Ceph BlueStore
Ceph BlueStore(此文章转发自http://blog.wjin.org/)
Source: http://blog.wjin.org/posts/ceph-bluestore.html
Declaration: this work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Introduction
在介绍了BlockDevice,BlueFS,FreelistManager和Allocator后,接下来重点分析BlueStore的实现。BlueStore继承于ObjectStore,它需要实现mkfs/mount/umount等初始化和退出时的操作,同时它也提供对象操作的基本接口,比如read/write,以及对象属性attr和omap相关的操作。虽然代码量巨大,但是除了写操作以外,其他只是代码繁琐,但是不难理解,所以将更多精力花在写操作的流程上,以及和写性能相关的各种监控指标上。对于写操作的请求,怎么从内存的object extent映射到磁盘的地址空间,可以参考网上的这篇文章。这里以simple write表示新写/对齐写(cow)等不需要wal的场景,以deferred write表示需要写wal的场景(rmw)。
首先从宏观上了解一下BlueStore的整体架构(借用Ceph作者的图):
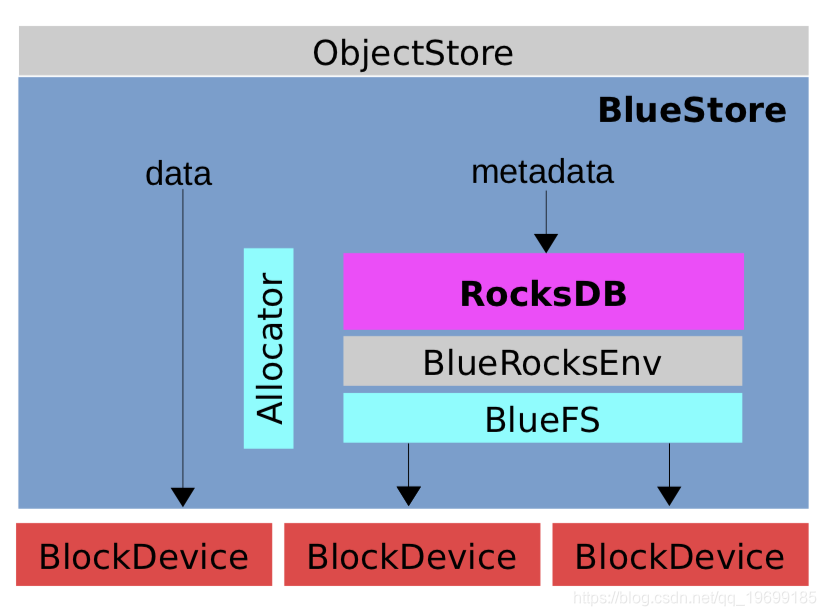因为主要还是用KernelDevice,所以仍然以KernelDevice作为介绍,BlueStore涉及到的线程如下:
- OSD::osd_op_tp: 通过libaio的方式,提交io请求给KernelDevice
- KernelDevice::aio_thread: 执行libaio完成后的回调
- BlueStore::kv_sync_thread: 同步kv数据,包括对象的meta信息和磁盘空间使用信息,以及wal日志的清理
- BlueStore::kv_finalize_thread: 完成时回调的处理以及其他清理工作。wal情况生成dbh以及提交io请求
- BlueStore::deferred_finisher: 通过libaio的方式,提交deferred io的请求
- BlueStore::finishers: finisher线程的sharding,用来回调通知用户请求完成
AioContext
写设备都是通过libaio,首先需要了解回调函数的执行流程。AioContext派生了两种context,TransContext和DeferredBatch,前者对应simple write,简称为txc,后者对应deferred write,简称为dbh。创建块设备的时候,会设置好回调函数,由块设备的aio thread线程执行回调:
struct AioContext {
virtual void aio_finish(BlueStore *store) = 0;
virtual ~AioContext() {}
};
struct TransContext : public AioContext {
…
void aio_finish(BlueStore *store) override {
store->txc_aio_finish(this); // txc的回调
}
}
struct DeferredBatch : public AioContext {
…
void aio_finish(BlueStore *store) override {
store->_deferred_aio_finish(osr); // dbh的回调
}
}
回调函数在创建设备的时候,会提前设置好:
int BlueStore::_open_bdev(bool create)
{
assert(bdev == NULL);
string p = path + "/block";
bdev = BlockDevice::create(cct, p, aio_cb, static_cast<void*>(this)); // 传入回调函数
......
}
static void aio_cb(void priv, void priv2)
{
BlueStore store = static_cast<BlueStore>(priv);
BlueStore::AioContext c = static_cast<BlueStore::AioContext>(priv2);
c->aio_finish(store); // 执行回调函数
}
Write Type
对于用户或osd层面的一次IO写请求,到BlueStore这一层,可能是simple write,也可能是deferred write,还有可能既有simple write的场景,也有deferred write的场景。
Simple Write
对于simple write场景,先把数据写入新的block,然后更新k/v元信息,txc状态转换图如下:
写新block:
STATE_PREPARE -> STATE_AIO_WAIT -> STATE_IO_DONE -> STATE_KV_QUEUED
写k/v元信息:
STATE_KV_QUEUED -> STATE_KV_SUBMITTED -> STATE_KV_DONE -> STATE_FINISHING -> STATE_DONE
步骤:
-
线程池osd_op_tp设置状态STATE_PREPARE和STATE_AIO_WAIT,提交IO等待回调
-
aio_thread回调处理,设置状态STATE_IO_DONE和STATE_KV_QUEUED
-
kv_sync_thread commit k/v事务,设置状态STATE_KV_SUBMITTED
-
kv_finalize_thread设置状态STATE_KV_DONE,STATE_FINISHING和STATE_DONE。
Deferred Write
对于deferred write场景,wal直接封装在k/v事务中,先写日志,即commit k/v操作,所以不会经过STATE_AIO_WAIT。日志写完成后,再封装一个dbh事务执行data的写操作。
写k/v日志:
STATE_PREPARE -> STATE_IO_DONE -> STATE_KV_QUEUED -> STATE_KV_SUBMITTED -> STATE_KV_DONE -> STATE_DEFERRED_QUEUE
写数据:
STATE_DEFERRED_QUEUE -> STATE_DEFERRED_CLEANUP -> STATE_FINISHING -> STATE_DONE
步骤:
-
线程池osd_op_tp设置状态STATE_PREPARE,STATE_IO_DONE和STATE_KV_QUEUED,将wal日志请求在kv队列中排队,等待commit
-
kv_sync_thread commit k/v日志,设置状态STATE_KV_SUBMITTED
-
kv_finalize_thread设置状态STATE_KV_DONE和STATE_DEFERRED_QUEUE,生成写data的dbh并提交IO请求,等待回调
-
aio_thread回调处理,设置状态STATE_DEFERRED_CLEANUP
-
kv_sync_thread清理k/v中的日志
-
kv_finalize_thread设置状态STATE_FINISHING和STATE_DONE
Simple Write + Deferred Write
这种写操作最复杂,状态由前面两种的组合起来,步骤如下:
-
线程池osd_op_tp设置状态STATE_PREPARE和STATE_AIO_WAIT,提交IO等待回调(simple write的IO)
-
aio_thread回调处理,设置状态STATE_IO_DONE和STATE_KV_QUEUED
-
kv_sync_thread commit k/v日志和部分元信息,设置状态STATE_KV_SUBMITTED
-
kv_finalize_thread设置状态STATE_KV_DONE和STATE_DEFERRED_QUEUE,生成写data的dbh并提交IO请求,等待回调
-
aio_thread回调处理,设置状态STATE_DEFERRED_CLEANUP
-
kv_sync_thread清理k/v中的日志
-
kv_finalize_thread设置状态STATE_FINISHING和STATE_DONE
无论何种情况,当执行到STATE_KV_DONE后,就可以安全通知用户写操作完成,下面具体分析每个线程的工作。
Write Process
OSD::osd_op_tp
和FileStore类似,pg内部的修改操作,由线程池osd_op_tp封装成事务,通过函数queue_transactions提交请求:
int BlueStore::queue_transactions(Sequencer *posr, vector<Transaction>& tls, TrackedOpRef op,
ThreadPool::TPHandle *handle)
{
// 准备pg的OpSequencer,保证pg内部操作串行执行
OpSequencer *osr;
if (posr->p) {
osr = static_cast<OpSequencer *>(posr->p.get());
} else {
osr = new OpSequencer(cct, this);
osr->parent = posr;
posr->p = osr;
}
// 创建txc并将其在OpSequencer内部排队
TransContext *txc = _txc_create(osr); // txc初始状态为STATE_PREPARE
// 准备回调函数
txc->onreadable = onreadable;
txc->onreadable_sync = onreadable_sync;
txc->oncommit = ondisk;
// 将osd层面的事务,转换为BlueStore层面的事务操作
for (vector<Transaction>::iterator p = tls.begin(); p != tls.end(); ++p) {
(p).set_osr(osr);
txc->bytes += (p).get_num_bytes();
_txc_add_transaction(txc, &(*p)); // 非常复杂
}
// 将deferred类型的日志加入k/v的事务中
if (txc->deferred_txn) {
txc->deferred_txn->seq = ++deferred_seq;
bufferlist bl;
::encode(*txc->deferred_txn, bl);
string key;
get_deferred_key(txc->deferred_txn->seq, &key);
txc->t->set(PREFIX_DEFERRED, key, bl);
}
// 限流操作
…
// 执行状态机,会将io请求提交给块设备执行
_txc_state_proc(txc);
}
// _txc_state_proc函数就是一个状态机,实现比较简单,后续不再列举
void BlueStore::_txc_state_proc(TransContext *txc)
{
while (true) {
switch (txc->state) {
case TransContext::STATE_PREPARE:
txc->log_state_latency(logger, l_bluestore_state_prepare_lat);
if (txc->ioc.has_pending_aios()) { // 区分是否包含simple write,如果没有,直接执行后面的case
txc->state = TransContext::STATE_AIO_WAIT;
txc->had_ios = true;
_txc_aio_submit(txc); // 提交io请求
return; // 返回,等待io完成后的回调
}
// 注意没有break
case TransContext::STATE_AIO_WAIT:
txc->log_state_latency(logger, l_bluestore_state_aio_wait_lat);
_txc_finish_io(txc);
return;
…
}
}
}
这个线程涉及的latency有:
-
throttle latency
-
prepare latency
-
submit latency
BlockDevice::aio_thread
对于simple write,io执行完成后,会再次执行状态机函数_txc_state_proc,根据前面的状态STATE_AIO_WAIT,会执行函数_txc_finish_io,这个函数的主要目的是保证pg对应的OpSequencer中的txc按排队的先后顺序依次进入kv_sync_thread线程的队列(因为libaio可能乱序)。为什么必须保证先后顺序?原因是对pg中的同一个object可能连续提交多次写请求,每次对应一个txc,在osd层面通过pg lock保证顺序,依次提交到ObjectStore层面,ObjectStore也必须保证这样的顺序,不然可能发生数据错乱。
void BlueStore::_txc_finish_io(TransContext *txc)
{
OpSequencer *osr = txc->osr.get();
std::lock_guard<std::mutex> l(osr->qlock); // 获取OpSequencer中的锁,主要是保互斥访问txc队列
txc->state = TransContext::STATE_IO_DONE; // 设置状态
txc->ioc.running_aios.clear();
OpSequencer::q_list_t::iterator p = osr->q.iterator_to(*txc); // 定位到当前txc在队列中的位置
while (p != osr->q.begin()) {
–p;
if (p->state < TransContext::STATE_IO_DONE) { // 前面还有未完成io操作的txc,这个txc不能继续进行下去,等待前面的完成,所以直接return
return;
}
if (p->state > TransContext::STATE_IO_DONE) { // 前面以及进入下一个状态了,递增p并退出循环,下面接着处理当前的txc
++p;
break;
}
}
// 依次处理状态为STATE_IO_DONE的txc,会将txc放入kv_sync_thread的队列kv_queue和kv_queue_unsubmitted
do {
_txc_state_proc(&*p++);
} while (p != osr->q.end() && p->state == TransContext::STATE_IO_DONE);
......
}
对于deferred write,第一阶段将日志写入k/v中后,会继续准备写data的dbh然后提交写io请求,完成后由aio_thread回调,主要工作是设置状态STATE_DEFERRED_CLEANUP和将dbh入队列deferred_done_queue等待kv_sync_thread线程处理:
void BlueStore::_deferred_aio_finish(OpSequencer *osr)
{
......
std::lock_guard<std::mutex> l2(osr->qlock);
for (auto& i : b->txcs) {
TransContext *txc = &i;
txc->state = TransContext::STATE_DEFERRED_CLEANUP; // 设置状态
costs += txc->cost;
}
osr->qcond.notify_all();
throttle_deferred_bytes.put(costs); // 释放throttle资源
std::lock_guard<std::mutex> l(kv_lock);
deferred_done_queue.emplace_back(b); // 入队列
…
}
综上,可以看出,当IO执行完成后,要么是将txc放入队列,要么是将dbh放入队列,虽然对应不同队列,但是都是等待线程kv_sync_thread执行,这里sync的意思应该是同步,写完数据后,需要更新k/v,比如object的Onode信息,FreelistManager的磁盘空间信息等等,这些必须按顺序操作。
对于simple write情况,都是写新的磁盘block(如果是cow,也是写新的block,只是事务中k/v操作增加对旧的block的回收操作),所以先由aio_thread写block,再由kv_sync_thread同步元信息,无论什么时候挂掉,数据都不会损坏。
对于deferred write,kv_sync_thread第一次的commit操作中,将wal记录在了k/v系统中,然后进行后续的操作,异常的情况,可以通过回放wal,数据也不会损坏。
这个线程涉及的latency有:
-
aio wait latency
-
aio done latency(OpSequencer的保序操作可能会block)
BlueStore::kv_sync_thread
这个线程即为同步线程,处理三个队列,kv_queue表示需要执行commit的txc队列,deferred_done_queue表示已经完成wal操作的dbh队列,deferred_stable_queue表示已经落盘,等待清理日志。线程一直循环处理每个队列:
kv_queue: 将kv_queue中的txc存入kv_committing中,并提交给k/v系统执行,即执行操作db->submit_transaction,设置状态为STATE_KV_SUBMITTED,并将kv_committing中的txc放入kv_committing_to_finalize,等待线程kv_finalize_thread执行。
deferred_done_queue: 这个队列的dbh会有两种结果: 1) 如果没有做flush操作,会将其放入deferred_stable_queue待下次循环继续处理 2) 如果做了flush操作,说明数据已经落盘,即已经是stable的了,直接将其插入deferred_stable_queue队列,这里stable的意思就是数据已经写好了,前面k/v中记录的wal没用了,可以删除。
deferred_stable_queue: 依次操作dbh中的txc,将k/v中的wal日志删除,然后dbh入队列deferred_stable_to_finalize,等待线程kv_finalize_thread执行。
这个线程涉及的latency有:
-
kv queued
-
kv flush
-
kv commit
-
kv latency
BlueStore::kv_finalize_thread
这个线程即为清理线程,处理两个个队列kv_committing_to_finalize和deferred_stable_to_finalize。
kv_committing_to_finalize: 再次调用函数_txc_state_proc,设置状态为STATE_KV_DONE,并执行回调函数通知用户io操作完成。然后根据条件判读是否需要继续执行操作:
-
如果不是wal情况,即不包含deferred txc,设置状态为STATE_FINISHING,继续调用_txc_finish,设置状态为STATE_DONE,完成。
-
如果是wal情况,设置状态为STATE_DEFERRED_QUEUED,调用_deferred_queue准备写data的事务dbh(DeferredBatch,它有一个list成员,类型为txc),进一步调用_deferred_submit_unlock,然后bdev->aio_submit提交给块设备,此时aio类型为DeferredBatch。当io执行完成后,同样由线程aio thread执行回调函数_deferred_aio_finish,会将状态设置为STATE_DEFERRED_CLEANUP,并将事务放入队列deferred_done_queued。这个队列会由线程kv_sync_thread继续处理,先放入队列deferred_stable_queue,然后下次执行的时候,清除日志对应的k/v,将dbh放入队列deferred_stable_to_finalize,等待kv_finalize_thread继续执行。
deferred_stable_to_finalize: 遍历dbh中包含的txc,再次调用函数_txc_state_proc,设置状态为STATE_FINISHING,继续调用_txc_finish,设置状态为STATE_DONE,完成。
latency指标:
-
state kv committing
-
state kv done
-
state finishing
-
state deferred cleanup
deferred_finisher和finishers两个线程比较简单,只是执行一个回调,就不介绍了,其他每个线程基本上都是身兼数职,处理多个队列,功能分的不是很清楚,以至于阅读代码的时候稍显晦涩。这样做可能是出于性能考虑,避免跨度多个线程,中断IO的流水线,引入不必要的开销。
Deferred IO Order
还有一个问题需要注意,dbh执行的时候,通过libaio提交给BlockDevice执行写data的请求,这个时候的顺序怎么保证?实现的时候,BlueStore内部包含一个成员变量deferred_queue,这个队列包含需要执行deferred IO的OpSequencer,而每个OpSequencer包含两个成员变量,deferred_running和deferred_pending,类型为DeferredBatch,这个类包含一个txc的数组,如果pg有写请求,会在pg对应的OpSequencer中的deferred_pending中排队txc,待时机成熟的时候,一次性提交所有txc给libaio,执行完成后才会进行下一次提交,这样不会导致deferred IO写data的时候乱序。
void BlueStore::_deferred_queue(TransContext *txc)
{
deferred_lock.lock();
if (!txc->osr->deferred_pending && !txc->osr->deferred_running) {
deferred_queue.push_back(*txc->osr); // 排队osr
}
if (!txc->osr->deferred_pending) {
txc->osr->deferred_pending = new DeferredBatch(cct, txc->osr.get()); // 如果不存在,新建dbh
}
++deferred_queue_size;
txc->osr->deferred_pending->txcs.push_back(*txc); // 将txc追加到末尾
…
}
void BlueStore::_deferred_submit_unlock(OpSequencer *osr)
{
…
// 切换指针,保证每次操作完成后才会进行下一次提交
// submit的相关函数都会判断deferred_running是否为空
osr->deferred_running = osr->deferred_pending;
osr->deferred_pending = nullptr;
......
while (true) {
......
int r = bdev->aio_write(start, bl, &b->ioc, false); // 准备所有txc的写buffer
}
......
deferred_lock.unlock();
bdev->aio_submit(&b->ioc); // 一次性提交所有txc
}
void BlueStore::_kv_finalize_thread()
{
…
for (auto b : deferred_stable) {
auto p = b->txcs.begin();
while (p != b->txcs.end()) {
TransContext txc = &p;
p = b->txcs.erase(p);
_txc_state_proc(txc);
}
delete b; // 释放dbh
}
…
}
Summary
-
osd层面的一次写操作,在BlueStore层面可能对应多种情况:simple/deferred/simple+deferred。
-
分析中忽略了最复杂的流程,即添加事务的操作(_txc_add_transaction),这个函数会将写操作进行分类。分类的时候,可能会调用BlockDevice的aio_write,这个函数只是准备内存中的buffer,不会写数据,后续调用aio_submit的时候才是提交IO的写请求。前面提到的那个参考文章中的流程图是不对的。
-
只有在overwrite的时候才有可能发生deferred write,所以性能提升明显,没有了以前既要写日志,又要写数据盘,同时还有文件系统本身的损耗的情况。
-
对于对象存储,全部是simple write,性能应该提升非常明显,社区的文档说提升了三倍,待实测。
-
避免了object太多的情况下,文件系统性能的下降以及IO的抖动,存放海量小文件成为可能,只需要大量的k/v存放object元信息。