
随着柯洁与AlphaGo结束以后,大家是不是对人工智能的底层奥秘越来越有兴趣?
深度学习已经在图像分类、检测等诸多领域取得了突破性的成绩。但是它也存在一些问题。
首先,它与传统的机器学习方法一样,通常假设训练数据与测试数据服从同样的分布,或者是在训练数据上的预测结果与在测试数据上的预测结果服从同样的分布,而实际上这两者存在一定的偏差。另一个问题是深度学习的模型(比如卷积神经网络)有时候并不能很好地学到训练数据中的一些特征。深度对抗学习(deep adversarial learning)就是为了解决上述问题而被提出的一种方法。
学习的过程可以看做是我们要得到一个模型,为了建模真实的数据分布,生成器学习生成实际的数据样本,而鉴别器学习确定这些样本是否是真实的。如果这个鉴别器的水平很高,而它无法分清它们之间的区别,那么就说明我们需要的模型具有很好的表达或者预测能力。
本文回顾了从传统机器学习,到wGAN的逻辑发展过程,让读者对历史发展有个清晰的认识,并提供了wGAN的代码实现,是一篇很好的学习wGAN的入门材料。
作者 | Michael Dietz
编译 | AI100(rgznai100)
对抗学习是深度学习中最火的一个领域。网站arxiv-sanity的最近最流行的研究领域列表上,许多都是对抗学习,本文同样也是一篇讲对抗学习的文章。
在这篇文章中,我们主要学习以下三个方面的内容:
1. 为什么我们应该关注对抗学习
2. 生成对抗网络GANs(General Adversarial Networks) 和 它面临的挑战
3. 能解决这些挑战的Wasserstein GAN和 改进的稳定训练Wasserstein GAN的方法,还包括了代码实现。
从传统机器学习到深度学习
我在UIUC上“模拟信号与系统”课程的时候,教授在一开始就信誓旦旦的说:“这个课程将是你们上的最重要的课程,抽象是工程里面最重要的概念。”
康奈尔大学的课程里面也有“解决复杂问题的方法就是抽象,也就是隐藏细节信息。抽象屏蔽掉无用的细节。为了设计一个复杂系统,你必须找出哪些是你想暴露给其他人的,哪些是你想隐藏起来的。暴露给其他人的部分,其他人可以进行设计。暴露的部分就是抽象。”
深度神经网络中的每层就是数据的抽象表示,层和层之间有依赖关系,最终形成一个层次结构。每一层都是上一层的一个更高级的抽象。给定一组原始数据和要解决的问题,然后定义一个目标函数来评估网络输出的答案,最终神经网络就能通过学习到一个最优的解。
因此,特征是神经网络自己学习得来的。但是在传统的机器学习中,特征和算法都是人工定义的。
现在的数据的特征、结构、模式都是网络自我学习的,而不是像传统机器学习那样人工定义。所以以前无法实现的AI的算法现在可行了,并且在某些方面超过了人类。
从深度学习到深度对抗学习
很多年前,我学习过拳击。我的拳击教练不让新手问问题,说新手不知道问什么问题,连问的问题都是错误的,会得到没用的答案,会专注于错误的东西,越学越错。
Robert Half说过“会问问题和会解题一样,都需要一定的水平”
对抗学习的奇妙之处在于所有的东西都是从数据中学习得到的,包括要解决的问题,最终的答案以及评估答案的标准—目标函数。传统的深度学习中,是由人来决定要解决什么问题,人来决定用什么目标函数做评估。
Deep‘ Mind公司用AlphaGo证明了深度对抗学习的厉害之处。在围棋比赛中,AlphaGo可以自己创造新的下法和招数。这开创了围棋的新纪元,突破了过去几千年的一个瓶颈,达到了新的高度。AlphaGo能做到这点是因为它能自己给自己打分,可以随时计算当前的局势的分数,而不用预先人工定义和预编程。这样,AlphaGo自己和自己下了几百万局的比赛。听起来很像对抗学习吧?
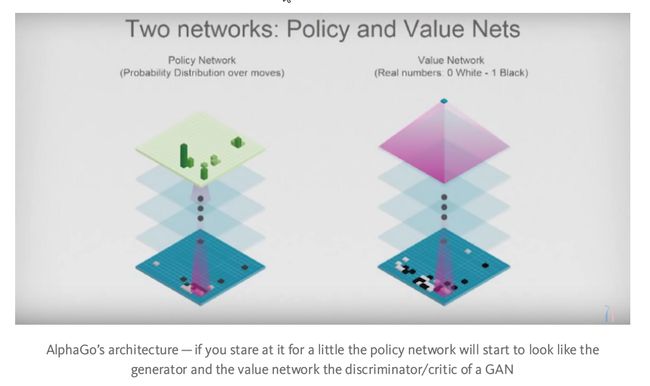
AlphaGo不仅仅是暴力破解,而是真正掌握了围棋比赛,学到了围棋的招式。之所以这样,是因为它没有被人类束缚,既没有得到人类先验的输入,也不受我们对问题域理解的局限。无法想象,当我们把这些成果应用到实际生活中,AI会如何改造农业、医疗等等。但是这一定会发生。
生成对抗网络GAN
Richard Feynman说“如果要真正理解一个东西,我们必须要能够把它创造出来。”
正是这句话激励着我开始学习GANs。GANs的训练过程就是两个神经网络自己在作对抗,通过对抗不断的学习。当然学习是在原始数据的基础上学习。
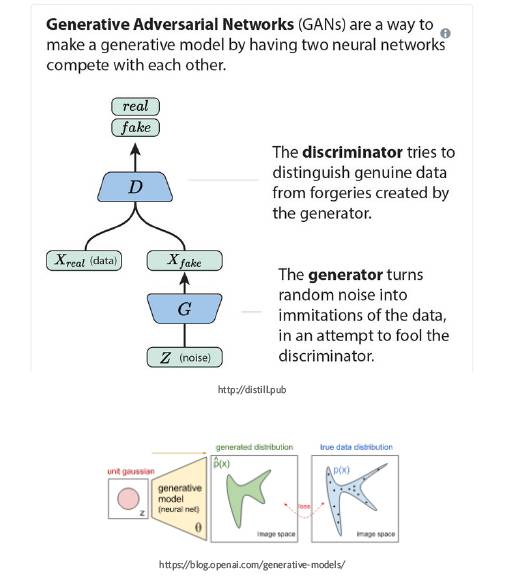
生成器通过对原始数据的分布进行建模,学习如何生成近似数据;而判别器用来判断数据是生成器生成的数据还是原始的真实的数据。这样生成器就能重新创造出原始数据的近似。我们相信为了能够理解一个东西,我们要能重新创造这个东西,所以GAN是非常有价值的,我们的努力也是值得的。
如果我们能成功使得GAN达到纳什均衡(完美的判别器也不能识别数据到底是真实数据还是生成数据),我们就能够把这个成果应用到几乎任何事情上,并且还能够有最好的性能。
存在的问题
GANs很难优化,并且训练过程不稳定。网络结构必须设计的非常好,生成器和判别器之间必须有个很好的协调,才能使得训练过程收敛。这些问题中,最显著的就是失去样本多样性(mode dropping, 即生成器只从很小一部分的数据集中学习)。还有由于GANs的学习曲线基本没什么意义,因此很难调试。
虽然如此,仍然通过GANs得到了最先进的一些成果。但是就是因为这些问题,GANs的应用被限制住了。
解决方法
Alex J. Champandard说“一个月内,传统的训练GANs的方法会被当做黑暗时代的方法”。
GANs的训练目标是生成数据和真实数据的分布的距离差的最小化。
最开始使用的是Jensen-Shannon散度。但是,Wasserstein GAN(wGAN)文章在理论和实际两个方面,都证明了最小化推土距离EMD(Earth Mover’s distance)才是解决上述问题的最优方法。当然在实际计算中,由于EMD的计算量过大,因此使用的是EMD的合理的近似值。
为了使得近似值有效,wGAN在判别器(在wGAN中使用了critic一词,和GAN中的discriminator是同一个意思)中使用了权重剪裁(weight clipping)。但是正是权重剪裁导致了上述的问题。
后来对wGAN的训练方法进行了改进,它通过在判别器引入梯度惩罚(gradient penalty)使得训练稳定。梯度惩罚只要简单的加到总损失函数中的Wasserstein距离就可以了。
历史上第一次,终于可以训练GAN而几乎不用超参数调优了。其中包括了101层的残差网络和基于离散数据的语言模型。
Wasserstein距离的一个优势就是当判别器改进的时候,生成器能收到改进的梯度。但是在使用Jensen-Shannon散度的时候,当判别器改进的时候,产生了梯度消失,生成器无法学习改进。这个也是产生训练不稳定的主要原因。
如果想对这个理论有深入理解,我建议读一下下面两个文章:
①Wasserstein GAN
②Wasserstein GANs的改进的训练方法
随着新的目标函数的引入,我看待GANs的方式也发生了变化:
传统的GAN(Jensen-Shannon散度)下,生成器和判别器是竞争关系,如下图。

在wGAN(Wasserstein距离)下,生成器和判别器是协作关系,如下图。

代码实现
结论
对抗学习的网络不受我们对问题域理解的任何限制,没有任何先验知识,网络就是从数据中学习。
下一篇文章中,我们将利用生成器学习得到的数据表示来进行图像分类。
文章点评
非监督学习是通往真正人工智能的方向。GAN能自己生成特征、问题、评估函数,是近年来深度学习的一个突破。而wGAN解决了GAN已有的问题,“一个月内改变行业”。是最新的深度学习的发展。当然本文虽然介绍了历史的逻辑演进,但是介绍过于简单,还需要阅读更多的文章来进一步理解。
原文地址
