2019独角兽企业重金招聘Python工程师标准>>> 
在Linux系统中,日志数据主要包括三种类型:
-
内核及系统日志 : 这种日志数据由系统服务rsyslog统一管理,根据其主配置文件/etc/rsyslog.conf中的设置决定将内核消息及各种系统程序消息记录到什么位置。
-
用户日志 : 用与记录Linux系统用户登录及退出系统的相关信息,包括用户名、登录的终端、登录时间、来源主机、正在使用的进程操作等。
-
程序日志 : 有些应用程序会选择由自己独立管理一份日志文件(而不是交给rsyslog服务管理),用于记录本程序运行过程中的各种事件消息。
Linux系统本身和大部分服务器程序的日志文件默认都放在目录/var/log/下,一部分程序公用一个日志文件,一部分程序使用单个日志文件,而有些大型服务器程序由于日志文件不止一个,所以会在/var/log/目录中建立相应的子目录存放日志文件。
常用的日志文件:
-
/var/log/messages : 记录Linux内核消息及各种应用程序的公共日志信息、包括启动、1/0错误、网络错误、程序故障等。
-
/var/log/cron : 记录crond计划任务产生的事件信息。
-
/var/log/dmesg : 记录Linux系统在引导过程中的各种事件信息。
-
/var/log/maillog : 记录进入或发出系统的电子邮件活动。
-
/var/log/lastlog : 记录每个用户最近的登录事件。
-
/var/log/secure : 记录用户认证相关的安全事件信息。
-
/var/log/wtmp : 记录每个用户登录、注销及系统启动和停机事件。
-
/var/log/btmp : 记录失败的、错误的登录尝试及验证事件。
内核及系统日志功能主要由默认安装rsyslog软件包提供。rsyslog服务所使用的配置文件为/etc/rsyslog.conf。
在Linux内核中,根据日志消息的重要程度不同,将其分为不同的优先级别(数字等级越小、优先级越高、消息越重要)
-
0 EMERG(紧急) : 会导致主机系统不可用的情况。
-
1 ALERT(警告) : 必须马上采取措施解决的问题。
-
2 CRIT(严重) : 比较严重的错误。
-
3 ERR(错误) : 运行出现错误。
-
4 WARNING(提醒) : 可能影响系统功能,需要提醒用户的重要事件。
-
5 NOTICE(注意) : 不会影响正常功能,但是需要注意的事件。
-
6 INFO(信息) : 一般信息。
-
7 DEBUG(调试) : 程序或系统调试信息等。
内核及大多数系统消息都被记录到公共日志文件/var/log/messages中,而其他一些程序消息被记录到各自独立的日志文件中,此外日志消息还能够记录到特定的存储设备中,或者直接发送给指定用户。
对于rsyslog服务统一管理的大部分日志文件,使用的日志记录格式基本上都相同。以公共日志/var/log/messages文件的记录格式,其中每一行表示一条日志消息,每一条消息都均包括以下四个字段。
-
时间标签 : 消息发出的日期和时间。
-
主机名 : 生成消息的计算机的名称。
-
子系统名称 : 发出消息的应用程序的名称。
-
消息 : 消息的具体内容。
在Linux系统中,一部分应用程序 并没有使用rsyslog服务来管理日志,而是由程序自己维护日志记录。
出现以下一些注意现象
-
用户在非常规的时间登录,或者用户登录系统的IP地址和以往的不一样。
-
用户登录失败的日志记录,尤其是那些一再连续尝试进入失败的日志记录。
-
非法使用或不正当使用超级用户权限。
-
无故或者非法重新启动各项网络服务的记录。
-
不正常的日志记录,日志残缺不全,或者是wtmp这样的日志文件也缺少了中间的记录文件。
一、服务器常见故障和现象
1、有关服务器无法启动的主要原因 :
①市电或电源线故障(断电或接触不良)
②电源或电源模组故障
③内存故障(一般伴有报警声)
④CPU故障(一般也会有报警声)
⑤主板故障
⑥其它插卡造成中断冲突
二、服务器无法启动
1、检查电源线和各种I/O接线是否连接正常。
2、检查连接电源线后主板是否加电。
3、将服务器设为最小配置(只接单颗cpu,最少的内存,只连接显示器和键盘)直接短接主板开关跳线,看看是否能够启动。
4、检查电源,将所有的电源接口拔下,将电源的主板供电口的绿线和黑线短接,看看电源是否启动。
5、如果判断电源正常,则需要用替换法来排除故障,替换法是在最小化配置下先由最容易替换的配件开始替换(内存、cpu、主板)
三、系统频繁重启 ?
1、造成系统频繁重启的原因:
①电源故障(替换法判断解决)
②内存故障(可从BIOS错误报告中查出)
③网络端口数据流量过大(工作压力过大)
④软件故障(更新或重装操作系统解决)
四、服务器死机故障判断处理:
服务器死机故障比较难以判断,一般分为软件和硬件两个方面。
1、第一方面-软件故障
①首先检查操作系统的系统日志,可以通过系统日志来判断部分造成死机的原因。
②电脑病毒的原因。
③系统软件的bug或漏洞造成的死机,这种故障需要在判断硬件无故障后做出,而且需要软件提供商提供帮助。
④软件使用不当或系统工作压力过大,可以请客户适当降低服务器的工作压力来看看是否能够解决
2、第二方面-硬件故障
①硬件冲突
②电源故障或电源供电不足,可以通过对比计算服务器电源所有的负载功率的值来作出判断。
③硬盘故障(通过扫描硬盘表面来检查是否有坏道)
④内存故障(可以通过主板BIOS中的错误报告和操作系统的报错信息来判断)
⑤主板故障(使用替换法来判断)
⑥CPU故障(使用替换法)
⑦板卡故障(一般是SCSI/RAID卡或其他pci设备也有可能造成系统死机,可用替换法判断处理)
注意:系统死机故障需要在处理完后需要在一段时间内进行一定压力的拷机测试来尽一步检查故障是否彻底解决。
五、安装操作系统时提示找不到硬盘?
1、故障原因:
无物理硬盘设备
硬盘线缆连接问题
没有安装硬盘控制器驱动或驱动不相符
六、如何获得驱动程序?
1、使用随机光盘制作相应驱动
七、为什么用正确的驱动仍然无法加载硬盘控制器驱动?
1、查看是否启用了hostraid功能。
八、新购买的一块硬盘,安装到机器上之后,机器自检无法通过?
1、将新的硬盘取下,机器是否可以自检通过;
2、检查新增加的硬盘的ID号是否与原来的硬盘的ID号相同,如果硬盘的ID号相同的话,自检将无法通过。
九、如何格式化SCSI硬盘?
1、有操作系统的情况:使用磁盘管理工具格式化;
2、无操作系统的情况:在SCSI管理控制界面格式化;
3、以ADAPTEC Raid卡为例:开机-出现CTRL+A 信息时,按CTRL+A进 入
①选中通道A
②选中SCSI UTILITY-将检测到硬盘-选中要检测的硬盘
③选中FORMAT可对硬盘进行全面格式化
④选中VERIFY可对硬盘进行检测,检查是否有坏道
注意:在格式化硬盘时不能中断或停电,不然会损坏磁盘
十、在Aisino 系列中有RAID卡机器,当其中一个硬盘不能正常工作RAID报警,但系统能正常运行,怎么办?
1、用一个新硬盘,确保容量大于或等于不能正常工作的硬盘,最好用相同型号的硬盘替换即可。
2、RAID卡相关常见故障
第一类: RAID卡本身有问题
①经常表现为RAID信息丢失,硬盘经常掉线,不能做REBUILD,开机自检时检测不到硬盘或时间长。
典型故障A:作完RAID1,安装操作系统,一切正常,但第二次重启系统时,发出报警声,经检查发现一块硬盘掉线,REBUILD后,又恢复正常,但重启后又掉线。怀疑为硬盘故障,校验硬盘后均无问题。最后更换RAID卡,故障解决。
典型故障B:机器经常死机,且有时候启动速度非常慢。观察系统日志,发现在系统启动时有这样一个错误提示:设备/devices/scsi/port0 在传输等待的时间内没有响应。更换RAID卡后,恢复正常。
第二类: 硬盘本身问题
①表现为硬盘掉线,在RAID阵列中的状态为DEAD,或者在作REBUILD时,作到某一进度就不能继续
典型故障:硬盘掉线后,做REBUILD时,作到20%时出现错误提示无法继续进行。在确认掉线硬盘,硬盘盒及SCSI电缆都能正常工作后,对在线硬盘进行校验,发现有坏道,修复硬盘,重做REBUILD,恢复正常。
第三类: 硬盘盒或模组的接触问题
①此类问题经常表现为RAID卡根本检测不到硬盘,此类问题比较简单,但在处理硬盘盒相关机器时,需要注意一些问题。
典型故障:RIAD卡中检测不到硬盘,把SCSI电缆接到主板的ULTRA160接口上,故障依旧,拔出硬盘盒(不包括硬盘盒后面的托架)更换,故障依旧,更换硬盘,还是不行。最后卸下硬盘盒后面的托架(非热插拔部分),发现后托架上80PIN接口上的一根针弯曲,校直弯针,恢复正常。
十一、在服务器上使用的SCSI硬盘,为什么硬盘的ID号不能设置为7?
1、SCSI控制器中,默认将ID=7设置为硬盘控制器占,所以硬盘的ID号不能设置为7
十二、为什么开机自检无法通过?
1、解决方法:
①机器切断电源,将机箱打开,用“COMS CLEAR”跳线的跳线帽将“COMS CLEAR”跳线的另外两个针短接(跳线参看主板说明书)
②机器加电,自检,等机器自检完闭,报CMOS已被清除,然后将机器电源关掉,把跳线复原即可
③机器重新开机
十三、物理内存插槽报错
1、解决方法:
①开机-按F2进入“SETUP”-“ADVANCED”–“MEMORY CONFIGURATION” 回车-“CLEAR DIMM ERRORS” 直接回车
十四 、远程桌面连接超出最大连接数
由于服务器默认为允许连接数为2个,如果登陆后忘记注销,而是直接关闭远程桌面的话,服务器识别此次登陆还是留在服务器端的。出现这种情况,最常见的就是重启服务器,但是,如果是高峰期,重启服务器带来的损失是显而易见的。那么此时,就可以利用mstsc/console指令进行强行登陆了。打开“运行”框,键入“mstsc/v:xxx.xxx.xxx.xxx(服务器IP)/console”,即可强行登陆到远程桌面了。
十五 、 系统端口隐患
对于服务器来说,首要保障稳定性和安全性。因此,我们仅需保证服务器最基本的功能即可,就像声卡都是默认禁止的。我们并不需要太多的功能,也不需要太多的端口支持。像一些不必要,而且风险较高的端口大可封掉。而一些必要的,又有风险的端口,比如:3389、80等端口,我们可以通过修改注册表的方法将其设置不特殊的秘密端口,这样服务器端口的安全隐患就不复存在了。
十六 、IDC服务器租用连接不上的解决方法
一、本地网络不通
首先检查一下自己的本地网络是否连通,如果本地网络不通肯定是无法连接服务器的,检查本地网络的方法大家也都比较熟悉,就不再给大家详细的介绍。
二、登录服务器的账号或密码错误
这个是是最常见的原因,连接服务器的时候需要登录账号密码,如果输入的账号密码错误会有相应的提示。遇到这种情况,可以选择找回密码,或者是联系服务器供应商解决,不过在这里提醒大家,服务器连接的账号密码要妥善保管。
三、没有相应的权限
虚拟主机和共享服务器出现权限不足的情况几率会大一些,如果是租用的独立服务器不能登录是因为这个原因,可以直接找到服务器供应商,他们一般都有相应的解决方案,比自己解决要快的多。
四、机房的网络或服务器的硬件出现了问题
这种情况是比较少见的,当然也是最不好解决的一种情况。如果是机房的网络或者服务器出现了问题,那就不仅是无法登录服务器了,就连网站也会无法正常打开。这种情况是可以检测的,通常是使用第三方软件或者是用ping命令检查,如果测试结果显示的是超时的,就说明是服务器硬件或者网络出现了问题,这个可以找到服务器供应商帮助解决的,他们是提供这样的售后服务的。
十七、LINUX停止iis占用80端口
主机的服务器使用的是APMServ,可是启动的时候会提示80端口被占用,Apache启动失败,提示某些程序占用80端口,但是检查时却不是,这样的情况很可能是因为机器上的IIS启动了,所以只要关闭IIS程序Apache就可以启动了,服务器托管怎么停止iis占用80端口?
启动IIS:
net start iisadmin (IIS的整个服务)
net start w3svc
停止IIS:
net stop iisadmin /y (会自动停止www、ftp和smtp服务)
如果用的IIS自带FTP还可以执行
net start MSFtpsvc
命令来启动FTP
步骤:
1.新建一个记事本,命名为IIS.txt
2.打开IIS.txt记事本,添加如下代码:
@echo off
net stop iisadmin /yes
net start iisadmin
net start w3svc
3.另存为IIS.bat即可,双击IIS.bat就开始批处理命令。
十八、客户无法远程链接
先测试一下能不能远程连接那台服务器,如果能,说明客户的网络有问题;不能远程连接,先ping一下服务器的IP,不能ping通,就查看此IP是否被封,没有被封,接显示器查看服务器的IP、掩码、网关、DNS、防火墙、端口号、远程连接是否开启。如果IP能ping通,则查看一下远程连接是否开启,如果配置正常,客户不能远程链接,可能超过了最大连接数,需要重启清除掉连接记录,还是不能解决,及时上级汇报,尽量减少客户损失。
十九、服务器丢包严重
查看流量监控图,服务器有没有超过峰值,有没有被限速,有没有IP被攻击,然后ping问题服务器的IP,询问运营商流量问题,查看是否丢包严重。
二十、排除系统启动类故障——MBR扇区故障
1)备份MBR扇区数据
由于MBR扇区中包含了整个硬盘的分区表记录,因此该扇区的备份文件必须存放到其他的存储设备中,否则在恢复时将无法读取到备份文件。
[root@localhost ~]# mkdir /backup
[root@localhost ~]# mount /dev/sda3 /backup/
[root@localhost ~]# dd if=/dev/sda of=/backup/sda.mbr.bak bs=512 count=1
记录了1+0 的读入
记录了1+0 的写出
512字节(512 B)已复制,0.00029813 秒,1.7 MB/秒2)模拟MBR扇区故障
使用dd命令,人为的将MBR扇区的记录覆盖,模拟出MBR扇区被损坏的故障情况(切记先做好备份,而且将备份文件存放到其他硬盘)。
[root@localhost ~]# dd if=/dev/zero of=/dev/sda bs=512 count=1
记录了1+0 的读入
记录了1+0 的写出
512字节(512 B)已复制,0.00141057 秒,363 kB/秒完成上述操作后重启系统,将会出现“Operating system not found”的提示信息,表示无法找到可用的操作系统,因此无法启动主机。
3)从备份文件中恢复MBR扇区数据
当出现安装向导界面,选择“Rescue installed system”,将以“急救模式”引导光盘中的Linux系统。
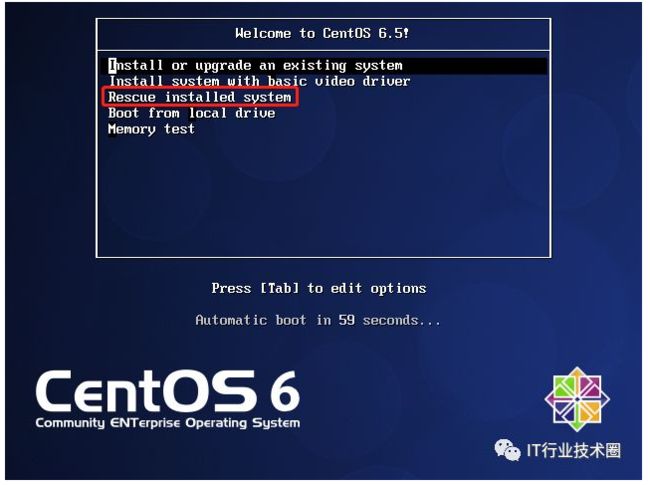
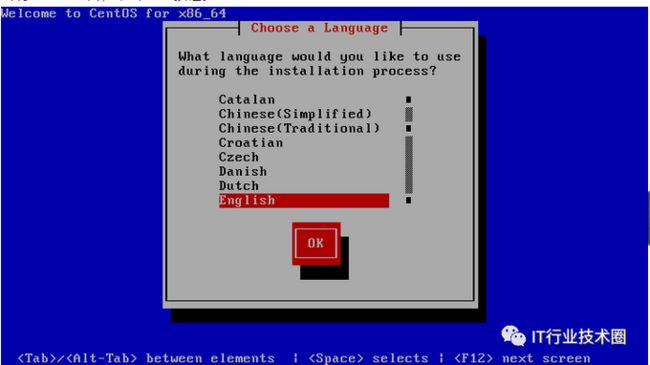
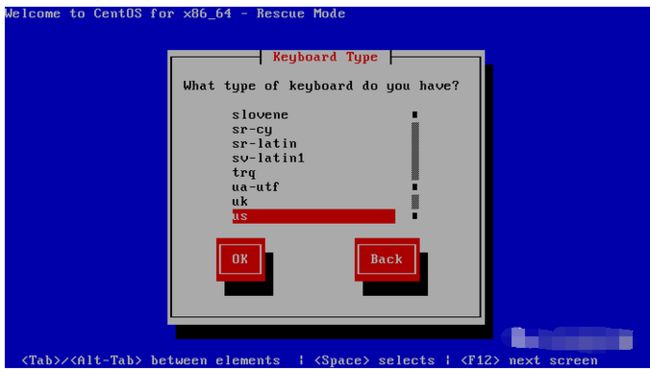
之后依次按Enter键接受默认的语言、键盘格式,提示是否配置网卡时一般选择“NO”,然后系统会自动查找硬盘中的Linux分区并尝试将其挂载到“/mnt/sysimage”目录(选择“Continue”确认并继续)。会出现rescue窗口,单击“OK”按钮。

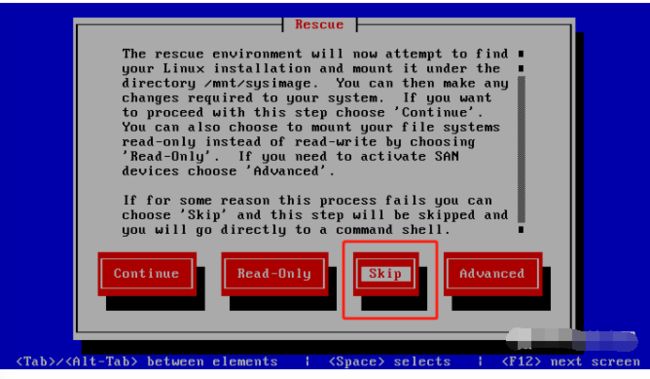
单击“Skip”键后将进入到“bash-4.1#”提示符的Bash Shell环境,只要执行相应的命令挂载保存有备份文件的硬盘分区,并将数据恢复到硬盘“/dev/sda”中。
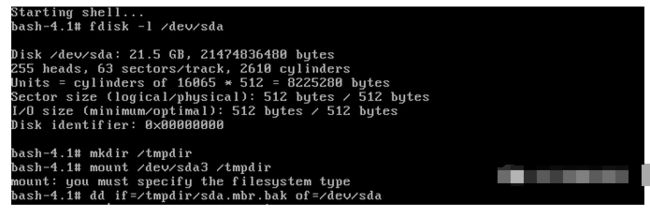
完成恢复后,执行“exit”命令退出临时shell环境,执行“reboot”命令,系统将会自动重启。
二十一、
二十二、
二十三、
注 意 :
重启服务器的好处
一般来说,如果是正常的重启是没有什么坏处,相反,对于操作系统而言反而有好处。重启服务器可以清除内存碎片,重新优化软件调用级别,中断无用的网络端口等。
1、重启服务器对服务器的保养有一定的作用,释放内存,缓解CPU压力。服务器运行时间长,会造成很多冗余的DLL程序,导致系统运行速度较慢。系统重启会使电脑恢复到默认加载状态,也就是说在还未重启时的很多应用程序进程都驻留在内存中,会使电脑变慢,重启后它们就没了。
2、还有就是有的一些对电脑的配置要重新启动后才能生效。
3、重启服务器可以使有些程序可以得到更新。
重启服务器的危害
1、正在进行写硬盘操作时,即硬盘灯在不停地闪动时,断电或者强制重启,对硬盘的伤害较大。
2、热启动(CTRL+ALT+DEL),对硬件上不会有损伤(软件上有时会发生程序非法中止导致数据丢失的问题);如果是冷启动(直接开关电源),就会对硬件尤其是硬盘造成伤害。除非无法正常关机可以考虑热启动。
3、重启的突然来电会有大量电流涌入电源,反复进行会使机器寿命大大降低,而且在硬盘正在读写的时候突然地断电也非常容易引起硬盘出现坏道从而损失数据。
4.非正常重启的危害:首先,这样轻则会使硬盘掉数据,造成逻辑坏道,重则造成物理的坏道,损坏硬盘磁头伺服电路。还有,这也会造成主板的二度伤害,主板在一通一断当中对电路部分的冲击是比较大的。再则也会对电源造成一定的损害。
重启
1、有外网IP
碰到服务器重启,先确定服务器的位置,如果设备有外网IP,先长ping外网IP,找到设备后,重启设备,重启时,需要等电源灯全灭之后,停顿2-3S再开启服务器,如果IP显示断过又通了,说明重启好了/完毕。
1、没有外网IP
直接接显示器重启,因为无法在外部测试设备的连通性,接显示器,设备重启到登录界面,设备重启已经完成。
系统负载
-
问题一:Cpu 负载高,IO 负载低
1. 内存不够2. 磁盘性能差3. SQL 问题 ------> 去数据库层,进一步排查 SQL 问题4. IO 出问题了(磁盘到临界了、Raid 设计不好、Raid 降级、锁、在单位时间内 TPS 过高)5. TPS 过高: 大量的小数据 IO、大量的全表扫描
-
问题二:IO 负载高,Cpu 负载低
大量小的 IO 写操作1. autocommit,产生大量小 IO。2. IO/PS,磁盘的一个定值,硬件出厂的时候,厂家定义的一个每秒最大的 IO 次数。大量大的 IO 写操作1. SQL 问题的几率比较大。
-
问题三:IO 和 Cpu 负载都很高
1. 硬件不够了或 SQL 存在问题。
基础优化
优化思路
定位问题点
硬件 --> 系统 --> 应用 --> 数据库 --> 架构(高可用、读写分离、分库分表)
处理方向
明确优化目标、性能和安全的折中、防患未然。
硬件优化
-
主机方面
1. 根据数据库类型,主机 CPU 选择、内存容量选择、磁盘选择。
2. 平衡内存和磁盘资源。
3. 随机的 I/O 和顺序的 I/O。
4. 主机 RAID卡的 BBU (Battery Backup Unit) 关闭。
-
Cpu 的选择
Cpu 的两个关键因素:核数、主频,根据不同的业务类型进行选择:
1. Cpu 密集型:计算比较多,OLTP-->主频很高的 Cpu、核数还要多。
2. IO 密集型:查询比较多,OLAP-->核数要多,主频不一定高的。
-
内存的选择
1. OLAP 类型数据库,需要更多内存,和数据获取量级有关。
2. OLTP 类型数据一般内存是 Cpu 核心数量的 2 倍到 4 倍,没有最佳实践。
-
存储方面
1. 根据存储数据种类的不同,选择不同的存储设备。
2. 配置合理的 RAID 级别(Raid5、Raid10、热备盘)。
3. 对于操作系统来讲,不需要太特殊的选择,最好做好冗余(Raid 1)(SSD、SAS 、SATA)
4. Raid卡:主机 Raid 卡选择:
4.1 实现操作系统磁盘的冗余(Raid 1)。
4.2 平衡内存和磁盘资源。
4.3 随机的 I/O 和顺序的 I/O。
4.4 主机 Raid卡的 BBU (Battery Backup Unit) 要关闭。
-
网络设备方面
使用流量支持更高的网络设备(交换机、路由器、网线、网卡、HBA卡)。
注意:以上这些规划应该在初始设计系统时就应该考虑好。
服务器硬件优化
1、物理状态灯。
2、自带管理设备:远程控制卡(FENCE 设备:IPMI、ILO、IDARC),开关机、硬件监控。
3、第三方的监控软件、设备(Snmp、Agent)对物理设施进行监控。
4、存储设备:自带的监控平台。EMC2(HP 收购了)、日立(hds)、IBM低端 OEM hds,高端存储是自己技术,华为存储。
系统优化
-
Cpu
基本不需要调整,在硬件选择方面下功夫即可。
-
内存
基本不需要调整,在硬件选择方面下功夫即可。
-
Swap
MySQL 尽量避免使用 Swap。
阿里云的服务器中默认 Swap 为 0 。
-
IO
Raid、No LVM、 Ext 4 或 XFS、SSD、IO 调度策略。
-
Swap 调整方法
要关闭 Swap 分区,可使用以下方法。
1. 临时关闭方法
修改 /proc/sys/vm/swappiness 的内容改成 0 。2. 永久关闭方法
/etc/sysctl.conf 文件中添加 vm.swappiness=0 。
这个参数决定了 Linux 是倾向于使用 Swap,还是倾向于释放文件系统 Cache。在内存紧张的情况下,数值越低越倾向于释放文件系统 Cache。
当然,这个参数只能减少使用 Swap 的概率,并不能避免 Linux 使用 Swap。
如何处理内网、外网的数据交互的同时保障网络安全?
网络安全系统主要依靠防火墙、网络防病毒系统等技术在网络层构筑一道安全屏障,并通过把不同的产品集成在同一个安全管理平台上实现网络层的统一、集中的安全管理。
网络层安全平台
选择网络层安全平台时主要考虑这个安全平台能否与其他相关的网络安全产品集成,能否对这些安全产品进行统一的管理,包括配置各相关安全产品的安全策略、维护相关安全产品的系统配置、检查并调整相关安全产品的系统状态等。
一个完善的网络安全平台至少需要部署以下产品:
防火墙、网络的安全核心提供边界安全防护和访问权限控制;
网络防病毒系统、杜绝病毒传播提供全网同步的病毒更新和策略设置提供全网杀毒。
安全网络拓扑结构划分
防火墙主要是防范不同网段之间的攻击和非法访问。由于攻击的对象主要是各类计算机,所以要科学地划分计算机的类别来细化安全设计。在整个内网当中,根据用途可以将计算机划分为三类:内部使用的工作站与终端,对外提供服务的应用服务器,以及重要数据服务器。这三类计算机的作用不同,重要程度不同,安全需求也不同。
第一、重点保护各种应用服务器,特别是要保证数据库服务的代理服务器的绝对安全,不能允许用户直接访问。对应用服务器则要保证用户的访问是受到控制的要能够限制能够访问该服务器的用户范围使其只能通过指定的方式进行访问。
第二、数据服务器的安全性要大于对外提供多种服务的WWW服务器、E-mail服务器等应用服务器。所以数据库服务器在防火墙定义的规则上要严于其他服务器。
第三、内部网络有可能会对各种服务器和应用系统的直接的网络攻击,所以内部办公网络也需要和代理服务器、对外服务器、WWW、E-mail等隔离开。
第四、不能允许外网用户直接访问内部网络。
上述安全需求需要通过划分出安全的网络拓扑结构,并通过VLAN划分、安全路由器配置和防火墙网关的配置来控制不同网段之间的访问控制。划分网络拓扑结构时,一方面要保证网络的安全;另一方面不能对原有网络结构做太大的更改。为此建议采用以防火墙为核心的支持非军事化区的三网段安全网络拓扑结构。
兆端口模式能否实现POE供电?用a或b标准打的线是否可以跑千兆?
按照a或者b标准打的线能跑千兆,但是8芯线必须全部互通(因为百兆只要两端的1326互通就可以了)
POE供电方式有两种:一种是两对线传输信息,两对线供电;另一种方式是线对即传输信息又输送电源。POE供电主要取决于网络设备的功能,传输线路没有问题。
IDC数据机房机柜专用PDU如何布局规划?
IDC机房PDU规划布局建议考虑如下原则:
(1)服务器主机、存储设备、服务器机柜宜分区布置,主机、存储设备、服务器机柜及UPS、空调机等设备应按产品要求留出检修空间,允许相邻设备的维修间距部分重叠。
(2)设备之间走道净宽不应小于1200mm,才可以包装充足的安装检修空间。
(3)划分阶段进入机房的设备及预留扩充设备的相对位置,既要符合计算机系统的工艺流程,又要方便今后扩充设备的进场就位及线缆的连接。
(4)服务器机柜侧面可无间距排列,并柜,以便于强、弱电线(缆)的敷设。每排机柜之间的距离最好符合地板模数,以避免机柜前后出现小于30Omm的补边地板。
(5)放置发热量较大的服务器如IBM690、670等服务器机柜时,其机柜前面之间的净距离不应小于2.lm,以免热密度太高从而影响设备的散热。
(6)设备较多的服务器机房建议列头柜方式,使综合布线线缆汇集到列头柜而不是核心柜从而节省双绞线与光纤,同时便于使用二级网络交换设备,也便于安装使用服务于某列机柜的KVM系统。
(7)新风机的安装位置应保证新风是取自室外新鲜、清洁的空气,新风人口应不影响大楼外观,迸风口下缘距室外地坪不宜小于2m;当新凤入口设在绿化地带时,进风口下缘不宜小于lm,以减少尘埃污染,延缓空气过滤器的清洗时间,延长空气过滤器的寿命。
(8)机房精密空调机在有效送风距离内,送风方向应与设备排列方向一致;采用地板下送风方式时,空调机送风方向应与地板下强、弱电线槽顺向布置的方向一致,以减少空调系统的阻力、充分发挥空调系统效率。
(9)排风机安装位置应保证其排风口高于新风入口并避免送风、排风短路。
(10)新风管道的送风口位置应使新风与空调机回风充分混合。
(11)配电柜布置宜靠近末端负载以减少线缆,方便维护管理。
(12)应有畅通的疏散通道。
(13)鉴于市场上主流服务器及服务器机柜的散热方式大多数为前后向通风方式,因此前后向通风的服务器机柜宜采用面对面、背靠背的布置方式。在机柜正面布置地板送风口,使气流形成冷热通道,以减少前排机柜排出的热气流对后排机柜的影响,充分发挥空调系统的效能。
直流UPS系统和传统交流UPS系统相比哪个更节能?
直流UPS 产品由交流配电单元、整流模块、蓄电池、直流配电单元、电池管理单元及监控模块组成,适用于工矿企业、教育、商务、银行、证劵等行业、计算机、服务器、办公自动化设备、安防监控等设备,还可应用于医疗和网络设备。在交流掉电或故障时能不间断地给设备提供稳定的后备电源,保证设备能正常工作一段时间,保存相关重要数据。
其产品效率、带载能力、可靠性相对交流UPS有大幅度的提高,但价格却比交流UPS便宜,输入电源转换过程零间断,保证负载良好稳定的工作。
直流UPS系统有效的节能只有1-6%范围。
在数据中心机房内Fiber Channel布线有何特殊要求?
在数据中心机房内光缆通道主要用于万兆网络,选用时注意以下几点:
传输距离:OM3多模光纤为300m-550m,单模光纤为10-40km
采用光纤的连接器件和适配器为SC、LC或按照网络设备的端口类型选用
如果采用敞开的电缆桥架敷设方式光缆要达到相应的防火等级(A级或B级机房)
光配线模块的设置位置(如设备机柜顶部、敞开式桥架上、布线列头柜及各种配线机柜内)
网络检测通过,但连接PC显示网络断开?
这钟问题主要从以下几方面检查
1.网线水晶头是否全通
2.pc端或墙端接触不良
3.对应的交换机接口有问题,也就这些吧
电源故障的原因示例
供电设备故障 1、突然高负载用电,导致电闸跳闸
2、启动时电流过高导致电压波动
3、设备老化导致输出功率下降
4、输电装置或电子设备的开关等发生"电力噪声";
雷电导致的故障 1、输电系统故障导致停电(可用UPS应对)
2、因避雷设施机制引发的瞬间停电和电力变弱
3、雷电引发的电力噪声
4、因雷电引发的电压异常徒增与电流异常徒增(雷电浪涌电流)(需要使用防浪涌电流装置)
人为引起的 故障 1、故意或不小心切断电源缆线导致跳闸
2、预先通知了的、由于施工或检查等商业原因的停电
CPU使用率上升的主要原因 :
- 用户通信量处理增多。
- 出现突发通信量。
- 用量(sizing,即关于路由器能够处理的带宽和用户数量等规模的预计设计)不合适,网络设备处理应接不暇。
当CPU的使用率很高,会引起以下问题。
- 性能下降,使通过该设备的用户数据响应迟缓。
- 设备上运行的业务无法正常响应,进而会导致以下问题。
Telnet/SSH响应迟缓,或设备无法进行Telnet/SSH连接。
控制端口响应迟缓。
设备上网络接口对ping命令的应答迟缓甚至无应答。
无法进行更新路由等管理类的通信交互。
- 缓存发生故障的概率高。
在路由器中使用的主要工具软件包 : ping、Traceroute、telnet、ssh、rlogin、ftp、tftp;
路由器使用的内存种类 : ROM 、RAM、 NVRAM、闪存。
启动路由器的流程 :
1、通电后会执行保存在ROM中的POST(上电自检)程序。该步骤主要识别物理接口等设备上的部件。完成对硬件的检测。
2、当POST执行完毕后,执行在ROM中保存的bootstrap程序,
3、检索闪存内的IOS镜像,并将其加载到RAM中。
4、IOS启动后在NVRAM中检索startup-config信息,如果存在该文件则将以running-config的形式在RAM中展开。当设备刚出厂,在NVRAM中不存在start-config时,则通过
一个 EXT3 的文件分区,当使用 touch test.file 命令创建一个新文件时报错,报错的信息是提示磁盘已满,但是采用 df -h 命令查看磁盘大小时,只使用了,60%的磁盘空间, 为什么会出现这个情况,说说你的理由。
答:两种情况,一种是磁盘配额问题,另外一种就是 EXT3 文件系统的设计不适合很多小文件跟大文件的一种文件格式,出现很多小文件时,容易导致 inode 耗尽了。
当文件系统受到破坏时,如何检查和修复系统?
参考答案:
成功修复文件系统的前提是要有两个以上的主文件系统,并保证在修复之前首先卸载将被修复的文件系统。
使用命令 fsck 对受到破坏的文件系统进行修复。fsck 检查文件系统分为 5 步每一步检查系统不同部分的连接特性并对上一步进行验证和修改。在执行 fsck 命令时,检查首先从超级块开始,然后是分配的磁盘块、路径名、目录的连接性、链接数目以及空闲块链表、i-node。
某 Linux 主机的/etc/rc.d/rc.inet1 文件中有如下语句,请修正错误,并解释其内容。
/etc/rc.d/rc.inet1:
……
ROUTE add –net default gw 192.168.0.101 netmask 255.255.0.0 metric 1
ROUTE add –net 192.168.1.0 gw 192.168.0.250 netmask 255.255.0.0 metric 1
参考答案:
修正错误:
(1)ROUTE 应改为小写:route;(2)netmask 255.255.0.0 应改为:netmask
255.255.255.0;
(3)缺省路由的子网掩码应改为:netmask 0.0.0.0;
(4)缺省路由必须在最后设定,否则其后的路由将无效。
解释内容:
(1)route:建立静态路由表的命令;(2)add:增加一条新路由;
(3)-net 192.168.1.0:到达一个目标网络的网络地址;
(4)default:建立一条缺省路由;(5)gw 192.168.0.101:网关地址;
(6)metric 1:到达目标网络经过的 路由器 数(跳数)。
某 Linux 主机的/etc/rc.d/rc.inet1 文件中有如下语句,请修正错误,并解释其内容。
/etc/rc.d/rc.inet1:
……
ROUTE add –net default gw 192.168.0.101 netmask 255.255.0.0 metric 1
ROUTE add –net 192.168.1.0 gw 192.168.0.250 netmask 255.255.0.0 metric 1
参考答案:
修正错误:
(1)ROUTE 应改为小写:route;(2)netmask 255.255.0.0 应改为:netmask
255.255.255.0;
(3)缺省路由的子网掩码应改为:netmask 0.0.0.0;
(4)缺省路由必须在最后设定,否则其后的路由将无效。
解释内容:
(1)route:建立静态路由表的命令;(2)add:增加一条新路由;
(3)-net 192.168.1.0:到达一个目标网络的网络地址;
(4)default:建立一条缺省路由;(5)gw 192.168.0.101:网关地址;
(6)metric 1:到达目标网络经过的 路由器 数(跳数)
参考链接 :
浅谈 MySQL 优化实施方案 : https://mp.weixin.qq.com/s/-lru6FAhkXTo7gLCCfWlyg
企业数据中心运维应该掌握 13 件事 :https://mp.weixin.qq.com/s/QkoUZfNWXgCiSNOYm6ufcg