全网最详细yolov1-yolov3原理
YOLOv3原理
YOLO发展概述
2015 年,R-CNN 横空出世,目标检测 DL 世代大幕拉开。
各路豪杰快速迭代,陆续有了 SPP,fast,faster 版本,至 R-FCN,速度与精度齐飞,区域推荐类网络大放异彩。
奈何,未达实时检测之,难获工业应用之青睐。
此时,凭速度之长,网格类检测异军突起,先有 YOLO,继而 SSD,更是摘实时检测之桂冠,与区域推荐类二分天下。然却时遭世人诟病。
遂有 JR 一鼓作气,并 coco,推 v2,增加输出类别,成就 9000。此后一年,作者隐遁江湖,逍遥 twitter。偶获灵感,终推 v3,横扫武林!
YOLO不断吸收同化对手,进化自己,提升战斗力:YOLOv1 吸收了 SSD 的长处(加了 BN 层,扩大输入维度,使用了 Anchor,训练的时候数据增强),进化到了 YOLOv2;
吸收 DSSD 和 FPN 的长处,仿 ResNet 的 Darknet-53,仿 SqueezeNet 的纵横交叉网络,又进化到 YOLO 第三形态。
但是,我相信这一定不是最终形态。让我们拭目以待吧!
YOLO v1~v3的设计历程
Yolov1
这是继RCNN,fast-RCNN和faster-RCNN之后,rbg(RossGirshick)针对DL目标检测速度问题提出的另外一种框架。YOLO V1其增强版本GPU中能跑45fps,简化版本155fps。
论文下载:http://arxiv.org/abs/1506.02640
代码下载:https://github.com/pjreddie/darknet
深入理解:https://www.jianshu.com/p/cad68ca85e27
1. 核心思想
将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。
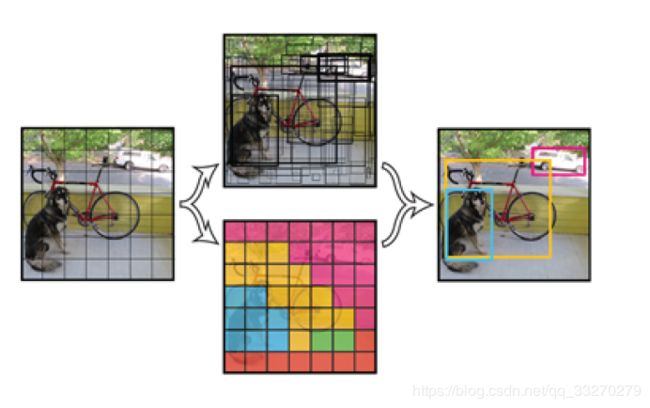
每个网格要预测B个bounding box(不是预先设置好的,而是运算出来的,不同于Faster RCNN所采用的Anchor,参考:https://www.jianshu.com/p/cad68ca85e27),每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息,其值是这样计算的:
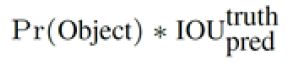
其中如果有object落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。
每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。
注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
映射关系如下图:
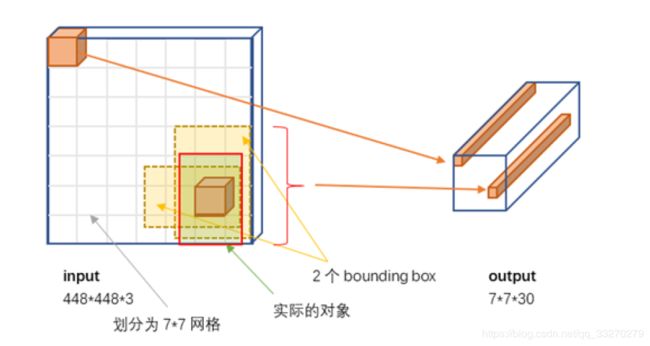
举例说明: 在PASCAL VOC中,图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。
2. 网络结构
YOLOv1网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module(inception网络介绍:http://baijiahao.baidu.com/s?id=1601882944953788623&wfr=spider&for=pc),而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。YOLOv1网络在最后使用全连接层进行类别输出,因此全连接层的输出维度是 S×S×(B×5+C)。

在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
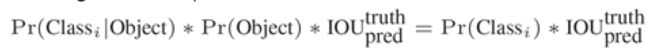
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
注:
*由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。
*虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
3. Loss函数
每个grid有30维,这30维中,8维是回归box的坐标,2维是box的confidence,还有20维是类别。
其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。作者简单粗暴的全部采用了sum-squared error loss来做这件事。
这种做法存在以下几个问题:
第一,8维的localization error和20维的classification error同等重要显然是不合理的;
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决办法:
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为λcoord在pascal VOC训练中取5。
对没有object的box的confidence loss,赋予小的loss weight,记为λnoobj在pascal VOC训练中取0.5。 有object的box的confidence loss和类别的loss的loss weight正常取1。
对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样。
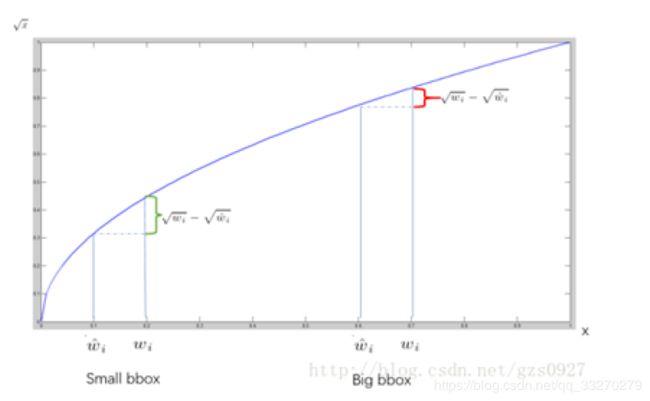
为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。这个参考下面的图很容易理解,小box的横轴值较小,发生偏移时,反应到y轴上相比大box要大。(也是个近似逼近方式)
一个网格预测多个box,希望的是每个box predictor专门负责预测某个object。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。这种做法称作box predictor的specialization。
最后整个的损失函数如下所示:

这个损失函数中:
只有当某个网格中有object的时候才对classification error进行惩罚。
只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大。
注:
*YOLO方法模型训练依赖于物体识别标注数据,因此,对于非常规的物体形状或比例,YOLO的检测效果并不理想。
*YOLO采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。
* YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
4. 训练过程
1)预训练。使用 ImageNet 1000 类数据训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
2)用步骤1)得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用 VOC 20 类标注数据进行YOLO模型训练。检测通常需要有细密纹理的视觉信息,所以为提高图像精度,在训练检测模型时,将输入图像分辨率从224 × 224 resize到448x448。
训练时B个bbox的ground truth设置成相同的.
5 .总结
· YOLO对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
· 同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱。
· 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
· YOLO与Fast R-CNN相比有较大的定位误差,与基于region proposal的方法相比具有较低的召回率。但是,YOLO在定位识别背景时准确率更高,而 Fast-R-CNN 的假阳性很高。基于此作者设计了 Fast-R-CNN + YOLO 检测识别模式,即先用R-CNN提取得到一组bounding box,然后用YOLO处理图像也得到一组bounding box。对比这两组bounding box是否基本一致,如果一致就用YOLO计算得到的概率对目标分类,最终的bouding box的区域选取二者的相交区域。这种组合方式将准确率提高了3个百分点。
Yolov2
为提高物体定位精准性和召回率,YOLO作者提出了 《YOLO9000: Better, Faster, Stronger》。相比v1提高了训练图像的分辨率;引入了faster rcnn中anchor box的思想,对网络结构的设计进行了改进,输出层使用卷积层替代YOLO的全连接层,联合使用coco物体检测标注数据和imagenet物体分类标注数据训练物体检测模型。相比YOLO,YOLO9000在识别种类、精度、速度、和定位准确性等方面都有大大提升。
首先讲一下这篇文章一共介绍了YOLO v2和YOLO9000两个模型,二者略有不同。前者主要是YOLO的升级版,后者的主要检测网络也是YOLO v2,同时对数据集做了融合,使得模型可以检测9000多类物体。而提出YOLO9000的原因主要是目前检测的数据集数据量较小,因此利用数量较大的分类数据集来帮助训练检测模型。
原文下载:https://arxiv.org/pdf/1612.08242v1.pdf
工程代码:http://pjreddie.com/darknet/yolo/
1. 核心思想
YOLO与Fast R-CNN相比有较大的定位误差,与基于region proposal的方法相比具有较低的召回率。因此YOLO v2主要改进是提高召回率和定位能力。下面是改进之处:
Batch Normalization
使用Batch Normalization对网络进行优化,让网络提高了收敛性,同时还消除了对其他形式的正则化(regularization)的依赖。通过对YOLO的每一个卷积层增加Batch Normalization,最终使得mAP提高了2%,同时还使model正则化。使用Batch Normalization可以从model中去掉Dropout,而不会产生过拟合。
High resolution classifier
目前业界标准的检测方法,都要先把分类器(classifier)放在ImageNet上进行预训练。从Alexnet开始,大多数的分类器都运行在小于256256的图片上。而现在YOLO从224224增加到了448448,这就意味着网络需要适应新的输入分辨率。
为了适应新的分辨率,YOLO v2的分类网络以448448的分辨率先在ImageNet上进行Fine Tune,Fine Tune10个epochs,让网络有时间调整他的滤波器(filters),好让其能更好的运行在新分辨率上,还需要调优用于检测的Resulting Network。最终通过使用高分辨率,mAP提升了4%。
Convolution with anchor boxes
YOLO一代包含有全连接层,从而能直接预测Bounding Boxes的坐标值。 Faster R-CNN的方法只用卷积层与Region Proposal Network来预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。
所以最终YOLO去掉了全连接层,使用Anchor Boxes来预测 Bounding Boxes。作者去掉了网络中一个Pooling层,这让卷积层的输出能有更高的分辨率。收缩网络让其运行在416416而不是448448。由于图片中的物体都倾向于出现在图片的中心位置,特别是那种比较大的物体,所以有一个单独位于物体中心的位置用于预测这些物体。YOLO的卷积层采用32这个值来下采样图片,所以通过选择416416用作输入尺寸最终能输出一个1313的Feature Map。 使用Anchor Box会让精确度稍微下降,但用了它能让YOLO能预测出大于一千个框,同时recall达到88%,mAP达到69.2%。
Dimension clusters
之前Anchor Box的尺寸是手动选择的,所以尺寸还有优化的余地。 为了优化,在训练集(training set)Bounding Boxes上跑了一下k-means聚类,来找到一个比较好的值。如果我们用标准的欧式距离的k-means,尺寸大的框比小框产生更多的错误。因为我们的目的是提高IOU分数,这依赖于Box的大小,所以距离度量的使用:

通过分析实验结果(Figure 2),左图:在model复杂性与high recall之间权衡之后,选择聚类分类数K=5。右图:是聚类的中心,大多数是高瘦的Box。Table1是说明用K-means选择Anchor Boxes时,当Cluster IOU选择值为5时,AVG IOU的值是61,这个值要比不用聚类的方法的60.9要高。选择值为9的时候,AVG IOU更有显著提高。总之就是说明用聚类的方法是有效果的。

Direct location prediction
用Anchor Box的方法,会让model变得不稳定,尤其是在最开始的几次迭代的时候。大多数不稳定因素产生自预测Box的(x,y)位置的时候。按照之前YOLO的方法,网络不会预测偏移量,而是根据YOLO中的网格单元的位置来预测坐标,这就让Ground Truth的值介于0到1之间。而为了让网络的结果能落在这一范围内,网络使用一个 Logistic Activation来对于网络预测结果进行限制,让结果介于0到1之间。 网络在每一个网格单元中预测出5个Bounding Boxes,每个Bounding Boxes有五个坐标值tx,ty,tw,th,t0,他们的关系见下图(Figure3)。假设一个网格单元对于图片左上角的偏移量是cx,cy,Bounding Boxes Prior的宽度和高度是pw,ph,那么预测的结果见下图右面的公式:

因为使用了限制让数值变得参数化,也让网络更容易学习、更稳定。
Dimension clusters和Direct location prediction,improves YOLO by almost 5% over the version with anchor boxes.
Fine-Grained Features
YOLO修改后的Feature Map大小为1313,这个尺寸对检测图片中尺寸大物体来说足够了,同时使用这种细粒度的特征对定位小物体的位置可能也有好处。Faster R-CNN、SSD都使用不同尺寸的Feature Map来取得不同范围的分辨率,而YOLO采取了不同的方法,YOLO加上了一个Passthrough Layer来取得之前的某个2626分辨率的层的特征。这个Passthrough layer能够把高分辨率特征与低分辨率特征联系在一起,联系起来的方法是把相邻的特征堆积在不同的Channel之中,这一方法类似与Resnet的Identity Mapping,从而把2626512变成13132048。YOLO中的检测器位于扩展后(expanded )的Feature Map的上方,所以他能取得细粒度的特征信息,这提升了YOLO 1%的性能。
Multi-ScaleTraining
作者希望YOLO v2能健壮的运行于不同尺寸的图片之上,所以把这一想法用于训练model中。区别于之前的补全图片的尺寸的方法,YOLO v2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352……608},最小320320,最大608608,网络会自动改变尺寸,并继续训练的过程。这一政策让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高,所以你可以在YOLO v2的速度和精度上进行权衡。
Figure4,Table 3:在voc2007上的速度与精度

2. 网络结构
分类网络
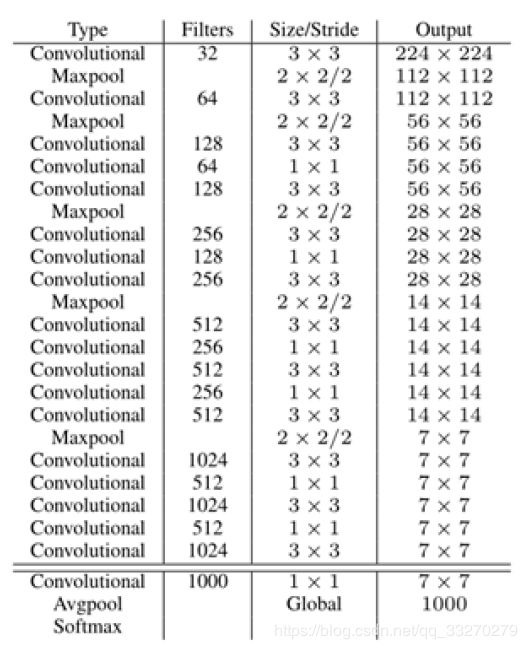
YOLOv2提出了一种新的分类模型Darknet-19.借鉴了很多其它网络的设计概念.主要使用3x3卷积并在pooling之后channel数加倍(VGG);global average pooling替代全连接做预测分类,并在3x3卷积之间使用1x1卷积压缩特征表示(Network in Network);使用 batch normalization 来提高稳定性,加速收敛,对模型正则化.
Darknet-19的结构如下表:
检测网络
在分类网络中移除最后一个1x1的层,在最后添加3个3x3x1024的卷积层,再接上输出是类别个数的1x1卷积。对于输入图像尺寸为Si x Si,最终3x3卷积层输出的feature map是Oi x Oi(Oi=Si/(2^5)),对应输入图像的Oi x Oi个栅格,每个栅格预测#anchors种boxes大小,每个box包含4个坐标值,1个置信度和#classes个条件类别概率,所以输出维度是Oi x Oi x#anchors x (5 + #classes)。
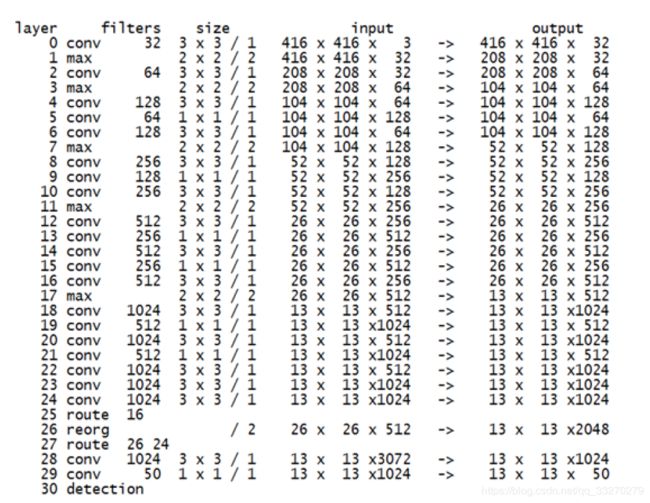
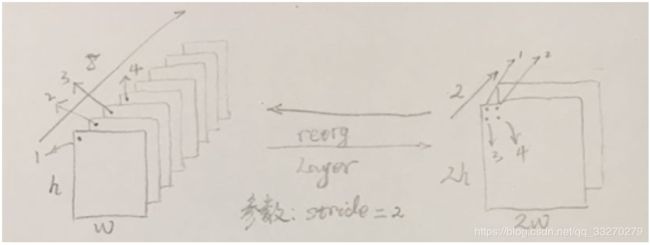
添加跨层跳跃连接(借鉴ResNet等思想),融合粗细粒度的特征:将前面最后一个3x3x512卷积的特征图,对于416x416的输入,该层输出26x26x512,直接连接到最后新加的三个3x3卷积层的最后一个的前边.将26x26x512变形为13x13x1024与后边的13x13x1024特征按channel堆起来得到13x13x3072.从yolo-voc.cfg文件可以看到,第25层为route层,逆向9层拿到第16层26 * 26 * 512的输出,并由第26层的reorg层把26 * 26 * 512 变形为13 * 13 * 2048,再有第27层的route层连接24层和26层的输出,堆叠为13 * 13 * 3072,由最后一个卷积核为3 * 3的卷积层进行跨通道的信息融合并把通道降维为1024。
网络结构如下(输入416,5个类别,5个anchor box; 此结构信息由Darknet框架启动时输出):
Reorg层的实现方式:
3. Loss函数
yolov2损失计算的源代码集中在region_layer.c文件forward_region_layer函数中,为了兼顾坐标、分类、目标置信度以及训练效率,损失函数由多个部分组成,且不同部分都被赋予了各自的损失权重,整体计算公式如下。

W,H指的是特征图(13x13)的宽和高,A指每个网格单元(cell)对应的anchor box的数目(5),各种\lambda表示各类损失的权重。
详见:(https://blog.csdn.net/ChuiGeDaQiQiu/article/details/81229245 )
4. 训练过程
Training for classification
网络训练在 ImageNet 1000类分类数据集,训练了160epochs,使用随机梯度下降,初始学习率为0.1, polynomial rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9 。训练期间使用标准的数据扩大方法:随机裁剪、旋转、变换颜色(hue)、变换饱和度(saturation), 变换曝光度(exposure shifts)。在训练时,把整个网络在更大的448*448分辨率上Fine Turnning 10个 epoches,初始学习率设置为0.001,这种网络达到达到76.5%top-1精确度,93.3%top-5精确度。
Training for detection
网络去掉了最后一个卷积层,而加上了三个33卷积层,每个卷积层有1024个Filters,每个卷积层紧接着一个11卷积层, with the number of outputs we need for detection。
对于VOC数据,网络预测出每个网格单元预测五个Bounding Boxes,每个Bounding Boxes预测5个坐标和20类,所以一共125个Filters,增加了Passthough层来获取前面层的细粒度信息,网络训练了160epoches,初始学习率0.001,dividing it by 10 at 60 and 90 epochs,a weight decay of 0.0005 and momentum of 0.9,数据扩大方法相同,对COCO与VOC数据集的训练对策相同。
5. 数据增强
在训练的过程中,当网络遇到一个来自检测数据集的图片与标记信息,那么就把这些数据用完整的YOLO v2 loss功能反向传播这个图片。当网络遇到一个来自分类数据集的图片和分类标记信息,只用整个结构中分类部分的loss功能反向传播这个图片。
但是检测数据集只有粗粒度的标记信息,像“猫“、“ 狗”之类,而分类数据集的标签信息则更细粒度,更丰富。比如狗这一类就包括”哈士奇“”牛头梗“”金毛狗“等等。所以如果想同时在监测数据集与分类数据集上进行训练,那么就要用一种一致性的方法融合这些标签信息。
再者,用于分类的方法,大多是用softmax layer方法,softmax意味着分类的类别之间要互相独立的。而盲目地混合数据集训练,就会出现比如:检测数据集的分类信息中”狗“这一分类,在分类数据集合中,就会有的不同种类的狗”哈士奇“”牛头梗“”金毛“这些分类,这两种数据集之间的分类信息不相互独立。所以使用一种多标签的model来混合数据集,假设一个图片可以有多个分类信息,并假定分类信息必须是相互独立的规则可以被忽略。
Hierarchical classification
WordNet的结构是一个直接图表(directed graph),而不是树型结构。因为语言是复杂的,狗这个词既属于‘犬科’又属于‘家畜’两类,而‘犬科’和‘家畜’两类在wordnet中则是同义词,所以不能用树形结构。
作者希望根据ImageNet中包含的概念来建立一个分层树,为了建立这个分层树,首先检查ImagenNet中出现的名词,再在WordNet中找到这些名词,再找到这些名词到达他们根节点的路径(在这里设为所有的根节点为实体对象(physical object))。在WordNet中,大多数同义词只有一个路径,所以首先把这条路径中的词全部都加到分层树中。接着迭代地检查剩下的名词,并尽可能少的把他们添加到分层树上,添加的原则是取最短路径加入到树中。
为了计算某一结点的绝对概率,只需要对这一结点到根节点的整条路径的所有概率进行相乘。所以比如你想知道一个图片是否是Norfolk terrier的概率,则进行如下计算:

为了验证这一个方法,在WordTree上训练Darknet19的model,使用1000类的ImageNet进行训练,为了建立WordtTree 1K,把所有中间词汇加入到WordTree上,把标签空间从1000扩大到了1369。在训练过程中,如果有一个图片的标签是”Norfolk terrier“,那么这个图片还会获得”狗“(dog)以及“哺乳动物”(mammal)等标签。总之现在一张图片是多标记的,标记之间不需要相互独立。
如Figure5所示,之前的ImageNet分类是使用一个大softmax进行分类。而现在,WordTree只需要对同一概念下的同义词进行softmax分类。
使用相同的训练参数,这种分层结构的Darknet19达到71.9%top-1精度和90.4%top-5精确度,精度只有微小的下降。
这种方法的好处:在对未知或者新的物体进行分类时,性能降低的很优雅(gracefully)。比如看到一个狗的照片,但不知道是哪种种类的狗,那么就高置信度(confidence)预测是”狗“,而其他狗的种类的同义词如”哈士奇“”牛头梗“”金毛“等这些则低置信度。
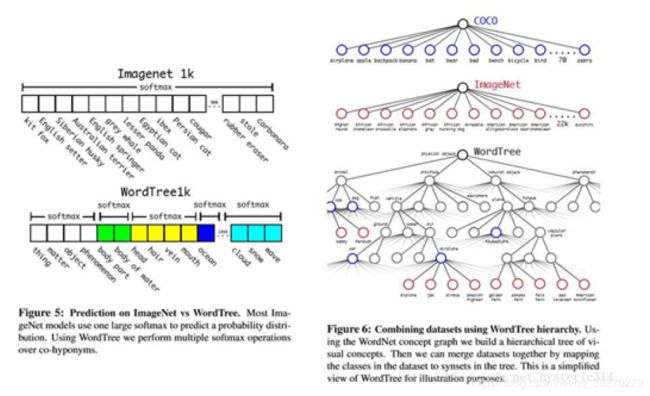
Datasets combination with wordtree
用WordTree 把数据集合中的类别映射到分层树中的同义词上,例如上图Figure 6,WordTree混合ImageNet与COCO。
Joint classification and detection
作者的目的是:训练一个Extremely Large Scale检测器。所以训练的时候使用WordTree混合了COCO检测数据集与ImageNet中的Top9000类,混合后的数据集对应的WordTree有9418个类。另一方面,由于ImageNet数据集太大了,作者为了平衡一下两个数据集之间的数据量,通过过采样(oversampling)COCO数据集中的数据,使COCO数据集与ImageNet数据集之间的数据量比例达到1:4。
YOLO9000的训练基于YOLO v2的构架,但是使用3priors而不是5来限制输出的大小。当网络遇到检测数据集中的图片时则正常地反方向传播,当遇到分类数据集图片的时候,只使用分类的loss功能进行反向传播。同时作者假设IOU最少为 .3。最后根据这些假设进行反向传播。
使用联合训练法,YOLO9000使用COCO检测数据集学习检测图片中的物体的位置,使用ImageNet分类数据集学习如何从大量的类别中进行分类。
为了评估这一方法,使用ImageNet Detection Task对训练结果进行评估。
评估结果:
YOLO9000取得19.7mAP。
在未学习过的156个分类数据上进行测试,mAP达到16.0。
YOLO9000的mAP比DPM高,而且YOLO有更多先进的特征,YOLO9000是用部分监督的方式在不同训练集上进行训练,同时还能检测9000个物体类别,并保证实时运行。
虽然YOLO9000对动物的识别性能很好,但是对类别为”sungalsses“或者”swimming trunks“这些衣服或者装备的类别,它的识别性能不是很好,见table 7。这跟数据集的数据组成有很大关系。

6. 总结
YOLO v2 代表着‘目前最先进’物体检测的水平,在多种监测数据集中都要快过其他检测系统,并可以在速度与精确度上进行权衡。
YOLO 9000 的网络结构允许实时地检测超过9000种物体分类,这归功于它能同时优化检测与分类功能。使用WordTree来混合来自不同的资源的训练数据,并使用联合优化技术同时在ImageNet和COCO数据集上进行训练,YOLO9000进一步缩小了监测数据集与识别数据集之间的大小代沟。
文章还提出了WordTree,数据集混合训练,多尺寸训练等全新的训练方法。
Yolov3
YOLOv3在Pascal Titan X上处理608x608图像速度达到20FPS,在 COCO test-dev 上 [email protected] 达到 57.9%,与RetinaNet(FocalLoss论文所提出的单阶段网络)的结果相近,并且速度快4倍.
YOLO v3的模型比之前的模型复杂了不少,可以通过改变模型结构的大小来权衡速度与精度。
速度对比如下:
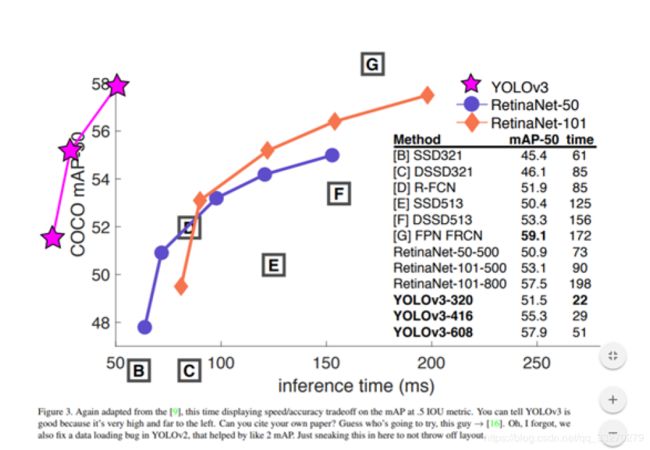
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
相关代码:https://github.com/pjreddie/darknet
1. 核心思想
沿用:
yolo_v3作为yolo系列目前最新的算法,对之前的算法既有保留又有改进。先分析一下yolo_v3上保留的东西:
1.“分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
2.采用"leaky ReLU"作为激活函数。
3.端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
4.从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
5.多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
改进:
\1. 多级预测
终于为 YOLO 增加了 top down 的多级预测,解决了 YOLO 颗粒度粗,对小目标无力的问题。
v2 只有一个 detection,v3 一下变成了 3 个,分别是一个下采样的,feature map 为 1313,还有 2 个的 eltwise sum,feature map 为 2626,52*52,也就是说 v3 的 416 版本已经用到了 52 的 feature map,而 v2 把多尺度考虑到训练的 data 采样上,最后也只是用到了 13 的 feature map,这应该是对小目标影响最大的地方。
在论文中从单层预测五种 boundingbox 变成每层 3 种 boundongbox。
\2. loss不同
作者 v3 替换了 v2 的 softmax loss 变成 logistic loss,由于每个点所对应的 bounding box 少并且差异大,每个 bounding 与 ground truth 的 matching 策略变成了 1 对 1。
当预测的目标类别很复杂的时候,采用 logistic regression 进行分类是更有效的,比如在 Open Images Dataset 数据集进行分类。
在这个数据集中,会有很多重叠的标签,比如女人、人,如果使用 softmax 则意味着每个候选框只对应着一个类别,但是实际上并不总是这样。复合标签的方法能对数据进行更好的建模。(softmax理解:https://blog.csdn.net/bitcarmanlee/article/details/82320853 )
\3. 加深网络
采用简化的 residual block 取代了原来 1×1 和 3×3 的 block(其实就是加了一个 shortcut,也是网络加深必然所要采取的手段)。
这和上一点是有关系的,v2 的 darknet-19 变成了 v3 的 darknet-53,为啥呢?就是需要啊,层的数量自然就多了,另外作者还是用了一连串的 33、11 ,33 的增加 channel,而 11 的在于压缩 3*3 后的特征表示。
\4. Router
由于 top down 的多级预测,进而改变了 router(或者说 concatenate)时的方式,将原来诡异的 reorg 改成了 upsample。
2. 网络结构
Yolov3 的网络结构:
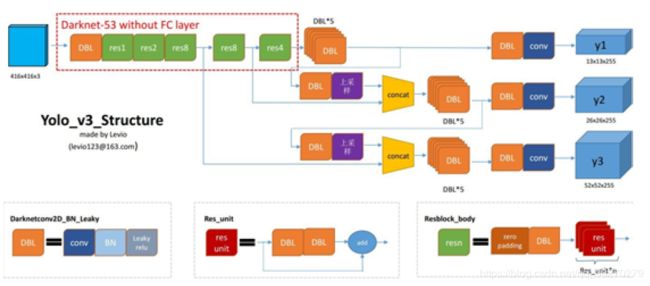
DBL: 如图1左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
resn**:**n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
concat**:**张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
Darknet53****基础网络:

整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,即1/32。输入为416x416,则输出为13x13(416/32=13)。yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。
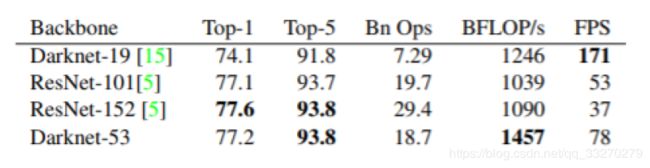
这个新网络在性能上远超Darknet-19 ,但是在效率上同样由于ResNet-101和ResNet-152。下表是在ImageNet上的实验结果:
3. loss 函数
对掌握Yolo来讲,loss function不可谓不重要。在v3的论文里没有明确提所用的损失函数,确切地说,yolo系列论文里面只有yolo v1明确提了损失函数的公式。对于yolo这样一种讨喜的目标检测算法,就连损失函数都非常讨喜。在v1中使用了一种叫sum-square error的损失计算方法,就是简单的差方相加而已。我们知道,在目标检测任务里,有几个关键信息是需要确定的:
(x,y),(w,h),class,confidence
根据关键信息的特点可以分为上述四类,损失函数应该由各自特点确定。最后加到一起就可以组成最终的loss_function了,也就是一个loss_function搞定端到端的训练。可以从代码分析出v3的损失函数,同样也是对以上四类,不过相比于v1中简单的总方误差,还是有一些调整的:
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[…, 0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[…, 2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[…, 4:5], from_logits=True) + (1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[…, 4:5], from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[…, 5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
以上是一段keras框架描述的yolo v3 的loss_function代码。忽略恒定系数不看,可以从上述代码看出:除了w, h的损失函数依然采用总方误差之外,其他部分的损失函数用的是二值交叉熵。最后加到一起。那么这个binary_crossentropy又是个什么玩意儿呢?就是一个最简单的交叉熵而已(交叉熵参考:https://blog.csdn.net/tsyccnh/article/details/79163834),一般用于二分类,这里的两种二分类类别可以理解为"对和不对"这两种。关于binary_crossentropy的公式详情可参考博文《常见的损失函数》(https://blog.csdn.net/legalhighhigh/article/details/81409551)。
4. 训练过程
边界框预测
在YOLO9000之后,我们的系统使用维度聚类(dimension cluster)作为anchor box来预测边界框[13]。网络为每个边界框预测4个坐标,tx,ty,tw,th。如果单元格从图像的左上角偏移了(cx,cy)并且先验边界框具有宽度和高度pw,ph,则预测对应以下等式:
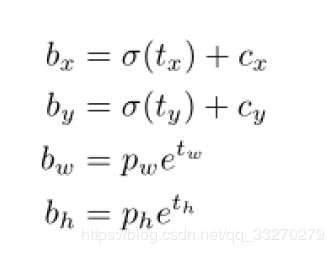
在训练期间,我们使用平方误差损失的和。如果一些坐标预测的ground truth是 ,梯度就是ground truth值(从ground truth box计算出来)减去预测,即: 。 通过翻转上面的方程可以很容易地计算出这个ground truth值。
YOLOv3使用逻辑回归来预测每个边界框的 objectness score。如果边界框比之前的任何其他边界框都要与ground truth的对象重叠,则该值应该为1。如果先前的边界框不是最好的,但确实与ground truth对象重叠超过某个阈值,我们会忽略该预测,如Faster R-CNN一样。我们使用.5作为阈值。不同的是,我们的系统只为每个ground truth对象分配一个边界框。如果先前的边界框未分配给一个ground truth对象,则不会对坐标或类别预测造成损失,只会导致objectness。

图: 具有dimension priors和location prediction的边界框。我们预测了框的宽度和高度,作为cluster centroids的偏移量。我们使用sigmoid函数预测相对于滤波器应用位置的边界框的中心坐标。这个图是从YOLO9000论文[13]拿来的。
类别预测
每个框使用多标签分类来预测边界框可能包含的类。我们不使用softmax,因为我们发现它对于性能没有影响,而是只是使用独立的逻辑分类器。在训练过程中,我们使用二元交叉熵损失来进行类别预测。
这个公式有助于我们转向更复杂的领域,如Open Images数据集[5]。在这个数据集中有许多重叠的标签(例如,Woman和Person)。使用softmax强加了一个假设,即每个box只包含一个类别,但通常情况并非如此。多标签方法可以更好地模拟数据。
训练
我们仍然用完整的图像进行训练。我们使用不同scale进行训练,使用大量的数据增强,批规范化,等等。我们使用Darknet神经网络框架进行训练和测试。
5. Darknet框架
Darknet 由 C 语言和 CUDA 实现, 对GPU显存利用效率较高(CPU速度差一些, 通过与SSD的Caffe程序对比发现存在CPU较慢,GPU较快的情况). Darknet 对第三方库的依赖较少,且仅使用了少量GNU linux平台C接口,因此很容易移植到其它平台,如Windows或嵌入式设备。
能看出来作者是有野心的,Darknet不只是一个目标检测应用,它还是一个完全基于 C 语言的通用架构,以及很多以此为基础的应用,比如:
基于 RNN 的莎士比亚戏剧剧本自动生成器:

基于的 darknet 版阿法狗(DarkGo):
基于 GAN 的 darknet 版 Deep Dream(Nightmare):

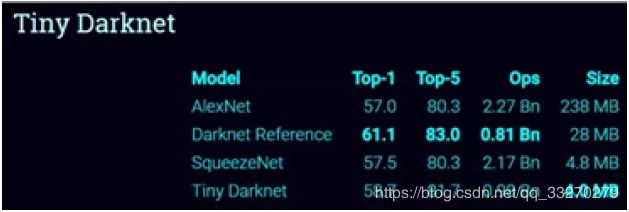
挑战 SqueezeNet 的压缩网络 TinyYOLO(Redmon 号称后者比前者更快、小、准)。
当然,做得最好的还是目标检测。