python读取.edf文件
目录
- EDF文件简介
- MNE-python读取.edf文件 案例
- 第一步:导入工具包
- 第二步:加载本地edf文件
- 第三步:获取原始数据中事件
- 第四步:根据事件ID获取对应事件
- 第五步:绘制事件图
本教程为脑机学习者Rose原创(转载请联系作者授权)发表于公众号:脑机接口社区(微信号:Brain_Computer).QQ交流群:903290195

EDF文件简介
EDF,全称是 European Data Format,是一种标准文件格式,用于交换和存储医疗时间序列。
该格式文件能够存储多通道的数据,允许每个信号拥有不同的采样频率。
在内部,它包括标题和一个或多个数据记录。标题包含一些一般信息(患者标识,开始时间…等等)以及每个信号的技术规格(校准,采样率,过滤,…等等),编码为 ASCII 字符。数据记录包含小端 16 位整数的样本。因此,EDF 也是多导睡眠图(PSG)录音的流行格式。
MNE-python读取.edf文件 案例
python读取edf文件,可以通过mne实现
方法原型:
方法原型:
mne.io.read_raw_edf(input_fname,
montage='deprecated',
eog=None,
misc=None,
stim_channel='auto',
exclude=(),
preload=False,
verbose=None)
"""
input_fname:edf文件存放地址
montage='deprecated':已弃用
eog:通道名称或应指定为EOG通道的索引列表。值应对应于文件中的电极。默认为无。
misc:通道名称或应指定为MISC通道的索引列表。值应对应于文件中的电极。默认为无。
stim_channel:默认为"auto",这意味着将名为“status”或“trigger”(不区分大小写)的通道设置为STIM。
如果为str(或str列表),则所有与名称匹配的通道均设置为STIM;
如果为int(或int列表),则将对应于索引的通道设置为STIM。
exclude:要排除的频道名称。这在读取具有不同采样率的数据时会有所帮助,以避免不必要的重采样。
preload:如果为True,则数据将被预加载到内存中(这样可以加快数据的索引);
如果preload是字符串,则该字符串为数据存放在硬盘中的路径地址(速度较慢,需要较少的内存)。
"""
读取edf文件:Affaf Ikram 20121020 1839.L1.edf
第一步:导入工具包
from mne.io import concatenate_raws, read_raw_edf
import matplotlib.pyplot as plt
import mne
第二步:加载本地edf文件
raw=read_raw_edf("Affaf Ikram 20121020 1839.L1.edf",preload=False)
第三步:获取原始数据中事件
查看原始edf文件中保存的event id以及events
events_from_annot, event_dict = mne.events_from_annotations(raw)
print(event_dict)
print(events_from_annot)

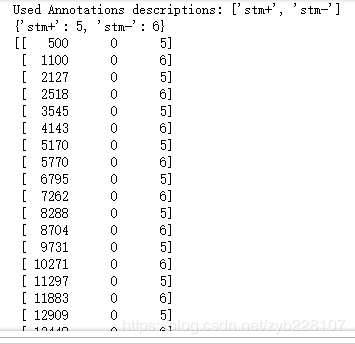
如上图可以发现,事件ID有1,2,3,4,5,6
每个ID对应着注释:[‘TRSP’, ‘bgin’, ‘fix+’, ‘resp’, ‘stm+’, ‘stm-’]
共有517个事件
第四步:根据事件ID获取对应事件
下面只选取事件ID为5和6的所对应的事件
custom_mapping = {'stm+':5, 'stm-': 6}
(events_from_annot,
event_dict) = mne.events_from_annotations(raw, event_id=custom_mapping)
print(event_dict)
print(events_from_annot)
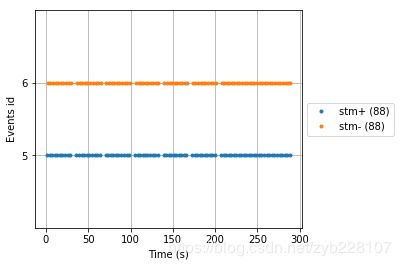
第五步:绘制事件图
fig = mne.viz.plot_events(events_from_annot, sfreq=raw.info['sfreq'],
first_samp=raw.first_samp, event_id=event_dict)
fig.subplots_adjust(right=0.7)
epochs = mne.Epochs(raw, events=events_from_annot,
event_id=event_dict)
epochs.plot_image()

"""
获取采样频率sfreq
知识点:
“采样频率,也称为采样速度或者采样率,定义了每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。
采样频率的倒数是采样周期或者叫作采样时间,它是采样之间的时间间隔。
通俗的讲采样频率是指计算机每秒钟采集多少个信号样本。”
"""
sfreq=raw.info['sfreq']
"""
获取索引为m到n的样本,每个样本从第k次到第h次.
data,times=raw[m:n,k:h]
其中data为索引为m到n的样本,每个样本从第k次到第h次.
times是以第k次采样的时间作为开始时间,第h次采样时的时间为结束时间的时间数组。
"""
data,times=raw[:3,int(sfreq*1):int(sfreq*3)]
plt.plot(times,data.T)
plt.title("Sample channels")

参考
python读取.edf文件
脑机学习者Rose笔记分享,QQ交流群:903290195
更多分享,请关注公众号
