prcesssor在运行时,假设program counter的值为a0, a1, ... , an-1,每个ak表示相对应的instruction的地址。从ak到ak+1的变化被称为control transfer。一系列的control transfers被称为control flow。
exceptions是指一些event,这些event表明当前的system、processor或executing program存在某些状况(详见1.2)。exceptions会导致control flow的突变,典型的就是将控制从当前运行的程序或任务转移到exception handler的执行(详见1.1节)。在计算机程序中,我们设计了jump和branch,call和return;他们通过program state的变化,引起了control flow的突变。exceptions中的control flow的突变是通过system state的变化来引发的,这种control flow的突变被称为exception control flow。interrupt作为exceptions的一种,当由I/O devices complete引发interrupt后,I/O devices通过pin的变化给processor发送signal,并将exception number放到system bus上,processor接收到signal并从system bus上获取到exception number,然后将控制转移到exception handler中[1][2][3]。exception control flow除了应用于在exceptions中,也应用于signal(见第4节)、context switch(见2.3节)和setjump中(见第5节)。
1.exceptions
1.1 exceptions从产生到处理的流程
exceptions作为exception control flow的一种,它从产生到处理的流程由processor和operate system共同实现的。exceptions的流程中processor和operate system分别执行了哪些工作容易使人困惑。exceptions可以由当前正在执行的instruction而产生,也可以由I/O devices等外部原因而产生,由外部原因产生的异常也被称为external interrupt。exceptions在产生时,会出现processor state的变化,同时会生成exception number。对于external interrupt和其它的exception,exception number的产生机制不同。当处理器感知到processor state的变化,就会将控制转移到exception handler的执行(类似于call procedure)。exception handler是根据exception number去exception table中匹配到的,exception table的地址存储在register中。
1.1.1生成exception number
intel 64和IA-32的架构为每个processor-detectable exception(包括faults,traps和aborts)定义了一个exception number。对于external interrupt,当local APIC(Advanced Programmable Interrupt Controller )启用时,exception number由I/O APIC决定,并通过LINT[1:0] pin 告诉processor异常发生了。当local APIC关闭时,exception number由external interrupt controller 决定,并通过INTR/NMI pin 告诉processor异常发生了[2]。
1.1.2exception handling
如图1所示,Interrupt descriptor table(IDT) 将每个exception number(图1中为Interrupt Vector)和用于定位exception handler(图1中为interrupt procedure)的gate descriptor关联起来。图1适用于IDT为interrupt/trap gate的情况[2]。gate中的segment selector指向GDT/LDT中的segment descriptor,segment descriptor指向Destination code segment。gate中的offset指向了exception handler(图1中为interrupt procedure)的起始地址。
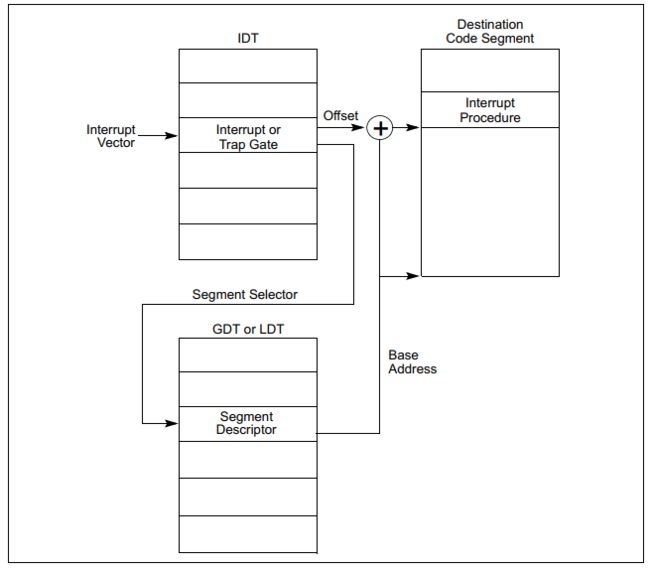
图1 interrupt procedure call(也称为exception handler call)
IDT可以存在于linear address space的任何位置。如图2所示,IA32 processor(IA32e与其相似,只是每个gate for interrupt的大小为16bytes)使用IDRT register定位IDT。IDRT register包含32-bit的base address和16-bit的IDT limit[2]。
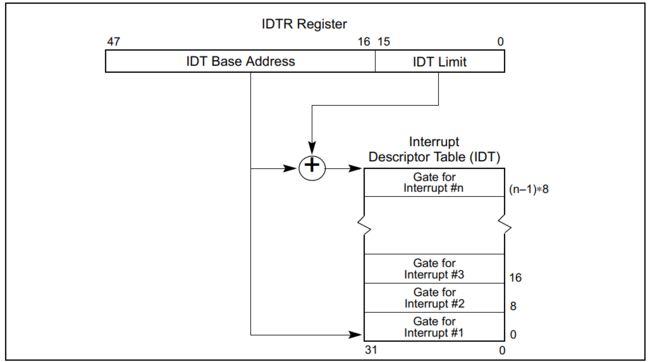
图2 IDTR和IDT的关系
1.1.3 return from exception handler
当IA32e processor发起对exception handler的调用时,且没有stack switch的情况下,IA-32e mode 加载一些变量到当前栈中,如图3所示[2]。IA-32 mode会按顺序保存SS和RSP到当前栈中;保存当前的RFLAGS;保存CS和RIP到当前栈中;如果exceptions发生时有保存error code,error code也会保存到当前栈中。CS(code segment selector)和RIP表示return address,指向faulting instruction的位置。SS(stack segment selector)和RSP指向interrupted procedure的位置。当exception handler执行结束时,会执行IRET instruction从当前的异常处理程序返回,IRET instruction与RET intruction的执行类似。当程序返回时,有下面三种情况:1)返回到当前faultiong instruction的位置Icurr(参考图4);2)返回到faulting instrution的下一条指令Inext;3)退出intrrupted program。
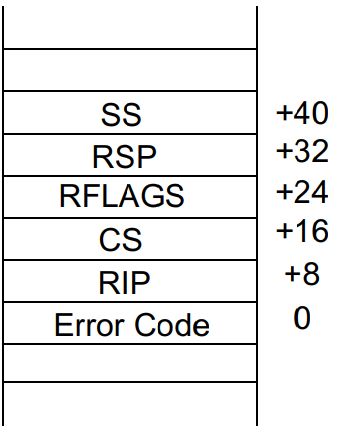
图3 Interrupted Procedures and Handlers Stack
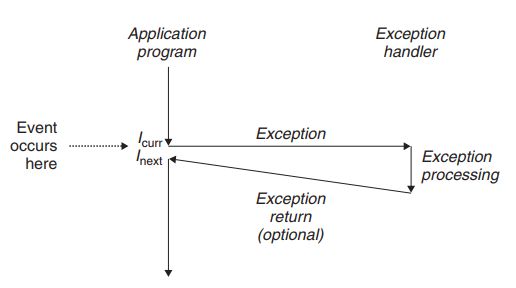
图4 Anatomy of an exception
1.2 exceptions的分类
exceptions可分为四类:interrupt、trap、fault和abort。图5中的表格总结了这四类exceptions的一些特性,可以看出它们在cause和return behavior上区别。另外,它们的exception handler也各不相同。

图5 exceptionsd的分类
1.2.1 interrupt
interrupt由I/O devices引起的,不是由当前指令的执行而导致的,它是异步的。像network adapters、disk controllers 和timer chips等I/O devices,它们通过pin的变化告知processor异常发生了,并将exception number 放到system bus上。异步的异常发生时,会先执行完当前instuction,然后才会做出对异常的反应。当processor感知到interrupt pin走高时,他从system bus中获取exception number,然后将控制转移到合适的interrupt handler。当从interrupt handler返回时,会返回到interrupt发生时执行指令的下一条指令Inext。
1.2.2 trap 和system calls
User programs在执行read、fork、execve和exit等函数时,需要kernel中的services提供支持。为了能访问到kernel中的service,processor提供了syscall instruction。当syscall instruction执行时,会将控制转移到exception handler的执行,exception handler先解析参数,然后依据参数调用对应的kernel routine。当从exception handler返回时,会返回到syscall指令的下一条指令Inext。当Unix的系统级函数遇到error时,他会返回-1并设置全局变量errno。
图6列出了几种常见的system call的函数,每个函数表示一种system call。每一种system call都与唯一的number对应,number表示在kernel中相对于jump table的offset(注意jump table与exception table 不同)。不同的类型的system call在进行syscall(汇编指令)之前,会将number存储到参数(比如%rax)中。下图中的write和_exit函数在编译后的汇编代码如图7所示,write和_exit对应的number分别为1和60,这些number在syscall指令前存储到%rax中。

图6 在x86-64系统中常见的system calls
int main() { write(1,"hello,world\n",13); _exit(0); }
.section .data string: .ascii "hello, world\n" string_end: .equ len, string_end - string .section .text .globl main main: First, call write(1, "hello, world\n", 13) movq $1, %rax write is system call 1 movq $1, %rdi Arg1:stdout has descriptor 1 movq $string, %rsi Arg2: hello world string movq $len, %rdx Arg3: string length syscall Make the system call
Next, call _exit(0) movq $60, %rax _exit is system call 60 movq $0, %rdi Arg1: exit status is 0 syscall Make the system call
图7 syscall的示例代码(文件位置code/ecf/hello-asm64.sa)
1.2.3 fault
Faults通常是可以纠正的异常,异常纠正后中断的程序会继续执行。由于当前instruction执行引发fault时,processor会先将machine state恢复到该instuction执行前的状态;然后开始执行fault hander。当从fault handler返回时,如果异常得到纠正时则返回到当前执行instruction Icurr;否则返回到abort routine中,使程序终止。
page fault exception是fault的典型例子,它发生在当virtual address所在virtual page没有对应的physical page时。fault handler会在physical memory中选择victim page作为新的对应的physical page,然后重新执行fault insrtuction(详见Chapter9 3.1)。★★引用链接
1.2.4 abort
abort指不能恢复的fetal errors,比如在DRAM或SRAM崩溃是发生的parity errors等hardware error。abort handler从不会返回到当前执行的程序并继续执行;它会返回到abort routine中,abort routine会终止程序。
2.process的概念
process指当一个正在执行的程序实例。每个程序运行在process的context中。context包括程序运行需要的state,比如code and data、stack、register、program counter、environment variable和open file descriptor等。当一个程序运行时,shell会创建一个新的process,然后加载并运行executable object file。prrocess的context可以抽象为两个部分:1)An indepent logical control flow;2)A private address space。
An independent logical control flow是一个抽象概念,它表示在某一特定时刻,一个process中运行的程序对processor是独享的。一个程序运行时的PC序列被称为logical control flow。如图8所示,processor的control flow被分成3个logical flow,它们分别被process A、B和C占有。这3个logical flow是交叉轮流执行的,如图Process A先执行,紧接着process B执行,然后processC执行,再然后processA执行,最后process C执行。如果两个precess的logic flow有交叉(比如A-B-A),我们认为A、B是并发的。如果两个logic flow在不同的processor上并发的运行,我们称它们是并行的。如图8,A和B、A和C是并发执行的。
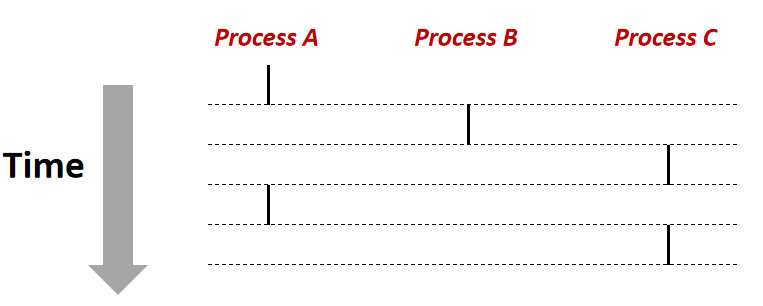
图8 logic control flows
A private address space也是一个抽象概念,它表示每个process在硬盘上的virtual address space是私有的(见第8章★★)。图9展示了virtual address space的结构。address space的上部分是为kernel保留的,它包含kernel在执行时所需的code、data、heap和stack。address space的下部分是为user program保留的,它包含code、data、heap和stack等部分。code部分的起始地址为0x400000。
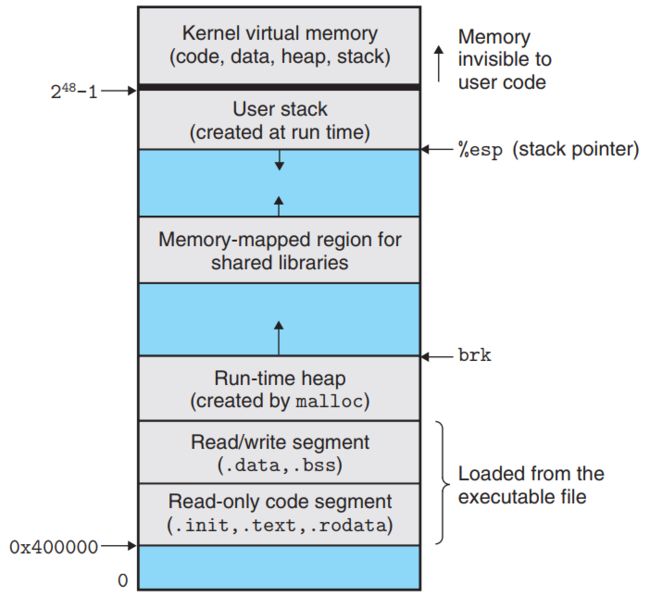
图9 process address space
2.1User and Kernel Modes
为了给operation system kernel提供封闭的process abstraction,我们将process分为user mode和kernel mode,它们具有不同的权限。kernel mode可以执行任何指令,访问内存的任何位置;user mode不能执行像halt a processor,change the mode bit或者initiate the I/O operations,也不能访问address space中的kernel virtual memory区域。mode的切换是通过某些control register中的mode bit进行控制的。当mode bit设置时,process处于kernel mode;当mode bit未设置时,process处于user mode。由user mode切换到kernel mode的唯一方式是通过interrupt、trap、fault和abort等exceptions。当exceptions发生时,控制转移到exception hander,同时process由user mode切换到kernel mode;当从exception handler返回时,process再由kernel mode切换user mode。在user mode下,可以通过system call的方式间接访问kernel code and data。
Linux提供/proc文件系统,可以在user mode下访问kernel data structures。 比如,通过/proc/cpuinfo可以或取CPU型号,通过/proc/process-id/maps可以获取某个进程的memeory segments。在2.6版本中提供了/sys filesystem,可以导出关于system buses和system devices的信息。
2.2 context switch
进程间的切换就是一个进程被抢占,另一个之前被抢占的进程开始执行,进程调度由kernel中的scheduler来决定。当processor在多个进程间切换时,会发生context switch。context switch基于exception机制实现的,它也是exception control flow的一种。kernel为每个进程维护一个context。context switch包含3个步骤:1)保存当前进程的context;2)还原之前被抢占进程的context;3)给予新还原的进程控制权。
如图10所示,刚开始process A在user mode下执行,当执行到read函数时,会发起system call,将控制转移到kernel mode下的trap handler。trap handler通过DMA将disk的文件读取到memory中,这个过程比较耗时(大约几十毫秒)。此时,kernel中scheduler会进行context switch,由processA切换到processB,然后processB在user mode下执行。当disk controller将文件从disk读取到memeory后,会引发interrupt。此时,kernel中scheduler会进行context switch,由process B切换到processA,然后process A在user mode下执行。★★★是否进入到interrupt handler。
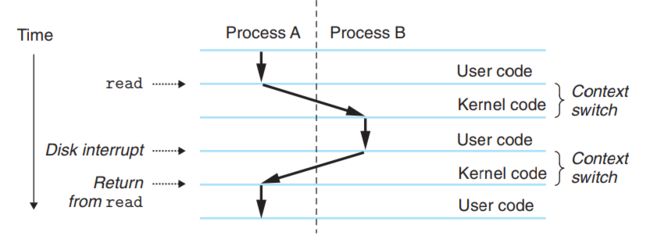 、
、
图10 剖析进程context switch
3.Process Control
C程序中有许多对进程进行的操作的函数,它们是基于Unix为C程序提供的system calls的。比如,我们可以通过getpid获取当前执行进程的process ID,通过getppid获取当前执行进程的父进程的process ID。
#include#include pid_t getpid(void); pid_t getppid(void);
进程的状态可以分为running、stopped和terminated。running指process当前正在执行或者等待被kernel调度执行。stopped指进程暂停,不会被kernel调度,当running进程接收到SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU signal时,进程变为stopped;当stopped进程接收到SIGCONT,进程变为running。terminated指进程永久停止,主要有3种情况:1)接收终止进程的signal;2)从main任务返回;3)调用exit函数。
#includevoid exit(int status);
可以通过sleep函数让进程暂停指定的时间。当sleep的时间到达后,函数返回0,进程变为running;当在sleep过程中,如果进程接收到signal,则sleep会提前中断,函数返回剩余的时间。也可以通过pause函数来暂停进程,进程只有在接收到signal时才会变为running,函数总是返回-1。
#includeunsigned int sleep(unsigned int secs);
#includeint pause(void);
3.1 fork
一个父进程可以通过调用fork函数创建一个running的子进程。如图11所示,通过fork创建子进程,子进程将父进程的user-level virtual address space拷贝了一份,子进程和父进程共享physical memeory(见第9章)。★★链接★fork函数在子进程中返回0,在父进程中返回1。图11的程序运行结果为:parent : x=1 child : x=2或者child : x=2 parent : x=1。fork函数的特点可总结如下:1)Call once,return twice。fork函数调用一次返回两次,分别给父进程和子进程返回1和0;2)Corruent execution。父进程和子进程是并发执行的;3)seperated virtual address space,共享physical memory。子进程将父进程user-level vitual address space拷贝了一份,子进程和父进程共享physical memory。
#include#include pid_t fork(void);
#include "csapp.h" int main(){ pid_t pid; int x =1; pid = fork(); if(pid==0){ /*child*/ printf("child : x=%d\n",++x); exit(0); }
/*parent*/ printf("parent : x=%d\n",--x); exit(0); }
图11 使用fork函数创建子进程
一个程序中调用多次fork函数的情况容易使人混淆。根据程序代码画出进程执行流程图是有帮助的,在进程流程图中可以直观的看到进程的创建以及各个进程中的重要操作。如图12所示,调用了两次fork函数;第一次fork函数调用创建子进程,在新创建的子进程中再次调用fork函数。
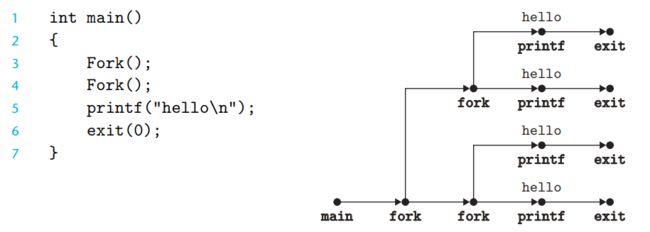
图12 图解fork函数嵌套执行
当unix的system-level函数遇到error时,它们通常返回-1并给errno赋值。我们可以对fork进行如下异常检查,但这使得代码可读性变差。我们可以使用error-handling wrappers来简化代码。Wrapper调用原函数并检查error。比如,图13为函数fork的error-handling wrappers。在后面的章节中都将使用error-handling wrappers,这可以保持代码简洁。
if((pid = fork()<0){ fprintf(stderr,"fork error: %s\n", strerror(errno)); exit(0); }
void unix_errot(char *msg) /*Unix-style error*/ { fprintf(stderr,"%s: %s\n",msg,strerror(errno)); exit(0); } pid_t Fork(void) { pid_t pid; if((pid = fork())<0) unix_error("Fork error"); return pid; }
图13 error-handling wrappers函数Fork
3.2 wait
当一个process执行exit后,process相关的内存和资源都会被释放,但是process在process table中的process‘s entry仍然保留。状态为terminated且尚未从process table中移除的进程被称为zombie。当子进程exit后,会向父进程发送SIGCHLD signal;父进程可以通过wait函数来接收SIGCHLD signal,然后将zombie从process table中移除。如果父进程没有成功调用wait函数,zombie将会在process table中遗留。当一个子进程变为zombie后,可以通过终止它的父进程来清除zombie,这是因为init process的存在。init process 是所有进程的祖先,他的PID为1,在系统启动时即创建,且永远不会terminated。当子进程的父进程终止时,子进程变为orphan。kernel将init process作为所有orphan的父进程。以init process作为父进程的进程终止后,kernel会安排init process去移除zombie。init process会周期地移除父进程为init的zombie。在像shells或servers等长期运行的程序中,应该总是移除zombie;如果zombie不能及时移除,可能会引起process table entries不足。
#include#include pid_t wait(int *statusp);
进程在执行wait函数时,如果已经有子进程终止,wait函数会立即返回pid;如果没有终止的子进程,那么该进程会暂停执行直到出现子进程终止,然后wait函数返回pid。在wait函数执行过程中,kernel已经将terminated child在系统中的痕迹移除。相比于wait函数,waitpid函数适用于更复杂的情况。当参数pid大于0时,只有该pid的进程在父进程的等待范围内;当参数等于-1时,所有的子进程都在父进程的等待范围内。options表示进程的等待策略。当一个进程执行waitpid函数且options的值为默认值0时,如果等待集合中的进程已经有终止的,waitpid函数会立即返回pid;如果等待集合中的进程都没有终止,那么该进程会暂停直到等待集合中的进程终止。options的值还可以为WNOHANG、WUNTRACED和WCONTINUED。相比于options为默认值时,当options的值为WNOHANG时,如果等待集合中的进程都没有终止,waitpid函数也会立即返回,返回值为0。相比于options为默认值时,当options的值为WUNTRACED时,如果等待集合中的进程发生terminated或stopped时,waitpid函数都会返回。相比于options为默认值时,当options的值为WCONTINUED时,如果等待集合中的进程发生terminated或由stopped状态变为running状态时,waitpid函数都会返回。
#include#include pid_t waitpid(pid_t pid, int *statusp, int options);
如果waitpid的参数statusp不为Null,那么子进程的信息会被存储在statusp指向的位置。可以通过宏命令来解释statusp,比如WIFEXITED(statusp*)为true表示子进程是通过exit或return正常终止的。其它的宏命令有WEXITSTATUS、WIFSIGNALED、WTERMSIG、WIFSTOPPED、WSTOPSIG和WIFCONTINUED等。
如果调用waitpid函数的进程没有子进程,函数会返回-1,并将errno设置为ECHILD;如果waitpid函数被一个signal中断,函数会返回-1,并将errno设置为EINTR。wait(*statusp)函数可以看成是waitpid(-1,*statusp,0)。
图14为waitpid函数的使用示例。它的输出结果为:
linux>./waitpid1
chilld 22966 terminated normally with exit status=100
chilld 22967 terminated normally with exit status=101。
#include "csapp.h" #define N 2 int main() { int status, i; pid_t pid[N], retpid; /* Parent creates N children */ for (i = 0; i < N; i++) if ((pid[i] = Fork()) == 0) /* Child */ exit(100+i); /* Parent reaps N children in order */ i = 0; while ((retpid = waitpid(pid[i++], &status, 0)) > 0) { if (WIFEXITED(status)) printf("child %d terminated normally with exit status=%d\n", retpid, WEXITSTATUS(status)); else printf("child %d terminated abnormally\n", retpid); } /* The only normal termination is if there are no more children */ if (errno != ECHILD) unix_error("waitpid error"); exit(0); }
图14 按子进程的创建顺序移除zombie children
3.3 execve
execve函数在当前进程的context中加载并运行一个新的程序。当execve正常执行时,没有返回值;当execve运行error时,返回值为-1。argv变量表示null-terminated的指针数组,每个指针指向一个argument string。按照惯例,argv[0]是filename。envp变量表示null-terminated的指针数组,每个指针指向一个argument string,string的格式是“name=value”。当execve加载filename后,调用start-up code。start-up code会进行stack的设置并进入到程序的main routine。main routine的格式为int main(int argc, char *argv[], char *envp[]),参数argc表示argv[]中的指针个数。
#include
int execve(const char *filename, const char *argv[], const char *envp[]);
当main函数开始执行时,user stack的结构如图15所示。stack的中间是*envp[]和*argv[]表示的指针数组,每个指针指向一个底端的variable string;stack的顶端是为start-up函数libc_start_main保留的。
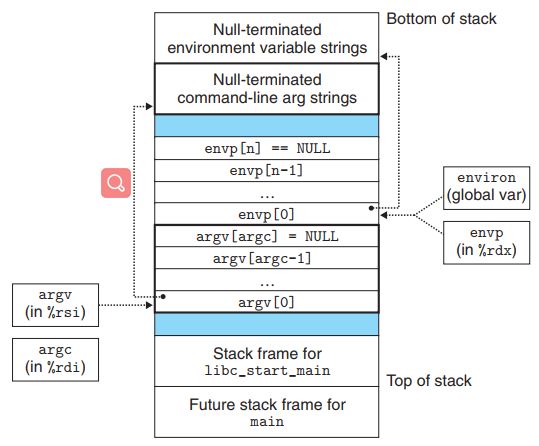
图15 新程序启动时的user stack
3.4 使用fork和execve运行程序
在Unix shells和 Web servers中,fork和execve被大量使用。当打开一个control terminal时,就会运行一个shell程序,shell程序会根据用户输入加载并开始运行新的程序。图16展示了一个简单的shell程序。这个shell打印命令提示符,等待用户在stdin输入command line,然后解析command line并运行command line指定的程序。(★★★图16的程序还有疑问)


1 1 #include "csapp.h" 2 2 #define MAXARGS 128 3 3 4 4 /* Function prototypes */ 5 5 void eval(char *cmdline); 6 6 int parseline(char *buf, char **argv); 7 7 int builtin_command(char **argv); 8 8 9 9 int main() 10 10 { 11 11 char cmdline[MAXLINE]; /* Command line */ 12 12 13 13 while (1) { 14 14 /* Read */ 15 15 printf("> "); 16 16 Fgets(cmdline, MAXLINE, stdin); 17 17 if (feof(stdin)) 18 18 exit(0); 19 19 20 20 /* Evaluate */ 21 21 eval(cmdline); 22 22 } 23 23 } 24 24 25 25 /* eval - Evaluate a command line */ 26 26 void eval(char *cmdline) 27 27 { 28 28 char *argv[MAXARGS]; /* Argument list execve() */ 29 29 char buf[MAXLINE]; /* Holds modified command line */ 30 30 int bg; /* Should the job run in bg or fg? */ 31 31 pid_t pid; /* Process id */ 32 32 33 33 strcpy(buf, cmdline); 34 34 bg = parseline(buf, argv); 35 35 if (argv[0] == NULL) 36 36 return; /* Ignore empty lines */ 37 37 38 38 if (!builtin_command(argv)) { 39 39 if ((pid = Fork()) == 0) { /* Child runs user job */ 40 40 if (execve(argv[0], argv, environ) < 0) { 41 41 printf("%s: Command not found.\n", argv[0]); 42 42 exit(0); 43 43 } 44 44 } 45 45 46 46 /* Parent waits for foreground job to terminate */ 47 47 if (!bg) { 48 48 int status; 49 49 if (waitpid(pid, &status, 0) < 0) 50 50 unix_error("waitfg: waitpid error"); 51 51 } 52 52 else 53 53 printf("%d %s", pid, cmdline); 54 54 } 55 55 return; 56 56 } 57 57 58 58 /* If first arg is a builtin command, run it and return true */ 59 59 int builtin_command(char **argv) 60 60 { 61 61 if (!strcmp(argv[0], "quit")) /* quit command */ 62 62 exit(0); 63 63 if (!strcmp(argv[0], "&")) /* Ignore singleton & */ 64 64 return 1; 65 65 return 0; /* Not a builtin command */ 66 66 } 67 67 68 68 /* parseline - Parse the command line and build the argv array */ 69 69 int parseline(char *buf, char **argv) 70 70 { 71 71 char *delim; /* Points to first space delimiter */ 72 72 int argc; /* Number of args */ 73 73 int bg; /* Background job? */ 74 74 75 75 buf[strlen(buf)-1] = ’ ’; /* Replace trailing ’\n’ with space */ 76 76 while (*buf && (*buf == ’ ’)) /* Ignore leading spaces */ 77 77 buf++; 78 78 79 79 /* Build the argv list */ 80 80 argc = 0; 81 81 while ((delim = strchr(buf, ’ ’))) { 82 82 argv[argc++] = buf; 83 83 *delim = ’\0’; 84 84 buf = delim + 1; 85 85 while (*buf && (*buf == ’ ’)) /* Ignore spaces */ 86 86 buf++; 87 87 } 88 88 argv[argc] = NULL; 89 89 90 90 if (argc == 0) /* Ignore blank line */ 91 91 return 1; 92 92 93 93 /* Should the job run in the background? */ 94 94 if ((bg = (*argv[argc-1] == ’&’)) != 0) 95 95 argv[--argc] = NULL; 96 96 97 97 return bg; 98 98 }
图 16 一个简单的shell程序(文件路径为code/ecf/shellex.c)
4.siginal
signal是由一些system event引起,由kernel发送给指定进程,然后进程作出反应。kernel 通过更改指定进程上的state以向其发送信号,通知进程某些system event的发生。进程对不同的signal有默认处理,如图17;它也可以通过install signal handler(见4.3)来对signal进行处理。siganl handler的实现在user mode下,这与运行于kernel mode下的exception handler不同。signal允许kernel中断进程,并将控制转移到signal handler中,它也是exception control flow的一种。

图17 Linux signals (a)多年前,main memory被core memory的技术实现。“Dumping core”是遗留词汇,它表示将code和data segments写入到disk中; (b)表示signal不能被caught或ignored。
4.1 sending signal
在Unix systems中,有多种方法向进程发送signal,每种方法都基于process group的概念。每个进程都属于唯一的process group,每个进程组有一个process group ID。可以通过getgprp()获取当前进程的process group ID。通过setpgid函数将进程pid的进程组改为pgid。如果pgid为0,则将创建pgid为进程pid的进程组,并将进程pid加入到该进程组。
#includepid_t getpgrp(void); int setpgid(pid_t pid, pid_t pgid);
可以通过control terminal给进程发送信号,比如通过termianl input和terminal-generated signals。control terminal和进程的关系如图18所示,一个control terminal可以对应一个foreground group和多个background groups。如果在control termianl中运行linux> proc3 | proc4 | proc5命令,control terminal中运行的login shell进程(参见3.5)会创建一个foreground job,它包含由Unix pipe连接的3个foreground process,分别用来加载运行proc3、proc4和proc5。如果在命令后加上&,则表示在后台进程运行程序,如linux> proc1|proc2 &表示control termial的login shell进程为两个background process分别创建了background job,用来加载运行proc1和proc2。login shell和前后台进程组的关系如图19所示。control terminal打开时(没有显示的control terminal也会存在★★★),login shell是一直运行的后台进程。我们把foreground process和background归为同一个session,以login shell作为session leader(详见 深入了解进程 foreground进程组只有一个,是否可以详细讲解?★★★)。control terminal可以通过terminal input(后台进程好像也可以通过此方法)和terminated-generated signals(比如快捷键ctrl+c)向foreground process发送信号;只能通过modern disconnect或关闭control terminal向background process发送SIGHUP信号。
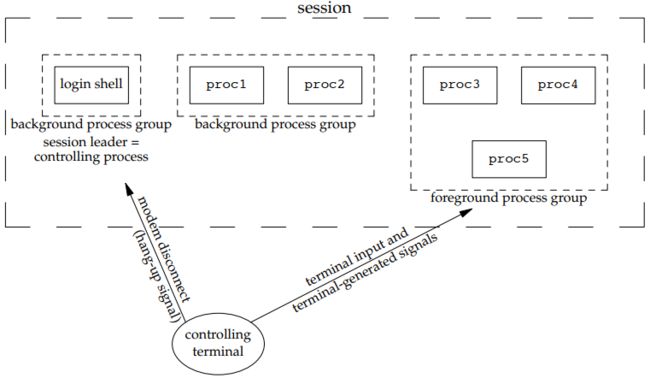
图18 controlling termianl以及对应的session和process group

图19 shell和前后台进程组的关系
我们可以通过/bin/kill程序向其他进程发送任意signal。比如,当我们运行命令linux>/bin/kill -9 15213时,将会发送signal 9(SIGKILL)给 进程15213。如果命令中的pid为负数,则会向进程所在process group的所有进程发送signal,比如linux>/bin/kill -9 -15213。也可以通过kill函数发送signal给其它进程。如果pid大于0,向进程pid发送信号 sig;如果pid等于0,向当前进程所在进程阻的所有进程发送信号sig;如果pid小于0,向进程组|pid|中的所有进程发送信号sig。一个进程可以通过调用alarm函数发送SIGALRM信号给自己。如果secs为0,没有alarm被调度。在对alarm调用时,如果有pending alarm,则取消pending alarm,并返回其剩余的seconds;如果没有pending alarm,则返回0。
#include#include int kill(pid_t pid, int sig); Returns: 0 if OK,-1 on error
#includeunsigned int alarm(unsigned int secs); Returns:remaining seconds of previous alarm,or 0 if no previous alarm
4.2 Reciving Signals
进程接收信号后,默认情况下会进行如下反应,1)进程terminate;2)进程terminate并且dumps core;3)进程stops直到接收SIGCONT信号;4)进程忽略signal。一个进程通过signal函数来指定进程对某种signal的反应;SIGSTOP和SIGKILL信号除外,进程对它们的默认反应不能被修改。如果handler为SIG_IGN,信号signum被ignored;如果handler为SIG_DFL,进程对信号signum的反应还原为默认;如果handler是user-defined的函数,进程在接收到信号signum时,这个函数会被调用。我们称这个函数为signal handler。通过signal函数把进程对信号的默认反应修改为handler的过程称为installing the handler;handler被调用的过程被称为catching handler;handler的执行被称为handling the handler。当进程接收到signal k后,将控制转移到signal k对应的signal handler;当signal handler执行完成后,返回到进程中断的位置继续执行。
#includetypedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler); Returns:pointer to previous handler if OK,SIG_ERR on error
进程中还存储有pending和blocked的bit vectors信息。pending和blocked分别表示进程pending signal set和blocked signal set。pending signal指已经发送,但还没被接收的signal;一个进程对于特定类型的signal只能有一个pending signal,也就是说当一个进程对于特定类型的signal已经有了pending signal,那么发送到该进程的特定类型的signal将被忽略。一个进程可以锁定某些signal,这些signal可以被发送到该进程,但是不会被接收,除非进程解锁这些signal。当signal k被发送时,pending中的bit k被设置;当signal被接收时,pending中的bit k被清除,如图20所示。(图示是否正确?★★★)可通过sigprocmask函数来设置或清除blocked中的bit k,以实现对blocked signal的添加和删除。sigprocmask的参数how可以为以下值:1)SIG_BLOCK表示将set中的所有signal添加到blocked中(blocked = blocked | set);2)SIG_UNBLOCK表示将set中的signal从blocked中移除(blocked=set&~blocked);3)SIG_SETMASK表示blocked=set。参数oldset表示之前的状态为blocked的signal set。可以通过以下函数对signal set进行操作:sigemptyset函数将set初始化为empty set;sigfillset函数将所有的signal添加到set中;sigaddset函数将信号signum添加到set中;sigdelset函数删除set中的信号signum;当signum是set的成员时sigismember返回1,不是set的成员时返回0。
#includeint sigprocmask(int how, const sigset_t *set, sigset_t *oldset); int sigemptyset(sigset_t *set); int sigfillset(sigset_t *set); int sigaddset(sigset_t *set, int signum); int sigdelset(sigset_t *set, int signum); Returns:0 if OK, -1 on error int sigismember(const sigset_t *set, int signum); Returns:1 if member,0 if not,-1 on error

图20 当signal被发送时,pending中的bit k被设置
当kernel将进程p由kernel mode切换到user mode(比如从system call返回或完成一个context switch)时,kernel会检查进程 p的unblocked pending signals(pending&~blocked)。如果unblocked pending signals为空,进程会继续执行下一条指令Inext;如果unblocked pending signals不为空,则先从unblocked pending signals中最小的非零bit k开始,进程接收signal k并进入到signal handler(多个signal handler会不会交叉?★★),然后以bit k递增的顺序重复上面的操作。当所有的signal handler执行完毕,返回到进程终止的位置继续执行Inext。
signal handlers可以被其它handlers中断,如图21所示。如图,main程序catch signal s,中断main程序并将控制转移到handler S。当S在运行时,主程序catch signal t≠s,它将中断S并将控制转移到handler T。当T返回时,S从中断位置恢复执行。最后,S返回并将控制转移到main程序的中断位置以恢复执行。
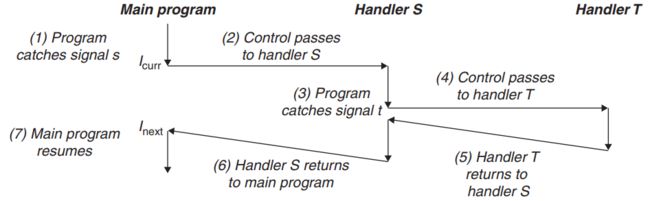
图21 Handlers可以被其它handlers中断
4.3 signal handler
signal handling是Linux系统级编程中的一个棘手问题。如图21所示,Handers和main程序是并发执行的;如果他们共用全局变量,会有并发安全的问题。为了帮助你们写出并发安全的程序,下面给出了handler函数的几条书写指南,它们在大多数时候可以保证并发安全。
1)保证handlers尽可能简单。比如,在handler仅设置一个global flag并立即返回,所有进程在signal接收后的操作都由main程序通过周期性检查(和重置)那个global flag来实现。
2)在handler中只调用async-signal-safe的函数。图22展示了Linux中async-signal-safe的函数,它们执行时不会其它的signal handler打断。我们也可以在函数中只使用局部变量,以保证并发安全。在signal handler中向终端输出的函数中只有write是安全的,像printf和sprintf是不安全的。我们开发了Sio(Safe I/O)包,用于打印signal handler中的一些信息。函数sio_putl 和sio_puts分别向终端输出一个long和string。函数sio_error打印异常信息并终止。(具体的例子?★★★)
#include "csapp.h" ssize_t sio_putl(long v); ssize_t sio_puts(char s[]); Returns:number of bytes transferred if OK,-1 on error void sio_error(char s[]);
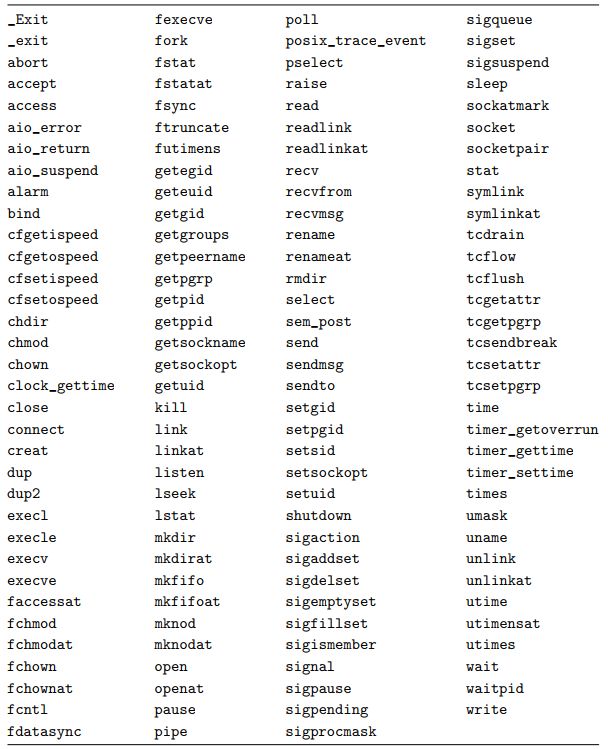
图22 Async-signal-safe functions
3) 在handler中保存并恢复errno。许多Linux中的async-signal-safe函数由于error返回时会设置errno。如果在handler调用这些函数,会对main程序中依赖errno的部分造成干扰。为了handler可能引起的干扰,我们handler的入口处将errno保存为局部变量,在返回前还原errno的值。如果handler不返回,而是直接exit,那么就没有必要这要做了。
4)在访问共用全局变量时block all signals。比如,handler和main程序共用全局变量,那么在handler和main程序对全局变量访问时要暂时block all signal。这是因为对某个data structure d的访问可能包含一个instruction序列,如果main程序在intruction序列中间发生中断,那么handler很可能发现d处在不连续的状态并导致意外的结果。(暂时没想到好例子★★★)
5)使用volatile修饰全局变量。比如,handler和main程序共用全局变量g,当handler对g进行修改后,main程序读取g。由于编译器的优化,main程序中可能缓存了g的复本,导致在handler对g修改后main程序读取的g仍然不变。用volatile修饰全局变量后,编译器不会再缓存该变量。
6)声明sig_atomic_t类型的flags。当像条目1)中一样只对flag进行读写操作时,flag可以使用sig_atomic_t类型以保证读写的原子性。当对flag进行诸如flag ++和flag = flag + 10等操作时,使用sig_atomic_t类型也无法保证原子性,这些操作包含多条instruction。
4.4 signal handler相关案例
4.4.1 correct signal handling
如图23所示,main函数中先为信号SIGCHLD installing handler,然后循环创建子进程。当子进程exit时,会向main程序发送SIGCHLD信号,main程序跳转到installing handler执行。在installing handler中,waitpid函数会移除状态为terminated的子进程残留记录。图23的执行结果为:(结果是否唯一★★★)
linux> ./signal1
Hello from child 14073
Hello from child 14074
Hello from child 14075
Handler reaped child
Handler reaped child
CR
Parent processing input
从执行结果可以看出,共创建了3个子进程,但只清除了2个状态为terminated的子进程(zombie children)的残留记录,这与预想的不一致。这是由于当handler接收到第一个SIGCHLD信号后,休眠了1s。当第三个SIGCHLD发送给主程序时,正在执行第一个SIGCHLD的handler,第二个SIGCHLD正处于pending状态,由于pending signal最多只能有一个,第三个SIGCHLD将被忽略。为了解决这个问题,我们要明白pending signal的存在表明进程至少接收到了一个SIGCHLD信号,因此我们在signal handler中尽可能多的清除zombie children。图24展示了修改后的程序。
1 /* WARNING: This code is buggy! */ 2 void handler1(int sig) 3 { 4 int olderrno = errno; 5 6 if ((waitpid(-1, NULL, 0)) < 0) 7 sio_error("waitpid error"); 8 Sio_puts("Handler reaped child\n"); 9 Sleep(1); 10 errno = olderrno; 11 } 12 13 int main() 14 { 15 int i, n; 16 char buf[MAXBUF]; 17 18 if (signal(SIGCHLD, handler1) == SIG_ERR) 19 unix_error("signal error"); 20 21 /* Parent creates children */ 22 for (i = 0; i < 3; i++) { 23 if (Fork() == 0) { 24 printf("Hello from child %d\n", (int)getpid()); 25 exit(0); 26 } 27 } 28 29 /* Parent waits for terminal input and then processes it */ 30 if ((n = read(STDIN_FILENO, buf, sizeof(buf))) < 0) 31 unix_error("read"); 32 33 printf("Parent processing input\n"); 34 while (1) 35 ; 36 37 exit(0); 38 }
图23 signal1;这个程序有缺陷,它假定了signal可以排队
1 void handler2(int sig) 2 { 3 int olderrno = errno; 4 5 while (waitpid(-1, NULL, 0) > 0) { 6 Sio_puts("Handler reaped child\n"); 7 } 8 if (errno != ECHILD) 9 Sio_error("waitpid error"); 10 Sleep(1); 11 errno = olderrno; 12 }
图24 signal2;这是对图19中signal1的改进,它考虑到了signal不会排队
4.4.2 Synchronizing Flows to avoid race (★★★访问全局变量需要锁定其它信号,不锁定其它信号有什么后果?)
并发程序在相同的存储位置上读写的安全问题是几代计算机科学家的挑战。程序控制流交错的数量在指令数量上是指数级的。图25所示的程序就存在并发安全的问题,程序中main任务和signal-handling控制流之间交错着,函数deletejob可能在函数addjob之前执行,导致在job list上遗留一个incorrect entry。这种经典的并发错误被称为race。main任务中的addjob和handler中的deletejob进行race,如果addjob赢得race,那么结果正确;否则结果错误。为了解决这个问题,可以通过在调用fork之前blocking SIGCHLD并在调用addjob之后unblocking SIGCHLD,以保证所有子进程在加入job list后被清除,如图26所示。
1 void handler(int sig) 2 { 3 int olderrno = errno; 4 sigset_t mask_all, prev_all; 5 pid_t pid; 6 7 Sigfillset(&mask_all); 8 while ((pid = waitpid(-1, NULL, 0)) > 0) { /* Reap a zombie child */ 9 Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); 10 deletejob(pid); /* Delete the child from the job list */ 11 Sigprocmask(SIG_SETMASK, &prev_all, NULL); 12 } 13 if (errno != ECHILD) 14 Sio_error("waitpid error"); 15 errno = olderrno; 16} 17 18 int main(int argc, char **argv) 19 { 20 int pid; 21 sigset_t mask_all, prev_all; 22 23 Sigfillset(&mask_all); 24 Signal(SIGCHLD, handler); 25 initjobs(); /* Initialize the job list */ 26 27 while (1) { 28 if ((pid = Fork()) == 0) { /* Child process */ 29 Execve("/bin/date", argv, NULL); 30 } 31 Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); /* Parent process */ 32 addjob(pid); /* Add the child to the job list */ 33 Sigprocmask(SIG_SETMASK, &prev_all, NULL); 34 } 35 exit(0); 36 }
图25 一个有同步错误的shell程序(code/ecf/promask1.c)
1 void handler(int sig) 2 { 3 int olderrno = errno; 4 sigset_t mask_all, prev_all; 5 pid_t pid; 6 7 Sigfillset(&mask_all); 8 while ((pid = waitpid(-1, NULL, 0)) > 0) { /* Reap a zombie child */ 9 Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); 10 deletejob(pid); /* Delete the child from the job list */ 11 Sigprocmask(SIG_SETMASK, &prev_all, NULL); 12 } 13 if (errno != ECHILD) 14 Sio_error("waitpid error"); 15 errno = olderrno; 16 } 17 18 int main(int argc, char **argv) 19 { 20 int pid; 21 sigset_t mask_all, mask_one, prev_one; 22 23 Sigfillset(&mask_all); 24 Sigemptyset(&mask_one); 25 Sigaddset(&mask_one, SIGCHLD); 26 Signal(SIGCHLD, handler); 27 initjobs(); /* Initialize the job list */ 28 29 while(1){ 30 Sigprocmask(SIG_BLOCK, &mask_one, &prev_one); /* Block SIGCHLD */ 31 if ((pid = Fork()) == 0) { /* Child process */ 32 Sigprocmask(SIG_SETMASK, &prev_one, NULL); /* Unblock SIGCHLD */ 33 Execve("/bin/date", argv, NULL); 34 } 35 Sigprocmask(SIG_BLOCK, &mask_all, NULL); /* Parent process */ 36 addjob(pid); /* Add the child to the job list */ 37 Sigprocmask(SIG_SETMASK, &prev_one, NULL); /* Unblock SIGCHLD */ 38 } 39 exit(0); 40 }
图26 对图21中程序的改进;使用Sigprocmask同步进程(code/ecf/promask2.c)
4.4.3 explictly waiting for Signals
有时main程序需要等待直到特定的signal handler开始执行。比如说,当一个Linux shell创建了一个foreground job,它在执行下一个用户命令前需要等待job终止并通过SIGCHLD handler移除job残留。如图27所示,main程序在创建子进程后,通过while循环等待子进程终止以及SIGCHLD handler将子进程残留清除。但是图中没有循环体的while循环非常浪费处理器的资源,我们可以在while的循环体中添加pause函数。当main程序接收到SIGCHLD信号后,会从pause中被唤醒并跳转到signal handler;使用while循环的原因是pause也可能被其它信号打断。这种方式的缺陷是当程序在while后pause前接收到SIGCHLD,那么pause可能会永远休眠。使用sleep代替pause可以避免程序永远休眠,但是函数sleep的参数secs(见第3节)不好设定。如果程序在while后sleep前接收到SIGCHLD,且sleep的参数secs设置过大,比如sleep(1),那么程序将会等待很长时间(相对而言)。如果sleep的参数secs设置过小,则会浪费处理器的资源。
while(!pid) pause();
while(!pid) sleep(1);
更好的方式是使用sigsuspend函数。sigsuspend函数等同于以下代码(具有原子性):
sigprocmask(SIG_SETMASK,&prev,NULL);
pause();
sigprocmask(SIG_BLOCK,&mask,&prev);
#includeint sigsuspend(const sigset_t *mask);
sigsuspend函数暂时地将blocked set设置为prev,以解锁mask,直到接收到信号,信号通知进程运行handler或者终止进程。如果信号通知终止进程,那么进程将不会从sigsuspend返回。如果信号通知进程运行handler,那么sigsuspend会在handler返回后返回,并在返回前将blocked set恢复到sigsuspend刚被调用时的状态。图28中展示了在图27的while循环中填充sigsuspend后的程序,它节约了处理器的资源。sigsuspend相比pause而言,避免了进程一直休眠的情况;相比sleep而言更高效。
#include "csapp.h" volatile sig_atomic_t pid; void sigchld_handler(int s) { int olderrno = errno; pid = waitpid(-1, NULL, 0); errno = olderrno; } void sigint_handler(int s) { } int main(int argc, char **argv) { sigset_t mask, prev; Signal(SIGCHLD, sigchld_handler); Signal(SIGINT, sigint_handler); Sigemptyset(&mask); Sigaddset(&mask, SIGCHLD); while (1) { Sigprocmask(SIG_BLOCK, &mask, &prev); /* Block SIGCHLD */ if (Fork() == 0) /* Child */ exit(0); /* Parent */ pid = 0; Sigprocmask(SIG_SETMASK, &prev, NULL); /* Unblock SIGCHLD */ /* Wait for SIGCHLD to be received (wasteful) */ while (!pid) ; /* Do some work after receiving SIGCHLD */ printf("."); } exit(0); }
图27 使用spin loop等待信号;程序是正确的,但是浪费处理器资源
1 while (1) { 2 Sigprocmask(SIG_BLOCK, &mask, &prev); /* Block SIGCHLD */ 3 if (Fork() == 0) /* Child */ 4 exit(0); 5 6 /* Wait for SIGCHLD to be received */ 7 pid = 0; 8 while (!pid) 9 sigsuspend(&prev); 10 11 /* Optionally unblock SIGCHLD */ 12 Sigprocmask(SIG_SETMASK, &prev, NULL); 13 14 /* Do some work after receiving SIGCHLD */ 15 printf("."); 16 }
图28 使用sigsuspend函数等待信号(请结合图22)
5.nonlocal jump
nonlocal jump将控制直接从一个函数转移到另一个当前正在执行的函数,它是user-level exception control flow。nonlocal jump通过函数setjmp和longjmp来实现。函数setjmp保存current calling environment在env buffer中,并返回0;env buffer在后面的函数longjmp会使用。current calling environment包含the program counter,stack pointer和general-purpose registers。由于某些超出我们知识范围的原因,函数setjmp的返回值不能被变量接收,比如rc = setjmp(env)是错误的。但是,函数setjmp却可以在switch或条件语句的条件判断中使用。函数longjmp从env buffer中恢复the calling environment并将longjump的参数retval作为setjmp的返回值。
#includeint setjmp(jmp_buf env); int sigsetjmp(sigjmp_buf env, int savesigs); void longjmp(jmp_buf env,int retval); void siglongjmp(sigjmp_buf env, int retval);
longjmp的一个应用是从函数调用时深度嵌套的代码中直接返回,通常是由于检测到error condition。从深度嵌套的代码中直接返回相比于常规的call-and-return,不用先弹出调用栈。如图29所示,main函数首先调用setjmp保存current calling environment,然后调用函数foo,函数foo中又调用了函数bar。当函数foo或函数bar中遇到error时,会通过longjmp直接将控制转移到the calling environment,也就是转移到函数setjmp。setjmp将有一个不为0的返回值,它表示error的类型;接着error将得到处理。longjmp相比于常规的call-and-return,避开了直接函数调用的意想不到的后果。比如,在函数调用时,我们allocate了一些data structure,在还没有deallocate这些data structure时出现了error,那么deallocation将不会进行,可能会引起数据泄露。
1 #include "csapp.h" 2 3 jmp_buf buf; 4 5 int error1 = 0; 6 int error2 = 1; 7 8 void foo(void), bar(void); 9 10 int main() 11 { 12 switch(setjmp(buf)) { 13 case 0: 14 foo(); 15 break; 16 case 1: 17 printf("Detected an error1 condition in foo\n"); 18 break; 19 case 2: 20 printf("Detected an error2 condition in foo\n"); 21 break; 22 default: 23 printf("Unknown error condition in foo\n"); 24 } 25 exit(0); 26 } 27 28 /* Deeply nested function foo */ 29 void foo(void) 30 { 31 if (error1) 32 longjmp(buf, 1); 33 bar(); 34 } 35 36 void bar(void) 37 { 38 if (error2) 39 longjmp(buf, 2); 40 }
图29 nonlocal jump exception(文件位置code/ecf/setjmp.c)
nonlocal jumps的另一个应用是在signal handler中直接将控制转移到特定的代码位置,而不是之前由于接受到信号而中断的指令。图30所示为使用sigsetjmp和siglongjmp的程序。程序在终端运行时,先后多次按下ctrl+C时,输入出的结果如下:
linux> ./restart
starting
processing...
processing...
ctrl+C
restarting
processing...
ctrl+C
restarting
processing...
1 #include "csapp.h" 2 3 sigjmp_buf buf; 4 5 void handler(int sig) 6 { 7 siglongjmp(buf, 1); 8 } 9 10 int main() 11 { 12 if (!sigsetjmp(buf, 1)) { 13 Signal(SIGINT, handler); 14 Sio_puts("starting\n"); 15 } 16 else 17 Sio_puts("restarting\n"); 18 19 while(1) { 20 Sleep(1); 21 Sio_puts("processing...\n"); 22 } 23 exit(0); /* Control never reaches here */ 24 }
图30 一个nolocal jump程序,当用户按下ctrl+C后会重启(文件位置code/ecf/restart.c)
注意图30中的main程序中的exit(0)是不会执行到的,这保证了调用longjmp进行控制转移时main程序是在执行中的。
参考资料:
[1] Randal E.Bryant,David R. O'Hallaron.Computer Systems:A Programmer's Perspective,3/E(CS:APP3e).
[2] Chapter 6 Interrupt and exception handling ★★
[3] I/Odevice 引起pin变化的资料; ★★
1