点云数据理解(PointNet实现第3步)
PointNet实现第3步——点云理解
1.三维数据的表现形式
三维数据的表述形式一般分为4种:
 图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用
图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用
| 三维数据形式 | 简介 | 图例 |
|---|---|---|
| point clouds(点云) | 即三维空间中点的集合;由N个D维的点组成,当D=3则可表示为三维坐标点(x,y,z) ,每一点都是由某个(xyz)位置决定的,我们同时可以为其指定其它的属性(如 RGB 颜色)。它们是激光雷达数据被获取时的原始形式,立体视觉系统和 RGB-D 数据(包含标有每个像素点深度值的图像)通常在进行进一步处理之前会被转换成点云。 | (来源 :加州理工学院)  |
| Mesh | 由三角面片和正方形面片组成,其来源于多边形网格。多边形网格由一组带公共顶点的凸多边形表面组成,可近似一个几何表面。我们可以将点云看作是从基础的连续集合表面采样得到的三维点集;多边形网格则希望通过一种易于渲染的方式来表示这些基础表面。尽管多边形网格最初是为计算机图形学设计的,但它对于三维视觉也十分有用。我们可以通过几种不同的方法从点云中得到多边形网格,其中包括 Kazhdan 等人于 2006 年提出的「泊松表面重建法」。 | (来源:华盛顿大学) |
| Volumetric(体素) | 体素网格是从点云发展而来的,由三维栅格物体用0和1表征。体素就好比三维空间中的像素点,我们可以把体素网格看作量化的、大小固定的点云。然而,点云在空间中的任何地方能够以浮点像素坐标的形式涵盖无数个点;体素网格则是一种三维网格,其中的每个单元(或称「体素」)都有固定的大小和离散的坐标。 | (来源:印度理工学院) |
| multi-view(多视角) | 多角度的RGB图像或者RGB-D图像。多视图表示是从不同的模拟视角(「虚拟摄像头」)获取到的渲染后的多边形网格二维图像集合,从而通过一种简单的方式表现三维几何结构。简单地从多个摄像头(如立体视觉系统 stereo)捕捉图像和构建多视图表示之间的区别在于,多视图实际上需要构建一个完整的 3D 模型,并从多个任意视点渲染它,以充分表达底层几何结构。与上面的其他三种表示不同,多视图表示通常只用于将 3D 数据转换为易于处理或可视化的格式。 | (来源:斯坦福大学)  |
2.相关框架及知识了解
请查看此转载博文,该博文转载自机器之心,原文来源于The Gradient。
强烈推荐查看上述转载博文,对点云及相关三维数据的优势及劣势会有更多的了解。
3.点云的优劣势总结
优势
相信看完第2点之后,对相关框架及数据都有所了解,下面总结以下点云的优势。
- 可直接测量
通过激光雷达扫描物体可直接产生点云,点云更加接近于设备的原始表征。原始的数据利于端到端的学习。

图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用 - 点云的表达方式更为简单,一个物体可以表示为一个N*D的矩阵。

对于Mesh,则需要选择用三角面片或者四边形等,还需要选择如何连接,三角面片的大小;
对于体素,则需要选择分辨率;
对于多视角,则需要选择拍摄视角等。
图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用
- 包含几何信息
存在的挑战

图来源于: University of Oxford
| 存在的挑战 | 说明 |
|---|---|
| Irregular | 点云数据是不规则的 |
| non-uniform | 点云分布有些地方密集,有些地方稀疏 |
| orderless | 点云本质上是一长串点(nx3矩阵,其中n是点数)。在几何上,点的顺序不影响它在空间中对整体形状的表示,例如,相同的点云可以由两个完全不同的矩阵表示。 |
| 旋转性 | 相同的点云在空间中经过一定的刚性变化(旋转或平移),坐标发生变化。 |
4.点云相关工作发展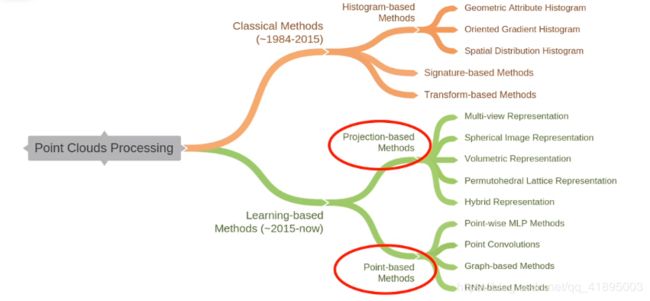
图来源于: University of Oxford

图来源于: University of Oxford

图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用
转化为2D,3D的一些信息会被抹去;特征提取受限于手工提取。
5.点云的解决方案
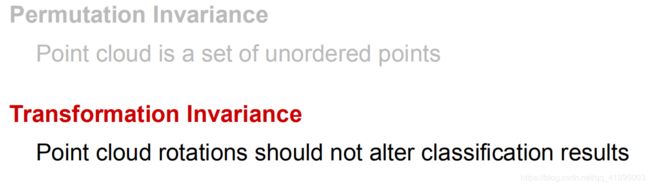
5.1置换不变性
设计的网络必须满足置换不变性,N个数据就有N!个置换不变性。而对称函数可以满足上述置换不变性,如下:
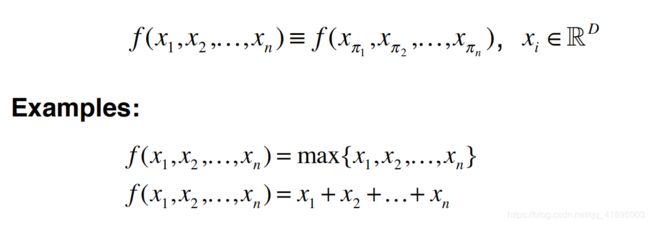
图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用
直接对数据做对称性操作,虽然满足置换不变性,容易丢失很多的几何和有意义的信息。比如取最大值时,只取得最远点,取平均值,只取得重心。
如何不损失
把每一点都映射到高维空间,在更高维空间再做对数据做对称性操作。高维的空间对三维点的表达来说,必定是信息冗余的,但是因为信息的冗余性,我们通过对称性操作综合,可以减少信息的损失,保留足够的点云信息。由此,就可以设计出这PointNet的雏形,称之为PointNet(vanilla):
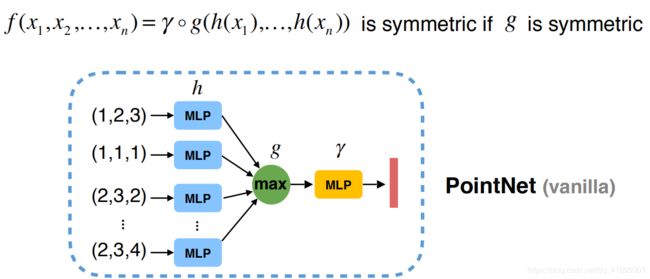
图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用
通过MLP将每个点投影到高维空间,通过max做对称性。
MLP为什么可以投影到高维空间(这个是针对小白的解释,点击此处)
PointNet可以任意的逼近对称函数(通过增加神经网路的深度和宽度):
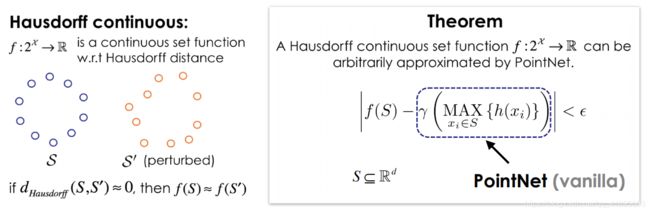
图来源于斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用
5.2旋转不变性(几何不变性)
旋转不变性指的是,通过旋转,所有的点(x,y,z)的坐标发生变化,但是代表的还是同一个物体,如下所示:
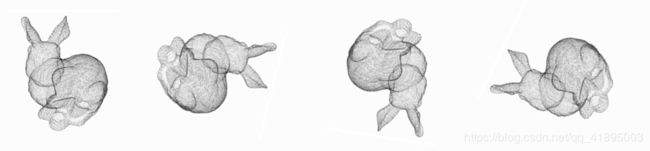
因此对于普通的PointNet(vanilla),如果先后输入同一个但是经过不同旋转角度的物体,它可能不能很好地将其识别出来。在论文中的方法是新引入了一个T-Net网络去学习点云的旋转,将物体校准,剩下来的PointNet(vanilla)只需要对校准后的物体进行分类或者分割即可。
点云是一种非常容易做几何变换的数据,只需要通过矩阵的乘法即可。如下图所示,一个N×3的点云矩阵乘以一个3×3的旋转矩阵即可得到旋转变换后的矩阵,因此对输入点云学习一个3×3 的矩阵,即可将其矫正。
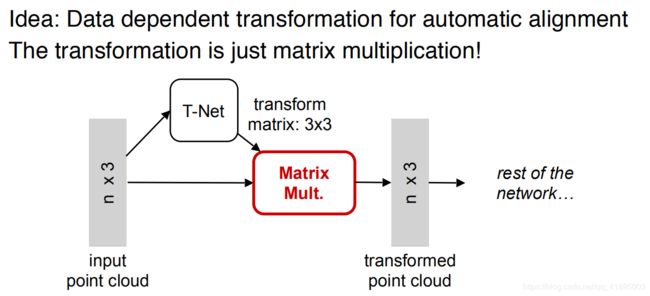
同样的将点云映射到K维的冗余空间后,再对K维的点云特征做一次校对,只不过这次校对需要引入一个正则化惩罚项,希望其尽可能接近于一个正交矩阵。【正则化是由于高维的空间优化较难,通过正则化可以减少优化的难度。】
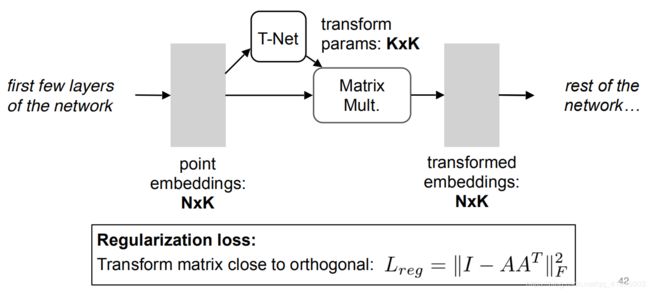
点云的分类网络: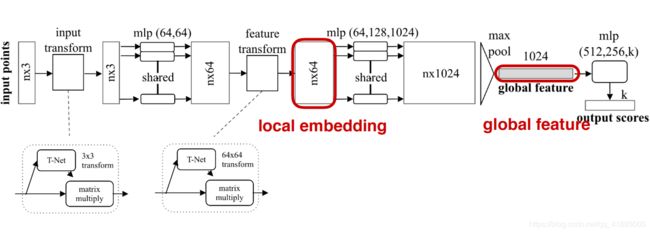
具体来说,对于每一个N×3的点云输入,网络先通过一个T-Net将其在空间上对齐(旋转到正面),再通过MLP将其映射到64维的高维空间上,再64维空间再进行对齐,最后映射到1024维的空间上。这时对于每一个点,都有一个1024维的向量表征,而这样的向量表征对于一个3维的点云明显是冗余的,因此这个时候引入最大池化max pool操作,将1024维所有通道上都只保留最大的那一个,这样得到的1×1024的全局特征。全局特征在通过一个级联全连接网络(即为最后一个MLP),最后达到一个K分类结果。
点云的分割网络:
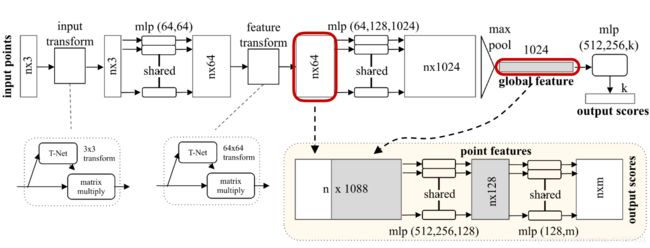 点云的分割可以定义成一个对每一个点的分类问题,如果知道每个点的分类的,就可以对这个点进行固定类别的分割。当然,我们通过全局坐标是没法直接对每个点进行分割。一个简单又有效的做法就是,我们可以把局部的特征,单个点的特征和全局的坐标结合起来,实现分割的功能。用最简单的做法就是,我们可以把全局的特征,进行重复N遍,然后每一个和原来的单个点的特征连接在一起。【
点云的分割可以定义成一个对每一个点的分类问题,如果知道每个点的分类的,就可以对这个点进行固定类别的分割。当然,我们通过全局坐标是没法直接对每个点进行分割。一个简单又有效的做法就是,我们可以把局部的特征,单个点的特征和全局的坐标结合起来,实现分割的功能。用最简单的做法就是,我们可以把全局的特征,进行重复N遍,然后每一个和原来的单个点的特征连接在一起。【插入的解释:上述讲到将局部特征和全局特征结合起来(64+1024=1088),所以就不难解释1088的由来。现在,单个点就具有1088维度。】相当于单个点在全局特征中进行了一次检索(即为单个点去全局特征中看“我”在这个全局特征中处于哪一个位置,“我”应该属于哪一类?)。我们就对每一个连接起来的特征又进行另外一个MLP的变化,最后把它每个点分类成M类,相当于输出M个score。