好文推荐 | etcd 问题、调优、监控
点击上方“朱小厮的博客”,选择“设为星标”
后台回复"加群",加入新技术

来源:www.xuyasong.com/?p=1983
etcd 原理解析:读《etcd 技术内幕》这篇文章主要是原理性的内容,本文主要是实践角度,谈谈平时用到的一些操作和监控。
高可用
etcd 是基于 raft算法的分布式键值数据库,生来就为集群化而设计的,由于Raft算法在做决策时需要超半数节点的投票,所以etcd集群一般推荐奇数节点,如3、5或者7个节点构成一个集群。
以上是etcd集群部署的基础概念,但是还需要注意以下问题:
选主过程
etcd 是高可用的,允许部分机器故障,以标准的3 节点etcd 集群,最大容忍1台机器宕机,下面以最简单的leader宕机来演示raft 的投票逻辑,以实际的运行日志来验证并理解。更多的场景可以看之前的原理解析
场景:正常运行的三台etcd:100、101、102。当前任期为 7,leader 为 101机器。现在使101 宕机
宕机前:101 为 leader,3 个 member
宕机后:102 成为新 leader,2 个 member

过程:
将 101 机器的 etcd 停止,此时只剩 2 台,但总数为 3
101停止etcd 的运行
102(91d63231b87fadda) 收到消息,发现101(8a4bb0af2f19bd46)心跳超时,于是发起了新一轮选举,任期为 7+1=8
91d63231b87fadda [term 7] received MsgTimeoutNow from 8a4bb0af2f19bd46 and starts an election to get leadership.
102(91d63231b87fadda)成为新一任的候选人,然后自己投给了自己,获得 1 票
91d63231b87fadda became candidate at term 8
91d63231b87fadda received MsgVoteResp from 91d63231b87fadda at term 8
102(91d63231b87fadda)发送给 挂掉的101 和 另一个100,希望他们也投给自己
91d63231b87fadda [logterm: 7, index: 4340153] sent MsgVote request to 8a4bb0af2f19bd46 at term 8
91d63231b87fadda [logterm: 7, index: 4340153] sent MsgVote request to 9feab580a25dd270 at term 8
102 肯定收不到 101 的回应,因为 101 已经挂掉
etcd[24203]: lost the TCP streaming connection with peer 8a4bb0af2f19bd46 (stream MsgApp v2 reader)
100 (9feab580a25dd270)收到了 102 的拉票消息,因为任期 8 大于当前100机器所处的 7,于是知道是发起了新的一轮选举,因此回应 101,我给你投票。这里任期term是关键,也就是说,100 和 102 谁先感受到 101 宕机,发起投票,谁就是新的 leader,这个也和进程初始的启动时间有关。
9feab580a25dd270 [term: 7] received a MsgVote message with higher term from 91d63231b87fadda [term: 8]
9feab580a25dd270 became follower at term 8
9feab580a25dd270 [logterm: 7, index: 4340153, vote: 0] cast MsgVote for 91d63231b8
9feab580a25dd270 elected leader 91d63231b87fadda at term 8
102 获得了 2 票,一票是自己,一票是 100,超过半数,成为新的 leader。任期为 8
91d63231b87fadda elected leader 91d63231b87fadda at term 8
更换完成
必须是奇数节点吗
etcd官方推荐3、5、7个节点,虽然raft算法也是半数以上投票才能有 leader,但奇数只是推荐,其实偶数也是可以的。如 2、4、8个节点。分情况说明:
1 个节点:就是单实例,没有集群概念,不做讨论
2 个节点:是集群,但没人会这么配,这里说点废话:双节点的etcd能启动,启动时也能有主,可以正常提供服务,但是一台挂掉之后,就选不出主了,因为他只能拿到1票,剩下的那台也无法提供服务,也就是双节点无容错能力,不要使用。
2节点正常运行:
1台宕机后:
3 节点:标准的3 节点etcd 集群只能容忍1台机器宕机,挂掉 1 台的逻辑上边已经演示过,如果再挂 1 台,就和 2节点的情形一致了,一直选,一直增加任期,但就是选不出来,服务也就不可用了
4 节点:最大容忍1 台
5 节点:最大容忍 2 台
6 节点:最大容忍 2 台
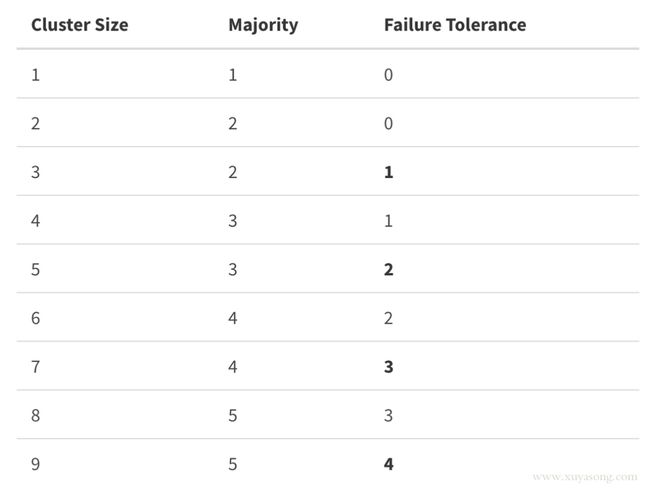
你会发现偶数节点虽然多了一台机器,但是容错能力是一样的,也就是说,你可以设置偶数节点,但没增加什么能力,还浪费了一台机器。同时etcd 是通过复制数据给所有节点来达到一致性,因此偶数的多一台机器增加不了性能,反而会拉低写入速度。
机器越多越好吗
etcd 集群是一个 Raft Group,没有 shared。所以它的极限有两部分,一是单机的容量限制,内存和磁盘;二是网络开销,每次 Raft 操作需要所有节点参与,每一次写操作需要集群中大多数节点将日志落盘成功后,Leader 节点才能修改内部状态机,并将结果返回给客户端。因此节点越多性能越低,所以扩展很多 etcd 节点是没有意义的,一般是 3、5、7, 7 个也足够了。
在 k8s 中一般是3*master机器做高可用,也就是 3节点的 etcd。也有人将 etcd独立于 k8s集群之外,来更好地扩展 etcd 集群,或者根据 k8s 的资源来拆分 etcd,如 events 放在单独的 etcd 集群中。不同的副本数视业务规模而定,3,5,7 都可以。
脑裂问题
集群化的软件总会提到脑裂问题,如ElasticSearch、Zookeeper集群,脑裂就是同一个集群中的不同节点,对于集群的状态有了不一样的理解。
etcd 中有没有脑裂问题?答案是:没有
The majority side becomes the available cluster and the minority side is unavailable; there is no “split-brain” in etcd.
以网络分区导致脑裂为例,一开始有5个节点, Node 5 为 Leader

由于出现网络故障,124 成为一个分区,35 成为一个分区, Node 5 的 leader 任期还没结束的一段时间内,仍然认为自己是当前leader,但是此时另外一边的分区,因为124无法连接 5,于是选出了新的leader 1,网络分区形成。
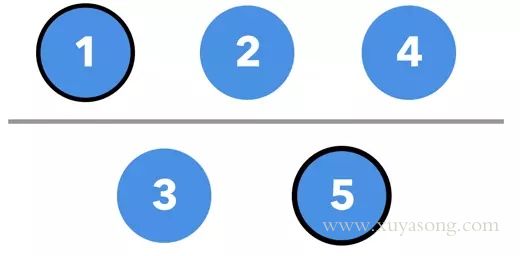
35分区是否可用?如果写入了1而读取了 5,是否会读取旧数据(stale read)?
答:35分区属于少数派,被认为是异常节点,无法执行写操作。写入 1 的可以成功,并在网络分区恢复后,35 因为任期旧,会自动成为 follower,异常期间的新数据也会从 1 同步给 35。
而 5 的读请求也会失败,etcd 通过ReadIndex、Lease read保证线性一致读,即节点5在处理读请求时,首先需要与集群多数节点确认自己依然是Leader并查询 commit index,5做不到多数节点确认,因此读失败。
因此 etcd 不存在脑裂问题。线性一致读的内容下面会提到。
etcd 是强一致性吗
是强一致性,读和写都可以保证线性一致,关于一致性的分析可以看 这篇文章
线性一致读
线性一致性读需要在所有节点走一遍确认,查询速度会有所降低,要开启线性一致性读,在不同的 client是有所区别的:
v2 版本:通过 sdk访问时,quorum=true 的时候读取是线性一致的,通过etcdctl访问时,该参数默认为true。
v3 版本:通过 sdk访问时,WithSerializable=true 的时候读取是线性一致的,通过etcdctl访问时consistency=“l”表示线性(默认为 l,非线性为 s)
为了保证线性一致性读,早期的 etcd(_etcd v3.0 _)对所有的读写请求都会走一遍 Raft 协议来满足强一致性。然而通常在现实使用中,读请求占了 etcd 所有请求中的绝大部分,如果每次读请求都要走一遍 raft 协议落盘,etcd 性能将非常差。
因此在 etcd v3.1 版本中优化了读请求(PR#6275),使用的方法满足一个简单的策略:每次读操作时记录此时集群的 commit index,当状态机的 apply index 大于或者等于 commit index 时即可返回数据。由于此时状态机已经把读请求所要读的 commit index 对应的日志进行了 apply 操作,符合线性一致读的要求,便可返回此时读到的结果。
部署
介绍下 etcd 的完整安装过程。下载 etcd3.4 的 release 包
生成证书
1.ca-config.json
创建用来生成 CA 文件的 JSON 配置文件,这个文件后面会被各种组件使用,包括了证书过期时间的配置,expiry字段
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"demo": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "87600h"
}
}
}}
2.ca-csr.json
创建用来生成 CA 证书签名请求(CSR)的 JSON 配置文件
{
"CN": "demo",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "demo",
"OU": "cloudnative"
}
]}
3.生成基础 ca 证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
执行后会生成三个文件:
ca.csr:证书签名请求,一般用于提供给证书颁发机构,自签就不需要了
ca.pem:证书,公共证书
ca-key.pem:CA密钥
生成 etcd 证书
增加etcd-csr.json文件,ip 需要填写三台 etcd 机器的 ip
{
"CN": "demo",
"hosts": [
"127.0.0.1",
"ip1","ip2","ip3"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "demo",
"OU": "cloudnative"
}
]}
这里的hosts字段中指定了授权使用该证书的IP和域名列表,因为现在要生成的证书需要被etcd集群各个节点使用,所以这里指定了各个节点的IP
生成证书:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=jpaas etcd-csr.json | cfssljson -bare etcd
创建etcd 的 CA 证书:这里需要4 个文件
etcd-csr.json:etcd的证书配置
ca.pem:基础公钥
ca-key.pem:基础私钥
ca-config.json:配置文件,如过期时间
执行后会生成三个文件:
etcd.csr
etcd.pem
etcd-key.pem
在一台机器上做证书生成,生成后将这三个文件拷贝到其他几台机器。
部署集群
etcd 启动配置示例
./etcd \
--name=etcd-0 \
--client-cert-auth=true \
--cert-file=/etc/etcd/ssl/etcd.pem \
--key-file=/etc/etcd/ssl/etcd-key.pem \
--peer-cert-file=/etc/etcd/ssl/etcd.pem \
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \
--trusted-ca-file=/etc/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \
--initial-advertise-peer-urls https://100.0.0.0:2380 \--listen-peer-urls https://100.0.0.0:2380 \--listen-client-urls https://100.0.0.0:2379,https://127.0.0.1:2379 \--advertise-client-urls https://100.0.0.0:2379 \--initial-cluster-token etcd-cluster \
--initial-cluster etcd-0=https://100.0.0.0:2380,etcd-1=https://100.0.0.1:2380,etcd-2=https://100.0.0.2:2380 \--initial-cluster-state new \
--quota-backend-bytes=8589934592 \
--auto-compaction-retention=10 \
--enable-pprof=true \
--data-dir=/var/lib/etcd
etcdctl 命令
因为我们的 etcd 配置了证书,所有的命令都要带上证书访问,如:
ETCDCTL_API=3 ./etcdctl --endpoints=https://0:2379,https://1:2379,https://2:2379 --cacert /etc/etcd/ssl/ca.pem --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem endpoint status --write-out=table
etcd 版本为 3.4,可以ETCDCTL_API=3,或ETCDCTL_API=2,默认情况下用的就是v3了,可以不用声明ETCDCTL_API
证书太长就不写了,以下命令均为无证书版:
version: 查看版本
member list: 查看节点状态,learner 情况
endpoint status: 节点状态,leader 情况
endpoint health: 健康状态与耗时
alarm list: 查看警告,如存储满时会切换为只读,产生 alarm
alarm disarm:清除所有警告
set app demo: 写入
get app: 获取
update app demo1:更新
rm app: 删除
mkdir demo 创建文件夹
rmdir dir 删除文件夹
backup 备份
compaction:压缩
defrag:整理碎片
watch key 监测 key 变化
get / –prefix –keys-only: 查看所有 key
–write-out= tables,可以用表格形式输出更清晰,注意有些输出并不支持tables
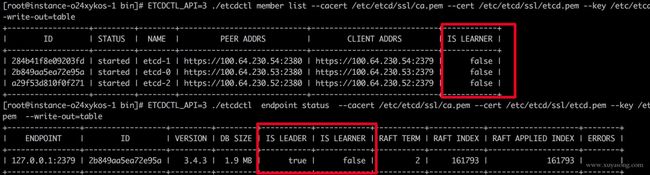
注意,member list并没有展示 leader 信息,展示的是 learner,learner的含义后面会解释
参数配置
版本建议使用 3.4 及以上,3.4存储容量做了提升,降低了读写延迟。
etcd 的配置参数有很多,如果你觉得自己的etcd遇到了瓶颈,先不要急着提 issue 改代码,先看下这些参数的含义,也许调一下配置就能解决。
etcd 的配置遇到按照功能来划分:
代理功能
etcd gateway
etcd grpc-proxy
每个访问 etcd 的应用都要有 etcd 集群的 endpoints。如果在同一台服务器上的多个应用访问同一个 etcd 集群,大家都得配置一样的endpoints。如果这个时候 etcd 集群更换了集群或者 ip,每个应用都需要更新它的终端列表,这种重新配置是繁琐且容易出错的。
这里提一下,etcd 的 client 使用的是 grpc 访问,client会根据传入的 endpoints 做客户端负载均衡。
etcd gateway就是一个典型的转发代理,屏蔽掉后面的endpoints 信息。不过需要注意的是,etcd gateway在 TCP 层,不支持 https 类型的 endpoints。
成员配置
–data-dir: 数据目录
–snapshot-count: 最大快照次数,默认10万
–heartbeat-interval: 心跳周期默认 100ms
–election-timeout: 选举超时1s
–max-snapshots: 最大保留快照数,默认 5 个
–quota-backend-bytes: DB 数据大小,比如 10G,50G。
–auto-compaction-retention: 自动压缩,默认为 0 不开启,k8s中 apiserver会开启这个压缩,5 分钟一次。如果你的 etcd 还被其他人使用,这里也可以设置下时间
–enable-pprof: 开启pprof分析
–metrics: 默认为basic模式,extensive代表暴露histogram类型 metric
–log-level: 日志等级。info, warn, error, panic, or fatal
证书配置
--client-cert-auth=true \
--cert-file=/etc/etcd/ssl/etcd.pem \
--key-file=/etc/etcd/ssl/etcd-key.pem \
--peer-cert-file=/etc/etcd/ssl/etcd.pem \
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \
--trusted-ca-file=/etc/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \
集群配置
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \
--initial-advertise-peer-urls https://100.0.0.0:2380 \--listen-peer-urls https://100.0.0.0:2380 \--listen-client-urls https://100.0.0.0:2379,https://127.0.0.1:2379 \--advertise-client-urls https://100.0.0.0:2379 \--initial-cluster-token etcd-cluster \
--initial-cluster etcd-0=https://100.0.0.0:2380,etcd-1=https://100.0.0.1:2380,etcd-2=https://100.0.0.2:2380 \--initial-cluster-state new \
配置调优
一般情况下,etcd 默认模式不会有什么问题,影响 etcd 的因素一般是网络和存储延时,尤其是跨地域、跨机房的集群。
网络延迟
因为 leader 和 member 之间有频繁的心跳和数据复制,因此网络拥塞影响会很大,当然长时间失败会无响应会导致 etcd 集群不可用。一般是将 etcd 集群规划在一个地域或一个机房内,并且使用tc提高带宽和优先级。
心跳间隔
etcd 的一致性协议依赖两个时间参数。
–heartbeat-interval:心跳间隔,即 leader 通知member 并保证自己 leader 地位的心跳,默认是 100ms,这个应该设置为节点间的 RTT 时间。
–election-timeout:选举超时时间,即 member 多久没有收到 leader 的回应,就开始自己竞选 leader,默认超时时间为 1s
默认值有可能不满足你的需求,如你的网络延迟较高,RTT 大于 100,就应该按真实延迟来,比如这个 issue,官方文档也对心跳的设置给了详细的解释和配置建议:https://github.com/etcd-io/etcd/blob/master/Documentation/tuning.md
如果心跳间隔太短,则 etcd 将发送不必要的消息,从而增加 CPU 和网络资源的使用。另一方面,心跳间隔过长会导致选举超时。较高的选举超时时间需要更长的时间来检测领导者失败。测量往返时间(RTT)的最简单方法是使用PING。
磁盘 IO
除了网络延迟,磁盘 IO 也严重影响 etcd 的稳定性, etcd需要持久化数据,对磁盘速度很敏感,强烈建议对 ETCD 的数据挂 SSD。
另外,要确认机器上没有其他高 IO 操作,否则会影响 etcd 的 fsync,导致 etcd 丢失心跳,leader更换等。一般磁盘有问题时,报错的关键字类似于:
took too long (1.483848046s) to execute
etcdserver: failed to send out heartbeat on time
磁盘 IO 可以通过监控手段提前发现,并预防这类问题的出现
快照
etcd的存储分为内存存储和持久化(硬盘)存储两部分,内存中的存储除了顺序化的记录下所有用户对节点数据变更的记录外,还会对用户数据进行索引、建堆等方便查询的操作。而持久化则使用预写式日志(WAL:Write Ahead Log)进行记录存储。
在WAL的体系中,所有的数据在提交之前都会进行日志记录。在etcd的持久化存储目录中,有两个子目录。一个是WAL,存储着所有事务的变化记录;另一个则是snapshot,用于存储某一个时刻etcd所有目录的数据。通过WAL和snapshot相结合的方式,etcd可以有效的进行数据存储和节点故障恢复等操作。
既然有了WAL实时存储了所有的变更,为什么还需要snapshot呢?随着使用量的增加,WAL存储的数据会暴增,为了防止磁盘很快就爆满,etcd默认每10000条记录做一次snapshot,经过snapshot以后的WAL文件就可以删除。而通过API可以查询的历史etcd操作默认为1000条。
客户端优化
etcd 的客户端应该避免一些频繁操作或者大对象操作,如:
put 时避免大 value,精简再精简(例如 k8s 中 crd 使用)
避免创建频繁变化的 kv(例如 k8s 中 node 信息汇报),如 node-lease
避免创建大量 lease,尽量选择复用(例如 k8s 中 event 数据管理)
合理利用 apiserver 中的缓存,避免大量请求打到 etcd上,如集群异常恢复后大量 pod同步
其他
你可能还看到过lease revoke 、boltdb、内存优化等方式,这些已经合入了最新的 etcd3.4版本,因此选择最新的 release 版本也是提高稳定性的一种方式。
压缩机制
Etcd作为 KV 存储,会为每个 key 都保留历史版本,比如用于发布回滚、配置历史等。
对 demo 写入值为 101,然后更为为 102,103。-w json 可以输出这次写入的 revision
etcdctl put demo 101 -w json
etcdctl put demo 102 -w json
etcdctl put demo 103 -w json
返回类似:{"header":{"cluster_id":4871617780647557296,"member_id":3135801277950388570,"revision":434841,"raft_term":2}}
取值:
etcdctl get demo 默认 --rev=0即最新值=103如果要拿到历史值,需要制定 rev 版本
etcdctl get demo --rev=434841,得到 102
观察 key的变化:
etcdctl watch foo --rev=0
历史版本越多,存储空间越大,性能越差,直到etcd到达空间配额限制的时候,etcd的写入将会被禁止变为只读,影响线上服务,因此这些历史版本需要进行压缩。
数据压缩并不是清理现有数据,只是对给定版本之前的历史版本进行清理,清理后数据的历史版本将不能访问,但不会影响现有最新数据的访问。
手动压缩
etcdctl compact 5。 在 5 之前的所有版本都会被压缩,不可访问如果 etcdctl get --rev=4 demo,会报错Error: rpc error: code = 11 desc = etcdserver: mvcc: required revision has been compacted
手动操作毕竟繁琐,Etcd提供了启动参数 “–auto-compaction-retention” 支持自动压缩 key 的历史版本,以小时为单位
etcd --auto-compaction-retention=1 代表 1 小时压缩一次
v3.3之上的版本有这样一个规则:
如果配置的值小于1小时,那么就严格按照这个时间来执行压缩;如果配置的值大于1小时,会每小时执行压缩,但是采样还是按照保留的版本窗口依然按照用户指定的时间周期来定。
k8s api-server支持定期执行压缩操作,其参数里面有这样的配置:
– etcd-compaction-interval 即默认 5 分钟一次
你可以在 etcd 中看到这样的压缩日志,5 分钟一次:
Apr 25 11:05:20 etcd[2195]: store.index: compact 433912Apr 25 11:05:20 etcd[2195]: finished scheduled compaction at 433912 (took 1.068846ms)Apr 25 11:10:20 etcd[2195]: store.index: compact 434487Apr 25 11:10:20 etcd[2195]: finished scheduled compaction at 434487 (took 1.019571ms)Apr 25 11:15:20 etcd[2195]: store.index: compact 435063Apr 25 11:15:20 etcd[2195]: finished scheduled compaction at 435063 (took 1.659541ms)Apr 25 11:20:20 etcd[2195]: store.index: compact 435637Apr 25 11:20:20 etcd[2195]: finished scheduled compaction at 435637 (took 1.676035ms)Apr 25 11:25:20 etcd[2195]: store.index: compact 436211Apr 25 11:25:20 etcd[2195]: finished scheduled compaction at 436211 (took 1.17725ms)
碎片整理
进行压缩操作之后,旧的revision被清理,会产生内部的碎片,内部碎片是指空闲状态的,能被etcd使用但是仍然消耗存储空间的磁盘空间,去碎片化实际上是将存储空间还给文件系统。
# defrag命令默认只对本机有效
etcdctl defrag
# 如果带参数--endpoints,可以指定集群中的其他节点也做整理
etcdctl defrag --endpoints
如果etcd没有运行,可以直接整理目录中db的碎片
etcdctl defrag --data-dir
碎片整理会阻塞对etcd的读写操作,因此偶尔一次大量数据的defrag最好逐台进行,以免影响集群稳定性。
etcdctl执行后的返回 Finished defragmenting etcd member[https://127.0.0.1:2379]
存储空间
Etcd 的存储配额可保证集群操作的可靠性。如果没有存储配额,那么 Etcd 的性能就会因为存储空间的持续增长而严重下降,甚至有耗完集群磁盘空间导致不可预测集群行为的风险。一旦其中一个节点的后台数据库的存储空间超出了存储配额,Etcd 就会触发集群范围的告警,并将集群置于接受读 key 和删除 key 的维护模式。只有在释放足够的空间和消除后端数据库的碎片之后,清除存储配额告警,集群才能恢复正常操作。
启动 etcd 时。–quota-backend-bytes 默认为 2G,2G 一般情况下是不够用的,
你可以通过 etcdctl endpoint status 命令来查看当前的存储使用量

在 3.4 版本中,etcd 的存储容量得到了提高,你可以设置 100G 的存储空间,当然并不是越大越好,key 存储过多性能也会变差,根据集群规模适当调整。
另外,–max-request-bytes 限制了请求的大小,默认值是1572864,即1.5M。在某些场景可能会出现请求过大导致无法写入的情况,可以调大到10485760即10M。
如果遇到空间不足,可以这样操作:
# 获取当前版本号
$ rev=$(ETCDCTL_API=3 etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9]*')# 压缩所有旧版本
$ ETCDCTL_API=3 etcdctl compact $rev# 去碎片化
$ ETCDCTL_API=3 etcdctl defrag
# 取消警报
$ ETCDCTL_API=3 etcdctl alarm disarm
# 测试通过
$ ETCDCTL_API=3 etcdctl put key0 1234
快照备份
etcd可以定期做备份、以保证数据更好的持久化。通过加载备份数据,etcd可以将集群恢复到具有已知良好状态的时间点。
使用命令etcdctl:
etcdctl snapshot save backup.db
etcdctl --write-out=table snapshot status backup.db
+----------+----------+------------+------------+| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |+----------+----------+------------+------------+| fe01cf57 | 10 | 7 | 2.1 MB |+----------+----------+------------+------------+
learner 角色
learner 是 etcd 3.4 版本中增加的新角色,类似于 zookeeper 的 observer, 不参与 raft 投票选举。通过这个新角色的引入,降低了加入新节点时给老集群的额外压力,增强了集群的稳定性。除此之外还可以使用它作为集群的热备或服务一些读请求。
举例,如果 etcd集群需要加入一个新节点,新加入的 etcd 成员因为没有任何数据,因此需要从 leader 那里同步数据,直到赶上领导者的日志为止。这样就会导致 leader 的网络过载,导致 leader 和 member 之间的心跳可能阻塞。然后就开始了新的leader选举,也就是说,具有新成员的集群更容易受到领导人选举的影响。领导者的选举以及随后向新成员的更新都容易导致一段时间的群集不可用,这种是不符合预期,风险也是很大的。
因此为了解决这个问题,raft 4.2.1 论文中介绍了一种新的节点角色:Learner。加入集群的节点不参与投票选举,只接收 leader 的 replication message,直到与 leader 保持同步为止。
learner 在网络分区等场景下的处理,可以详细参考:https://etcd.io/docs/v3.3.12/learning/learner/
具体操作:
# 增加一个节点作为learner
member add --learner
# 当learner的日志赶上了leader的进度时,将learner提升为有投票权的成员,然后该成员将计入法定人数
member promote
etcd server 会验证 promote 请求以确保真实
在提升之前,learner仅充当备用节点,leader无法转移给learner。learner拒绝客户端读写(客户端平衡器不应将请求路由到learner)
另外,etcd限制了集群可以拥有的learner总数,并避免了日志复制导致领导者过载。learner永远不会自我提升。
etcd client v3
Etcd client v3是基于grpc实现的,而grpc又是基于http2.0实现的,借用了很多 http2的优势如二进制通讯、多路复用等,因此整体上借用grpc的框架做地址管理、连接管理、负载均衡等,而底层对每个Etcd的server只需维持一个http2.0连接。
Etcd client v3实现了grpc中的Resolver接口,用于Etcd server地址管理。当client初始化或者server集群地址发生变更(可以配置定时刷新地址)时,Resolver解析出新的连接地址,通知grpc ClientConn来响应变更。
client v3的原理解析可以看这篇文章:https://www.jianshu.com/p/281b80ae619b
我们是用etcd client做应用的选主操作,可以看下这篇
这里提一下,最早的时候以为 kubernetes 中的 scheduler、controller-manager是基于 etcd 做选主的,client拿来直接用很方便。后来发现不是,kubernetes 是用抢占 endpoint 资源的方式实现选主逻辑,不依赖外部 etcd,这么想来也合理,严格来讲,etcd 不是kubernetes的东西,不应该有太多依赖。
k8s 中 scheduler 的选主逻辑可以看这篇文章
问题排查
列几个常遇到的 etcd 问题,后面监控部分会提到如何监测、预防这类问题
一个节点宕机
一个节点宕机,并不会影响整个集群的正常工作,慢慢修复。
移出该节点:etcdctl member remove xx
修复机器问题,删除旧的数据目录,重新启动 etcd 服务
因为 etcd 的证书需要签入所有节点 ip,因此这里的节点不能更改 ip,否则要全部重签证书,重启服务
重启启动 etcd 时,需要将配置中的 cluster_state改为:existing,因为是加入已有集群,不能用 new
加入 memeber:etcdctl member add xxx –peer-urls=https://x.x.x.x:2380
验证:etcdctl endpoint status
迁移数据
如果你的集群需要更换所有的机器,包括更换 IP,那就得通过快照恢复的方式了
使用 etcdctl snapshot save 来保存现有数据,新集群更换后,使用 restore 命令恢复数据,在执行快照时会产生一个 hash 值,来标记快照内容后面恢复时用于校验,如果你是直接复制的数据文件,可以–skip-hash-check 跳过这个检查。
迁移集群会更换证书和端点,因此一定会影响上层服务,在迁移之前一定要做好新旧切换,如 apiserver 分批升级(会有部分数据不一致)、避免服务宕机时间过长等
failed to send out heartbeat on time
这个前面已经提过,大概率是因为磁盘性能不足,导致心跳失败,更换 SSD 或者排查机器上高 IO 的进程
详细可以查看这个:https://github.com/etcd-io/etcd/blob/master/Documentation/faq.md#what-does-the-etcd-warning-failed-to-send-out-heartbeat-on-time-mean
request ... took too long to execute 这类报错也是同理
mvcc: database space exceeded
存储空间不足,参考上面提到的清理和恢复步骤,或者提高存储空间
endpoints问题
尽量不要使用lb 作为 etcd endpoints 配置,etcd client 是 grpc 访问,请使用默认的 全量list ,客户端做负载均衡的方式。详细内容可以参考 grpc 负载均衡场景解析
监控
etcd 默认以/metrics的 path 暴露了监控数据,数据为 prometheus 标准格式。
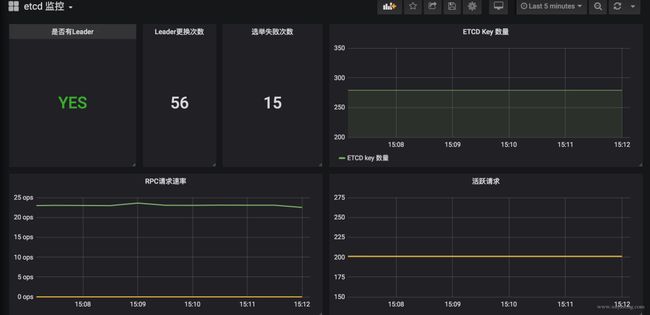
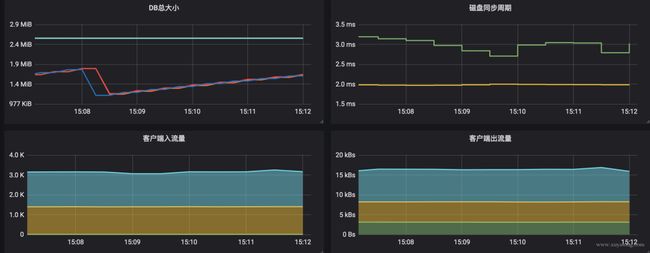
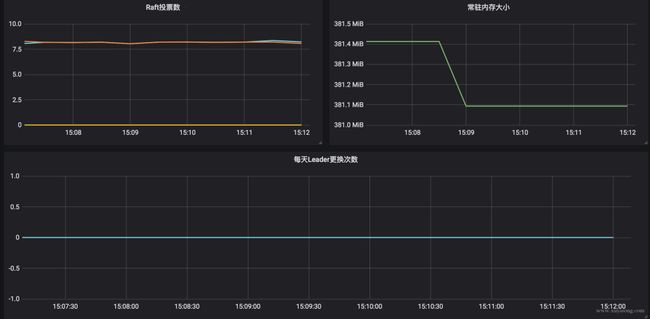
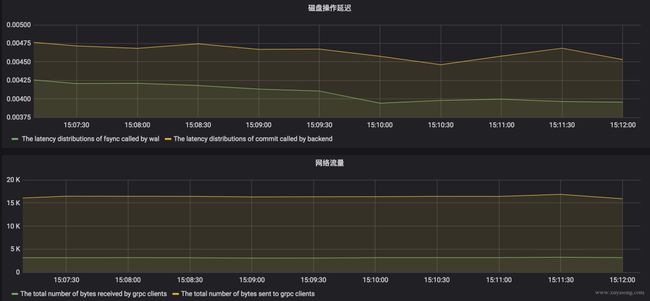
通过 metric 数据可以配置出如下面板,一般我们关心的数据,或者说需要配置报警的内容:
是否有 leader:集群就不可用了
leader 更换次数:一定时间内频率过高一般是有问题,且leader 更换会影响到上层服务
rpc 请求速率:即 qps,可以评估当前负载
db 总大小:用于评估数据量、压缩策略等
磁盘读写延迟:这个很关键,延迟过高会导致集群出现问题
后记
etcd 可以很简单,毕竟只是 KV 存储,也可以很复杂,代表了云原生时代分布式存储的基石,本文中的内容只是工作中的问题描述,浅尝辄止,不足之处,欢迎指正。
参考
https://ms2008.github.io/2019/12/04/etcd-rumor/
ReadIndex:https://zhuanlan.zhihu.com/p/31050303
LeaseRead:https://zhuanlan.zhihu.com/p/31118381
线性一致读:https://zhengyinyong.com/post/etcd-linearizable-read-implementation/
https://juejin.im/post/5d843b995188257e8e46e25d
https://skyao.io/learning-etcd3/documentation/op-guide/gateway.html
https://github.com/etcd-io/etcd/issues/7522
https://github.com/etcd-io/etcd/blob/master/Documentation/learning/design-learner.md

想知道更多?扫描下面的二维码关注我

后台回复”加群“获取公众号专属群聊入口
当当618图书优惠活动,每满100-50,我这里还有一批“实付满200再减30”的优惠码TEGNC6 ,囤书薅羊毛再走一波~~(使用时间:5月18~6月1日,使用渠道:当当小程序或当当APP)
【原创系列 | 精彩推荐】
Paxos、Raft不是一致性算法嘛?
越说越迷糊的CAP
分布式事务科普——初识篇
分布式事务科普——终结篇
面试官居然问我Raft为什么会叫做Raft!
面试官给我挖坑:URI中的//有什么用
面试官给我挖坑:a[i][j]和a[j][i]有什么区别?
面试官给我挖坑:单机并发TCP连接数到底有多少?
网关Zuul科普
网关Spring Cloud Gateway科普
Nginx架构原理科普
OpenResty概要及原理科普
微服务网关 Kong 科普
云原生网关Traefik科普
点个在看少个 bug ????