至5.1公里之间减速,速度会降至11公里/小时。 这将是我们希望使用CEP系统检测到的交通堵塞。
生成的数据是一个文件,其中每一行是单个汽车的传感器测量结果列表:
[{"id":"s01-b648b87c-848d131","time":52.565782936267404,"speed":19.62484385513174},{"id":"s02-4ec04b36-2dc4a6c0","time":103.5216023752337,"speed":19.62484385513174},{"id":"s03-e06eb821-cda86389","time":154.4774218142,"speed":19.62484385513174},{"id":"s04-c44b23f0-3f3e0b9e","time":205.43324125316627,"speed":19.62484385513174},{"id":"s05-f57b9004-9f884721","time":256.38906069213255,"speed":19.62484385513174},{"id":"s06-567ebda7-f3d1013b","time":307.3448801310988,"speed":19.62484385513174},{"id":"s07-3dd6ca94-81ca8132","time":358.3006995700651,"speed":19.62484385513174},{"id":"s08-2d1ca66f-65696817","time":409.25651900903136,"speed":19.62484385513174},{"id":"s09-d3eded13-cf6294d6","time":460.21233844799764,"speed":19.62484385513174},{"id":"s0a-1cbe97e8-3fc279c0","time":511.1681578869639,"speed":19.62484385513174}]读数具有传感器ID,以米/秒为单位的速度以及从时间0(模拟开始的时刻)到秒的时间增量。
我的生产者代码只是将读数转换为按时间排序的传感器读数列表,然后将速度转换为km / s,将时间转换为时间戳(以毫秒为单位)。
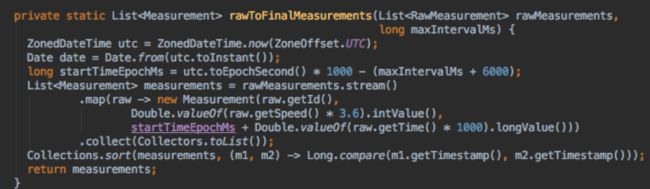
使用标准生产者代码可以一次将代码发送到流中。 示例Java生产者中的代码可以正常工作。
另一个令人兴奋的新可能性是使用全新的Kafka Rest Proxy ,该代理 也可以从MEP 2.0(MapR Ecosystem Pack)的MapR中获得。 由于基于HTTP的REST API是全球标准,因此这意味着传感器可以从任何语言直接连接到Kafka。
使用工作台
我们可以登录到工作台,并使用由Wildfly的add-user.sh脚本创建的admin用户(角色为“ admin”的用户)登录。
使用工作台不在本文讨论范围之内,但是总体思路是创建一个组织单位和一个存储库,然后创建一个项目。
数据对象
我们将需要创建事实以供规则引擎使用。 Drools的最佳实践是为数据模型使用单独的Maven项目。 为了简单起见,我直接在工作台上创建了它们。

Measurement是一个超级通用bean,可对传感器速度测量进行建模。 对于原型,我将其与带有时间戳,传感器ID和速度的原始数据一样简单。
森 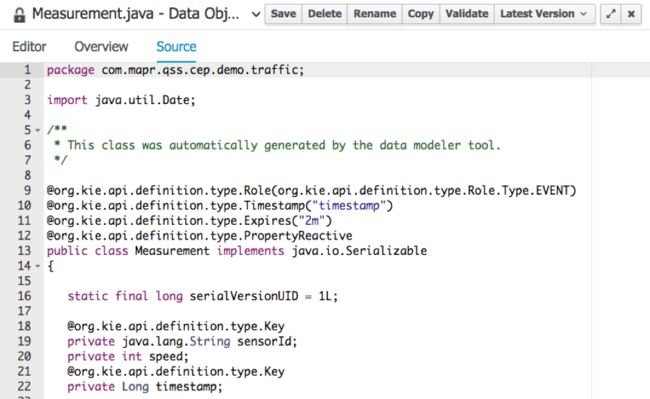 sor bean对传感器本身进行建模,并在我们的规则定义的时间范围内,具有ID和它测量的所有汽车的平均速度。 该平均速度将用于触发交通繁忙警报。 流量字符串用于标记当前的流量级别,可以为“ NONE”,“ LIGHT”或“ HEAVY”。
sor bean对传感器本身进行建模,并在我们的规则定义的时间范围内,具有ID和它测量的所有汽车的平均速度。 该平均速度将用于触发交通繁忙警报。 流量字符串用于标记当前的流量级别,可以为“ NONE”,“ LIGHT”或“ HEAVY”。
 流量监控规则
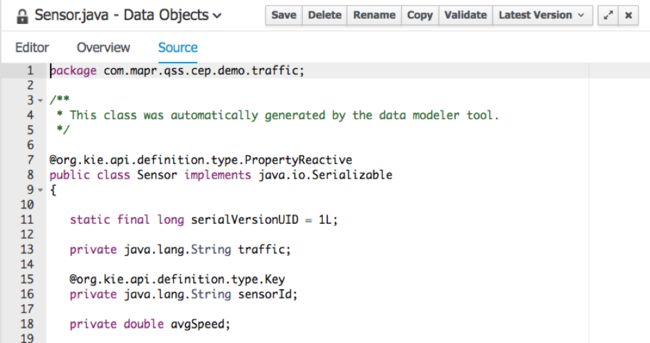
流量监控规则
- 为新ID创建传感器
- 检测交通繁忙
- 检测交通流量
- 检测正常流量
- 获得传感器的平均速度
创建传感器规则可确保内存中有可用的传感器对象。 这就是我们用来了解某个传感器的平均速度的事实。
如果在某个传感器上检测到交通繁忙,检测交通繁忙是我们要用来向警察发送警报的关键规则。
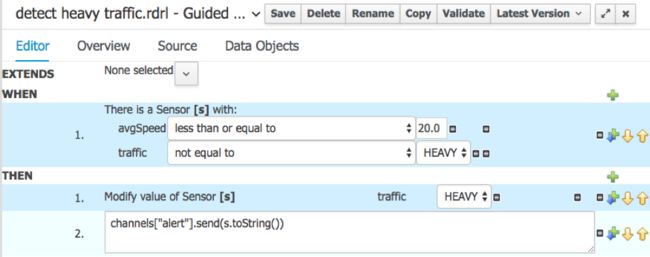
因此,当平均速度达到或低于20 km / h,并且传感器尚未处于HEAVY交通级别时,请将级别设置为HEAVY并发送警报。
这意味着我们需要知道平均速度。 这是使用Drools规则DSL(域特定语言)进行计算的规则:
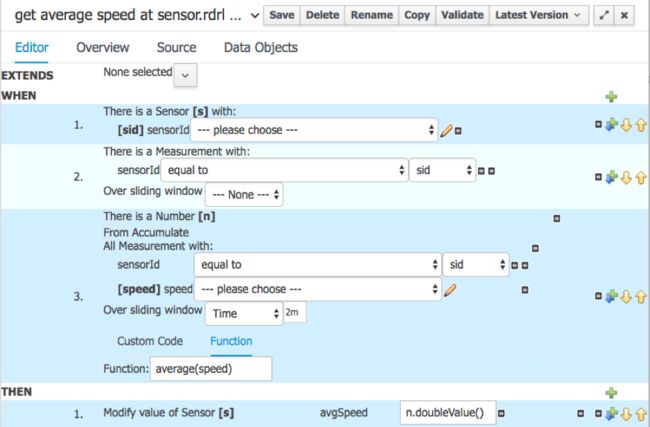
这不是航天科技! 这些规则非常清楚地说明了如何简单地将简单但有用的规则留给业务分析师,并与整个流和大数据平台分开开发。
消费者方
使用者从流中读取数据。 文档中的Java教程代码就足够了。 Jackson用于将JSON转换为Measurement对象。
使用者有一个KieSession实例,并使用kieSession.insert(fact)将每个度量添加到会话中,然后调用kieSession.fireAllRules(),这将触发算法检查是否有任何规则与新状态匹配指定新数据的会话中的。
通道只是一个回调,用于允许规则在KieSession的“外部”调用函数。 我的原型使用此方法记录警报。 在生产系统中,我们可以轻松地更改代码以发送电子邮件,SMS或采取其他措施。
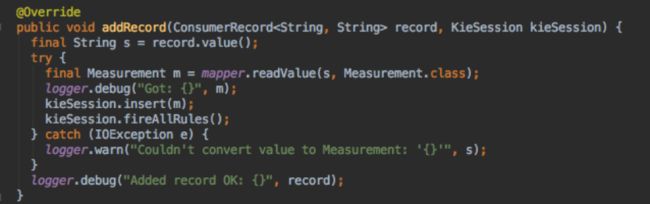
将规则导入消费者应用程序
我们从正在运行的应用程序中获取规则的方法是从集成到工作台的Maven存储库中获取规则。
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.mapr.demo", "smart-traffic-kjar", "1.0.0" );
KieContainer kContainer = kieServices.newKieContainer( releaseId );
KieSession kieSession = kContainer.newKieSession();因此问题就变成了,对newReleaseId的调用如何知道如何使用我们的规则从工作台中的Maven存储库中获取工件?
答案是〜/ .m2 / settings.xml文件,您可以在其中添加此信息。 我们建议对沙箱中的所有内容使用用户映射器,因此完整路径为:/home/mapr/.m2/settings.xml
[mapr@maprdemo .m2]$ cat settings.xml
guvnor-m2-repo
admin
admin
cep
guvnor-m2-repo
Guvnor M2 Repo
http://127.0.0.1:28080/drools-wb-webapp/maven2/
true
interval:1
true
interval:1
cep
关键信息以粗体显示,对应于Drools工作台的maven2存储库的URL。 可以从pom.xml复制和粘贴此信息,可以使用存储库视图看到该信息:


所以我只是复制粘贴了该内容,现在一切都像魔术一样工作。
监控智能流量原型
我们有一个包含数据的流,另外两个具有监视规则引擎内部的流。 对于Drools来说,这非常容易,因为它使用Java侦听器报告其内部状态。 我们仅提供侦听器的自定义实现以将数据生成到流,然后使用Streamsets将所有人重定向到Elasticsearch。
Elasticsearch映射
映射是在我创建的一个小脚本中定义的:
http://pastebin.com/kRCbvAkU
无代码流到Elasticsearch管道的流集
每个流都有自己的管道,每个管道如下所示:
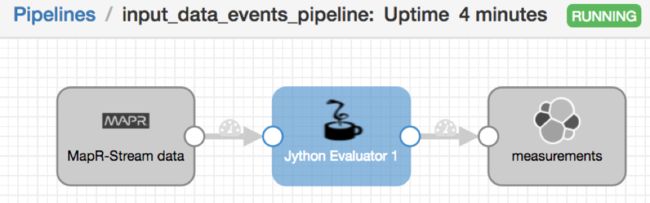
如果需要,Jython评估器会添加时间戳信息。
运行原型
启动消费者:

然后启动生产者:

在我的原型中,我添加了代码来控制将数据发送到流的速率,以使规则触发更容易看到。 对于Drools和MapR Streams / Kafka而言,10,000个事件非常小,因此整个演示将在不到一秒钟的时间内完成。 这就是每秒25个事件的“ -r 25”的含义。
仪表板如下所示:
一旦数据开始流式传输:
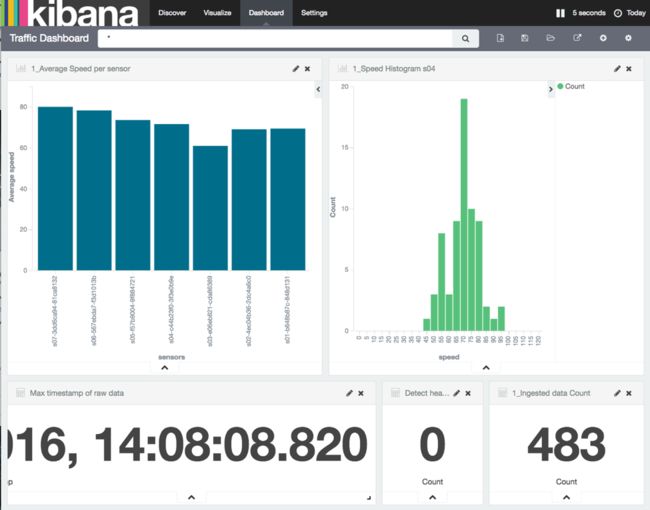
现在交通堵塞非常明显:
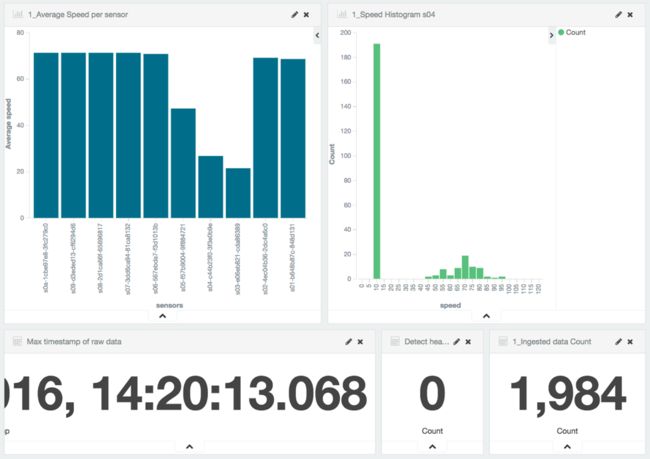
传感器平均速度下降到20 km / h以下时,就会发出警报:

并且仪表板将显示为“ 1”

模拟将继续,另外两个传感器将依次降到20以下,总共触发3个警报。
结论
这个项目很好地说明了使用微服务的流式架构的强大功能和便捷性。 对微服务的一个普遍误解是它们仅限于同步REST服务。 根本不是这种情况。 我们的系统是一个后端系统,因此微服务(生产者,消费者,流集和ES / Kibana)都是异步运行的,并在流中处理数据。
该项目在技术上相当容易构建,因为每个部分都完全独立于其他部分,因此可以单独进行测试。 生产者可以正确地将数据发送到流后,就不必再对涉及系统其他部分的问题进行测试。 此外,每个零件一次都添加了一个,可以轻松地发现问题并加以解决。
总体而言,只需很少的原始代码,我们就可以实现一个有用的,有用的系统,只需很少的更改即可投入生产。 仅生产者需要针对特定传感器或数据源进行定制。
规则是最耗时且容易出错的部分。 这与使用自定义编码的Spark代码完成项目没有什么不同。 基于规则引擎(例如Drools和Drools Workbench)的方法的优势在于,可以独立于集群上的代码运行方式来编辑,测试和改进规则。 Workbench中的工作完全不依赖于系统,因为它由使用者应用程序自动引入。
从业务价值的角度来看,假设稳定的生产系统,所有价值都在规则中。 组织没有理由不利用这种快速编辑功能来变得更加敏捷和对不断发展的条件做出响应,以使客户和公司受益。
翻译自: https://www.javacodegeeks.com/2017/01/real-time-smart-city-traffic-monitoring-using-microservices-based-streaming-architecture-part-2.html
微服务架构 实时流架构