15. spark Sql 对于嵌套的结构的提取。
15.
spark Sql 对于嵌套的结构的提取。
使用explode函数来操作,如果有多层嵌套,使用多次explode函数即可。
http://bigdatums.net/2016/02/12/how-to-extract-nested-json-data-in-spark/
单层嵌套
{
"user": "gT35Hhhre9m",
"dates": ["2016-01-29", "2016-01-28"],
"status": "OK",
"reason": "some reason",
"content": [{
"foo": 123,
"bar": "val1"
}, {
"foo": 456,
"bar": "val2"
}, {
"foo": 789,
"bar": "val3"
}, {
"foo": 124,
"bar": "val4"
}, {
"foo": 126,
"bar": "val5"
}]
}//explode content field
scala> val dfContent = df.select(explode(df("content")))
dfContent: org.apache.spark.sql.DataFrame = [col: struct]
//output
scala> dfContent.show
+----------+
| col|
+----------+
|[val1,123]|
|[val2,456]|
|[val3,789]|
|[val4,124]|
|[val5,126]|
+----------+
//rename "col" to "content"
scala> val dfContent = df.select(explode(df("content"))).toDF("content")
dfContent: org.apache.spark.sql.DataFrame = [content: struct]
//output
scala> dfContent.show
+----------+
| content|
+----------+
|[val1,123]|
|[val2,456]|
|[val3,789]|
|[val4,124]|
|[val5,126]|
+----------+
//extracting fields in struct
scala> val dfFooBar = dfContent.select("content.foo", "content.bar")
dfFooBar: org.apache.spark.sql.DataFrame = [foo: bigint, bar: string]
//output
scala> dfFooBar.show
+---+----+
|foo| bar|
+---+----+
|123|val1|
|456|val2|
|789|val3|
|124|val4|
|126|val5|
+---+----+ 多层嵌套
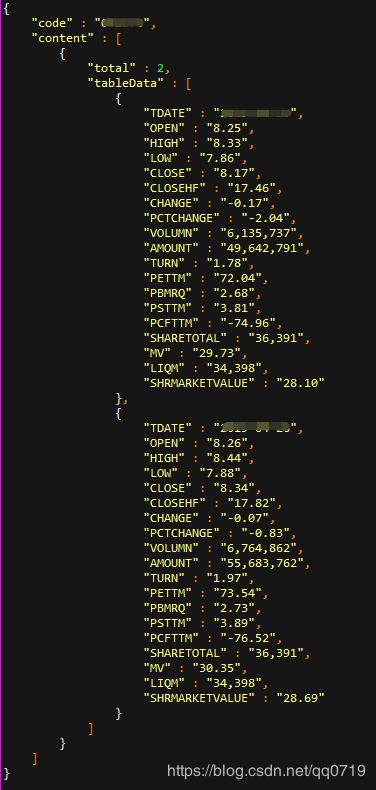
提取tableData的数据
伪代码
val DailyPriceDimDF = DailyPriceDimDF_
.select($"code", explode($"content") as "data")
.select($"code", explode($"data.tableData") as "data")


此贴来自汇总贴的子问题,只是为了方便查询。
总贴请看置顶帖:
pyspark及Spark报错问题汇总及某些函数用法。
https://blog.csdn.net/qq0719/article/details/86003435