笔记:ML-LHY-1 Regression Gradient Descent
回归问题
损失函数
L ( w , b ) = ∑ n = 1 N ( y ^ n − ( b + w ⋅ x n ) ) 2 \mathrm{L}(w, b)=\sum_{n=1}^{N}\left(\hat{y}_{n}-\left(b+w \cdot x_{n}\right)\right)^{2} L(w,b)=n=1∑N(y^n−(b+w⋅xn))2
更一般的有( W = ( w 1 , w 2 , . . . , w i ) W=(w_1,w_2,...,w_i) W=(w1,w2,...,wi)):
L ( W , b ) = ∑ n = 1 N ( y ^ n − ( b + ∑ i = 1 K w i ⋅ x n ) ) 2 \mathrm{L}(W, b)=\sum_{n=1}^{N}\left(\hat{y}_{n}-\left(b+\sum_{i=1}^{K} w_i \cdot x_{n}\right)\right)^{2} L(W,b)=n=1∑N(y^n−(b+i=1∑Kwi⋅xn))2
N为训练数据量,K为优化类别数目
而对于多次则有(类别设为1种):
L ( W , b ) = ∑ n = 1 N ( y ^ n − ( b + ∑ i = 1 K ∑ j = 1 M w i j ⋅ x n j ) ) 2 \mathrm{L}(W, b)=\sum_{n=1}^{N}\left(\hat{y}_{n}-\left(b+\sum_{i=1}^{K}\sum_{j=1}^{M} w_{ij} \cdot x_{n}^{j}\right)\right)^{2} L(W,b)=n=1∑N(y^n−(b+i=1∑Kj=1∑Mwij⋅xnj))2
M为模型次数,次数过高会导致对权重更敏感,所以添加正则化项:
L ( W , b ) = ∑ n = 1 N ( y ^ n − ( b + ∑ i = 1 K ∑ j = 1 M w i j ⋅ x n j ) ) 2 + λ ∑ i = 1 K ∑ j = 1 M ( w i j ) 2 \mathrm{L}(W, b)=\sum_{n=1}^{N}\left(\hat{y}_{n}-\left(b+\sum_{i=1}^{K}\sum_{j=1}^{M} w_{ij} \cdot x_{n}^{j}\right)\right)^{2} +\lambda \sum_{i=1}^{K}\sum_{j=1}^{M} \left(w_{ij}\right)^{2} L(W,b)=n=1∑N(y^n−(b+i=1∑Kj=1∑Mwij⋅xnj))2+λi=1∑Kj=1∑M(wij)2
需要注意的是正则化项不需要添加偏置项,其目的只为了是函数更平滑,偏置项bias只会上下移动
梯度下降
按最简单形式,即一元(不包括偏置项)一次函数:
L ( w , b ) = ∑ n = 1 N ( y ^ n − ( b + w ⋅ x n ) ) 2 \mathrm{L}(w, b)=\sum_{n=1}^{N}\left(\hat{y}_{n}-\left(b+w \cdot x_{n}\right)\right)^{2} L(w,b)=n=1∑N(y^n−(b+w⋅xn))2
∂ L ∂ w = ∑ n = 1 10 2 ( y ^ n − ( b + w ⋅ x n ) ) ( − x n ) \frac{\partial L}{\partial w}= \sum_{n=1}^{10} 2\left(\hat{y}_{n}-\left(b+w \cdot x_{n}\right)\right)\left(-x_{n}\right) ∂w∂L=n=1∑102(y^n−(b+w⋅xn))(−xn)
∂ L ∂ b = ∑ n = 1 10 2 ( y ^ n − ( b + w ⋅ x n ) ) \frac{\partial L}{\partial b}= \sum_{n=1}^{10} 2\left(\hat{y}_{n}-\left(b+w \cdot x_{n}\right)\right) ∂b∂L=n=1∑102(y^n−(b+w⋅xn))
Compute ∂ L ∂ w ∣ w = w 0 , b = b 0 , ∂ L ∂ b ∣ w = w 0 , b = b 0 w 1 ← w 0 − η ∂ L ∂ w ∣ w = w 0 , b = b 0 b 1 ← b 0 − η ∂ L ∂ b ∣ w = w 0 , b = b 0 \text { Compute }\left.\left.\frac{\partial L}{\partial w}\right|_{w=w^{0}, b=b^{0},} \frac{\partial L}{\partial b}\right|_{w=w^{0}, b=b^{0}} \\ w^{1} \leftarrow w^{0}-\left.\eta \frac{\partial L}{\partial w}\right|_{w=w^{0}, b=b^{0}} \quad b^{1} \leftarrow b^{0}-\left.\eta \frac{\partial L}{\partial b}\right|_{w=w^{0}, b=b^{0}} Compute ∂w∂L∣∣∣∣w=w0,b=b0,∂b∂L∣∣∣∣∣w=w0,b=b0w1←w0−η∂w∂L∣∣∣∣w=w0,b=b0b1←b0−η∂b∂L∣∣∣∣w=w0,b=b0
Compute ∂ L ∂ w ∣ w = w 1 , b = b 1 , ∂ L ∂ b ∣ w = w 1 , b = b 1 w 2 ← w 1 − η ∂ L ∂ w ∣ w = w 1 , b = b 1 b 2 ← b 1 − η ∂ L ∂ b ∣ w = w 1 , b = b 1 \begin{aligned} &\text { Compute }\left.\left.\frac{\partial L}{\partial w}\right|_{w=w^{1}, b=b^{1},} \frac{\partial L}{\partial b}\right|_{w=w^{1}, b=b^{1}}\\ &w^{2} \leftarrow w^{1}-\left.\eta \frac{\partial L}{\partial w}\right|_{w=w^{1}, b=b^{1}} \quad b^{2} \leftarrow b^{1}-\left.\eta \frac{\partial L}{\partial b}\right|_{w=w^{1}, b=b^{1}} \end{aligned} Compute ∂w∂L∣∣∣∣w=w1,b=b1,∂b∂L∣∣∣∣∣w=w1,b=b1w2←w1−η∂w∂L∣∣∣∣w=w1,b=b1b2←b1−η∂b∂L∣∣∣∣w=w1,b=b1
对应上面,更一般的形式:
∇ L ( W ) = [ ∂ L ∂ w 0 , ∂ L ∂ w 1 , . . . , ∂ L ∂ w i ] T \nabla L(W) = [\frac{\partial L}{\partial w_0}, \frac{\partial L}{\partial w_1},...,\frac{\partial L}{\partial w_{i}}]^T ∇L(W)=[∂w0∂L,∂w1∂L,...,∂wi∂L]T
W k = W k − 1 + α ∇ L ( W k − 1 ) W^{k}=W^{k-1}+\alpha \nabla L\left(W^{k-1}\right) Wk=Wk−1+α∇L(Wk−1)
以上参考李宏毅老师视频和ppt,仅作为学习笔记交流使用
代码
import numpy as np
import matplotlib.pyplot as plt
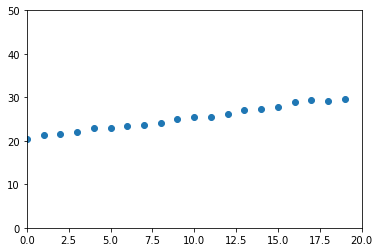
if y = 2 + 0.5 x y = 2 + 0.5x y=2+0.5x
def load_dataset(n):
k = 0.5
b = 20
noise = np.random.rand(n)
X = [x for x in range(n)]
y = [(k * X[i] + b + noise[i]) for i in range(n)]
return np.array(X).T, np.array(y).T
x, y = load_dataset(20)
plt.ylim(0, 50)
plt.xlim(0, 20)
plt.scatter(x, y)
假设损失函数
l o s s ( w ) = 1 2 m ∑ i = 1 m ( w 1 + w 2 x i − y i ) 2 loss(w) = \frac{1}{2m}\sum_{i=1}^m(w_1 + w_2 x_i - y_i)^2 loss(w)=2m1∑i=1m(w1+w2xi−yi)2
先对 w 1 w_1 w1求偏导
w 1 = w 1 − α 1 m ∑ i = 1 m ( w 1 + w 2 x i − y i ) w_1 = w_1 - \alpha \frac{1}{m} \sum_{i=1}^m(w_1 + w_2 x_i - y_i) w1=w1−αm1∑i=1m(w1+w2xi−yi)
对 w 2 w_2 w2求偏导
w 2 = w 2 − α 1 m ∑ i = 1 m ( w 1 + w 2 x i − y i ) x i w_2 = w_2 - \alpha \frac{1}{m} \sum_{i=1}^m(w_1 + w_2 x_i - y_i)x_i w2=w2−αm1∑i=1m(w1+w2xi−yi)xi
程序计算时,求每次的
1 m ∑ i = 1 m ( w 1 + w 2 x i − y i ) \frac{1}{m} \sum_{i=1}^m(w_1 + w_2 x_i - y_i) m1∑i=1m(w1+w2xi−yi)
def calc_loss(x,y,w1,w2):
J = 0
for i in range(len(x)):
mse = (w1 + x[i]*w2 -y[i])**2
J += mse
return J / (2*len(x))
loss = 10000000000
min_loss = 0.0001
w1 = 0;
w2 = 0;
m = len(x)
alpha = 0.1 # 学习率
max_itc = 100000
itc = 0
loss = calc_loss(x, y , w1, w2)
loss_pre = loss + min_loss+ 1
loss_array = [loss]
while abs(loss - loss_pre) > min_loss and itc < max_itc:
# g1
g1 = 0
for i in range(m):
g1 = g1 + w1 + w2 * x[i] - y[i]
g1 = g1 / m
w1_ = w1 - alpha * g1
# print(w1_)
# g2
g2 = 0
for i in range(m):
g2 = g2 = (w1 + w2 * x[i] - y[i]) * x[i]
g2 = g2 / m
w2_ = w2 - alpha * g2
w1 = w1_
w2 = w2_
#loss
loss_pre = loss
loss = calc_loss(x, y , w1, w2)
loss_array.append(loss)
# print(loss)
itc += 1
# loss_array
plt.plot(range(len(loss_array)), loss_array)
w1, w2
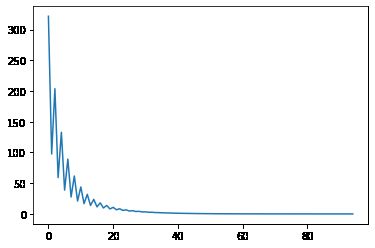
(20.683619269764357, 0.4669721730697502)