机器学习之Sklearn库
sklearn
sklearn库是在Numpy、Scipy和matplotlib的基础上开发而成的,因此在介绍sklearn的安装前,需要先安装这些依赖库。
Numpy
Numpy是一个开源的python科学计算库。
Scipy
Scipy库是sklearn库的基础,它是基于Numpy的一个集成了多种数学算法和函数的python模块。
matplotlib
matplotlib是基于Numpy的一套python工具包,它提供了大量的数据绘图工具。
数据集总览
| 数据集名称 | 调用方式 | 适用算法 |
|---|---|---|
| 波士顿房价数据集 | load_boston() | 回归 |
| 鸢尾花数据集 | load_iris() | 分类 |
| 糖尿病数据集 | load_diabetes() | 回归 |
| 手写数据集 | load_digits() | 分类 |
| Olivetti脸部图像数据集 | fetch_olivetti_faces() | 降维 |
| 新闻分类数据集 | fetch_20newsgroups() | 分类 |
| 带标签的人脸数据集 | fetch_lfw_people() | 分类,降维 |
| 路透社新闻语料数据集 | fetch_revl() | 分类 |
以上小数据集可以直接调用,大数据集要在调用时程序自动下载(一次即可)
波士顿房价数据集
该数据集包含美国人口普查局收集的美国马萨诸塞州波士顿住房价格的有关信息, 506个案例。
数据集都有以下14个属性:
CRIM–城镇人均犯罪率
ZN - 占地面积超过25,000平方英尺的住宅用地比例。
INDUS - 每个城镇非零售业务的比例。
CHAS - Charles River虚拟变量(如果是河道,则为1;否则为0)
NOX - 一氧化氮浓度(每千万份)
RM - 每间住宅的平均房间数
AGE - 1940年以前建造的自住单位比例
DIS加权距离波士顿的五个就业中心
RAD - 径向高速公路的可达性指数
TAX - 每10,000美元的全额物业税率
PTRATIO - 城镇的学生与教师比例
B - 1000(Bk - 0.63)^ 2其中Bk是城镇黑人的比例
LSTAT - 人口状况下降%
MEDV - 自有住房的中位数报价, 单位1000美元
使用sklearn.datasets.load_boston即可加载相关数据集
重要参数:
return_X_y:表示是否返回target(即价格),默认为False,只返回data(即属性)
示例1:
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.data.shape)
#返回值(506,13)示例2:
from sklearn.datasets import load_boston
data,target = load_boston(return_X_y=True)
print(data.shape)
#返回值(506,13)
print(target.shape)
#返回值(506)鸢尾花数据集
鸢尾花数据集采集的是鸢尾花的测量数据以及其所属的类别。
测量数据包括:萼片长度、萼片宽度、花瓣长度、花瓣宽度。
类别分为三类:Iris Setosa,Iris Versicolour,Iris Virginica。该数据集可用于多分类问题。
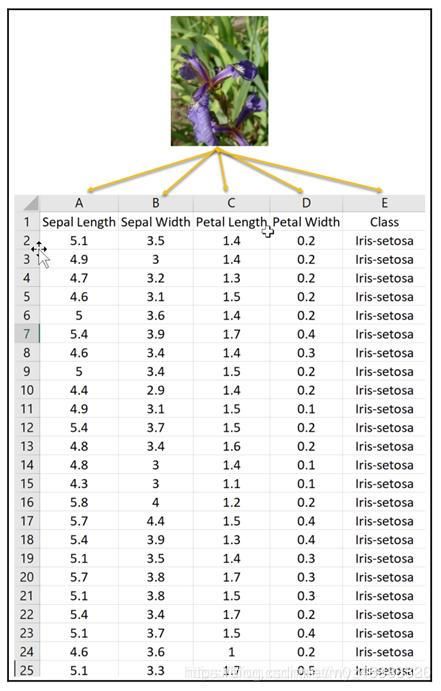
使用sklearn.datasets.load_iris即可加载相关数据集
参数:
return_X_y:若为True,则以(data,target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)。
加载示例:
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data.shape)
#返回值(150,4)
print(iris.target.shape)
#返回值(150,)
list(iris.target_names)
#返回值['setosa','versicolor','virginica']手写数字数据集
手写数字数据集包括1797个书写数字数据,每个数字由8*8大小的矩阵构成,矩阵中值的范围是0~16,代表颜色的深度。
 使用sklearn.datasets.load_digits即可加载相关数据集
使用sklearn.datasets.load_digits即可加载相关数据集
return_X_y:若为True,则以(data,target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)。
n_class:表示返回数据的类别数,如:n_class=5,则返回0到4的数据样本。
skearn库的主要功能
sklearn库的功能共分为6大部分,分别用于完成分类任务、回归任务、聚类任务、降维任务、模型选择以及数据的预处理。
分类任务
| 分类模型 | 加载模块 |
|---|---|
| 最近邻算法 | neighbor.NearestNeighbors |
| 支持向量机 | svm.SVC |
| 朴素贝叶斯 | naive_bayes.GaussianNB |
| 决策树 | tree.DecisionTreeClassifier |
| 集成方法 | ensemble.BaggingClassifier |
| 神经网络 | neural_network.MLPClassifier |
回归任务
| 回归模型 | 加载模块 |
|---|---|
| 岭回归 | linear_model.Ridge |
| Lasso回归 | linear_model.Lasso |
| 弹性网络 | linear_model.ElasticNet |
| 最小角回归 | linear_model.Lars |
| 贝叶斯回归 | linear_model.BayesianRidge |
| 逻辑回归 | linear_model.LogisticRegression |
| 多项式回归 | preprocessing.PolynomialFeatures |
本次主要介绍分类和回归任务。
