工具:google浏览器 + fiddler抓包工具
说明:这里不贴代码,【只讲思路!!!】
原始url = https://v.youku.com/v_show/id_XMzIwNjgyMDgwOA==.html? 【随便找的一部电影链接】称它为原始url
开始分析:
打开 fiddler ,然后打开google,输入url,按F12.得到下图 : 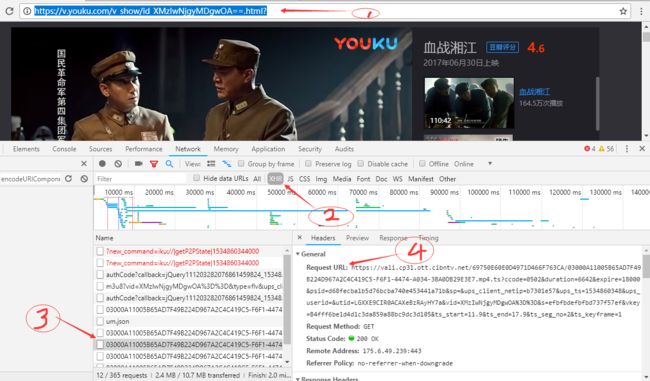
分析上图内容: 首先通过fiddler抓包得知真实播放地址是一段一段的,就如上图标号3,然后将其中一小段播放地址复制到浏览器打开,得到403error,由此可知,该链接需要重构一些东西,然后才能通过代码发送请求,否则是会被拒绝的。因此,来到上图标号4,分析请求url。首先先分析不同视频段之间的url区别,对比发现仅仅是【ts_seg_no】参数不同,而且该参数是从0开始逐渐+1,但是末尾是多少尚未可知。然后分析当不同时间打开原始url时,视频真实地址的请求url有哪些区别。老方法,将原始url在新建标签页再打开一次,对比两次打开的请求url。请求url参数的对比过程省略,参数对比的结果如下图: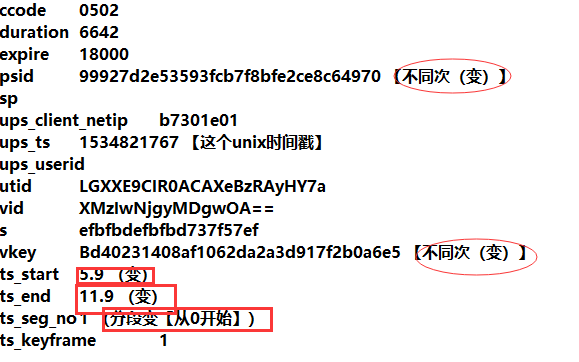
可以看到每次打开,psid 和 vkey 这两个参数都是在变的,并且代表什么尚未可知。同次打开时的不同视频段的请求url在 ts_start 、 ts_end、ts_seg_no 参数上也有变化,虽然变化规律已知,但是并不能确定这三个参数的在什么时间结尾,因此也是尚未可知。分析到这里,可以确定的是在分段视频链接之前肯定还有链接或者js文件加载了这些未知的参数或者这些未知的请求url链接。于是在 network 中尝试地搜索了psid、vkey两个值,链接的一部分长这样【pl-ali.youku.com/playlist/m3u8?】,然后点开查看响应,如下图: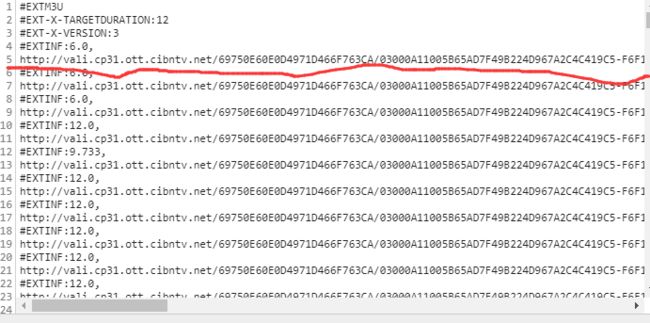
正好,响应的内容刚好是视频分段的请求链接。所以现在就不用去重构视频分段的请求链接了,把重点放在上图中的url链接上【暂且叫它播放url】,只要能弄到播放url,那么这次任务就算完成。
然后开始分析播放url,它的模样如下图:
看上去有点复杂,所以就采用之前对比分析url的方法,得到播放url参数区别,区别如下图:
分析这个链接,得到链接中需要重构的参数只有 psid、ups_key 。所以要开始分析这两个参数的来源。
因此在google network 中ctrl+f 搜索 psid 、ups_key,发现两个参数出现在链接叫【https://acs.youku.com/h5/mtop.youku.play.ups.appinfo.get】中,这个链接【叫它js链接】如下图;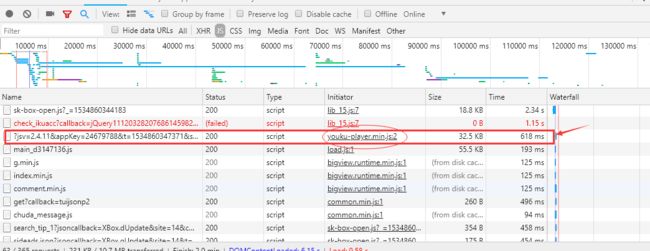
这个js链接是一个js文件。点开后,查看响应,发现响应是一个json格式的js函数,如下图: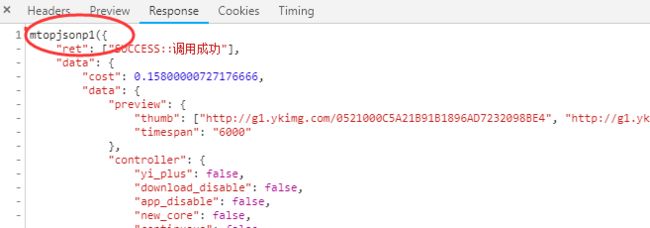
接着在响应中搜索psid、ups_key的值,居然找到了之前的播放链接,给个图: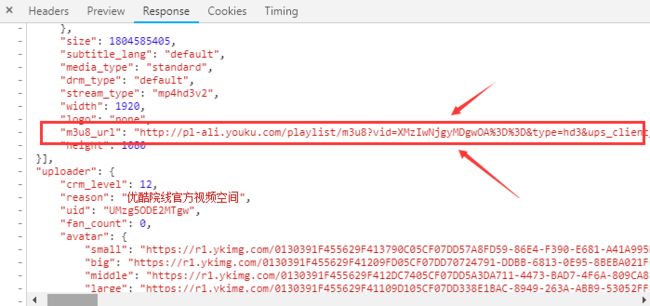
ok! 现在一切都很明朗了,只要能获取到这个js链接的响应信息,将m3u8_url 提取出来再请求,并提取响应【这个响应里面就是真实的视频播放地址】。因此现在要想办法怎么才能获取这个js链接,
问题的出现
嗯。。。?(猜想中...)从响应中可以看到 json 格式是在mtopjsonp1() 这个里面,那么这个mtopjsonp1()是什么呢?他是一个js函数吗?如果是一个js函数的话,那么可以尝试搜索一下看看【尝试过,并没有看到完全一样的函数】,难道尝试着去请求这个js链接吗?【这个链接也看了看,特别~特别的长,看起来好复杂,这条路先不考虑】,如果前面两个都不考虑的话,那么又要开始考虑重构那个 播放url 了,毕竟 播放url 只要找出psid、ups_key两个参数就ok。于是开始思考:这两个如果有其他路径存在的话,那它应该是在某个js函数里面,所以开始在 network 中search 两个参数 psid 、ups_key。嗯,发现了 psid 参数的痕迹。如下图: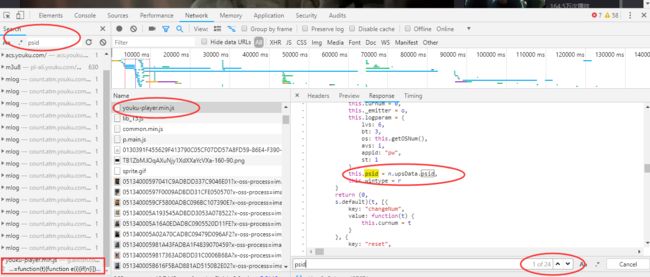
确实在另一个js文件中发现了 psid ,但是又不太像,而且就算是的话,js不怎么熟的我也是找不出 psid 是怎么生成的,所以呢,这个变量先放着,接着搜一下 ups_key,很遗憾,没有在js文件中找到这个变量,因此需要回到猜想【如何想办法来请求那个很长很复杂的 js链接 】,为什么说它复杂呢? 看下图就知道了: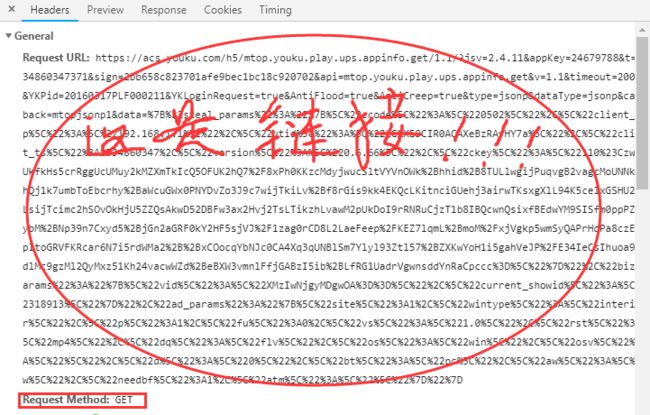
而且还是 GET 请求,发送 Data 的链接 ,下图是链接的参数(先绝望一下):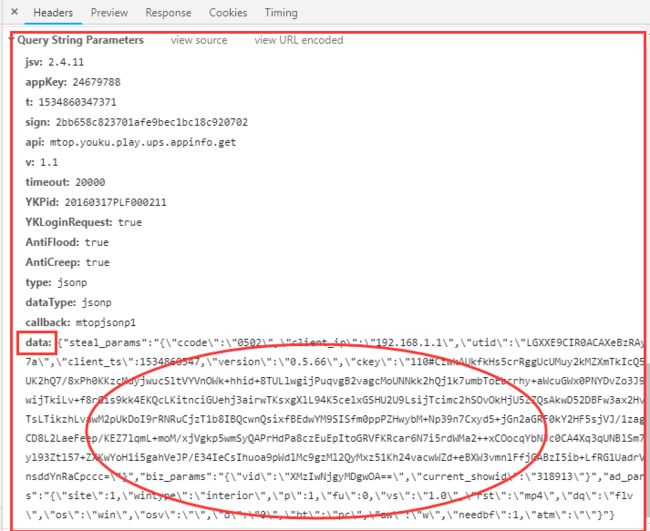
说心里话,看到这样的链接,实在不想弄了。
但是还是得花时间把它给摸透了,不然我得爬虫技术就是到此为止咯。(弄还是要弄的,不过想到爬虫方面的问题又无人可问,不由十分悲伤,技术瓶颈只能靠自己用未知的时间去堆出来)再接着弄吧。
写在结尾
我现在在爬虫破解js方向上出现了技术瓶颈,上一次那个破解检索网站也是万事具备就差一个由js加密的参数,因为没法解决js加密,最后又失败了。想来想去,这个技术瓶颈只能是现在开始学习js,自己也学着来做下js加密数据。如此翻来覆去,想必js破解指日可待。等以后js学成后,我要自己加密自己破解。
另外文中所写完全是我个人的思路。可能是正确的,可能是错误的,可能某部分偏了等等,如果你不幸看到我的随笔,还不幸看到这个地方的话,十分真诚地希望你可以指正错误。
另外,如果后续破解成功,这篇文章还会更新的。