这篇文章用pandas对全球的人口数据做个简单分析。我收集全球各国1960-2019年人口数据,包含男女和不同年龄段,共6个文件。
pop_total.csv: 各国每年总人口
pop_female.csv:各国每年女性人口
pop_male.csv: 各国每年男性人口
pop_0_14.csv: 各国每年0-14岁人口
pop_15_64.csv: 各国每年15-64岁人口
pop_65up.csv:各国每年65岁以上人口
先用pandas读取文件数据
import pandas as pd
pop_total = pd.read_csv('./data/pop_total.csv', skiprows=4)
pop_total.info()
pop_total.csv文件存放各国每年总人口数据,格式如下
pop_total.head(2)

同样的方式,我们读取剩下的5个文件,对应的DataFrame分别是pop_female、pop_male、pop_0_14、pop_15_64、pop_65up。
为了直观观察全球人口分布,我们用pyecharts绘制2019年全球人口分布地图
from pyecharts import options as opts
from pyecharts.charts import Timeline, Map
pop_total_2019 = pop_total[['Country Name', '2019']]
# 修改俄罗斯的英文名以便pyecharts能识别
pop_total_2019.loc[200, 'Country Name'] = 'Russia'
pop_world_map = (
Map()
.add("2019年", pop_total_2019.values, "world", is_map_symbol_show=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="全球人口"),
visualmap_opts=opts.VisualMapOpts(max_=100000000), # 超过1亿人口颜色最深(红色)
)
)
pop_world_map.render_notebook()

因为我们有50年的数据,所以我们还可以绘制一个全球人口分布变化的动图,类似之前写的全球疫情变化趋势图。因为代码跟上面类似,这里就不贴,源码包里能找到。
上面的图里我们只能定性的看到人口分布,下面我们定量地看看2019年全球人口top10的国家。
# 2019年人口top10的国家
pop_total_2019_ordered = pop_total_2019.sort_values(by="2019" , ascending=False)
pop_total_2019_ordered.head()

排序后发现Country Name这列不只是单个国家,还包括了地区概念,这并不是我们想要的。记得之前做疫情地图的时候有一份国家中英文对应关系的名单,拿到这里用一下。
from countries_ch_to_en import countries_dict
pop_top10 = pop_total_2019_ordered[pop_total_2019_ordered['Country Name']\
.isin(countries_dict.keys())][:10]
pop_top10

这样看起来就正常了,用seaborn将其绘制出来
import seaborn as sns
sns.barplot(y=pop_top10['Country Name'], x=pop_top10['2019'])
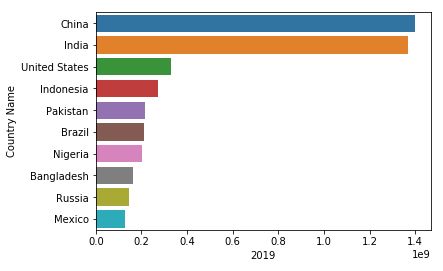
可以看到,中国人口仍然位居全球第一,紧随其后的是印度,三哥也是拼了。令我惊讶的是巴基斯坦那么小的国土,人口超2亿,全球排第五,真是方方面面都要跟三哥死磕。
看完人口绝对值的排行,我们再来看看从2000年值2019年近20年时间各国人口增长率
pop_tmp = pop_total[pop_total['Country Name']\
.isin(pop_top10['Country Name'])][['Country Name', '2000', '2019']]
pop_tmp['growth(%)'] = (pop_tmp['2019'] / pop_tmp['2000'] - 1) * 100
pop_tmp.sort_values(by="growth(%)" , ascending=False)
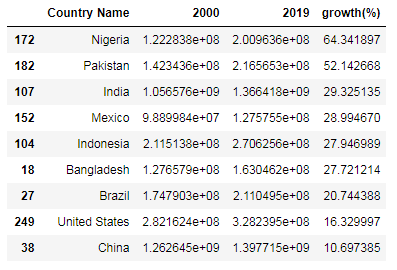
可以看到,中国虽然人口基数比较大,但近20年人口增长率确比较低,增加最快的top3分别是尼日利亚、巴基斯坦和印度。
看完总人口数据后,我们再看看性别分布,还是以2019年为例
columns = ['Country Name', '2019']
# 抽数据,关联
pop_sex_2019 = pop_total[columns].merge(pop_male[columns], on = 'Country Name')
# 列名重命名
pop_sex_2019.rename(columns={'2019_x': 'total', '2019_y': 'male'}, inplace=True)
# 筛选出国家
pop_sex_2019 = pop_sex_2019[pop_sex_2019['Country Name'].isin(countries_dict.keys())]
# 计算女性人口
pop_sex_2019['female'] = pop_sex_2019['total'] - pop_sex_2019['male']
# 女性占比与男性占比的差值
pop_sex_2019['diff'] = (pop_sex_2019['female'] - pop_sex_2019['male']) / pop_sex_2019['total'] * 100
# 男性人口占比高于女性的 top15
sex_diff_top15 = pop_sex_2019.sort_values(by='diff')[0:15]
sns.barplot(y=sex_diff_top15['Country Name'], x=sex_diff_top15['diff'])

第一名是卡塔尔,男性人口比女性高50%,咱们中国男女比例也是失衡的,男性人口占比比女性高2%。
再来看看女性占比比男性高的国家
sex_diff_top15 = pop_sex_2019.sort_values(by='diff', ascending=False)[0:15]
sns.barplot(y=sex_diff_top15['Country Name'], x=sex_diff_top15['diff'])
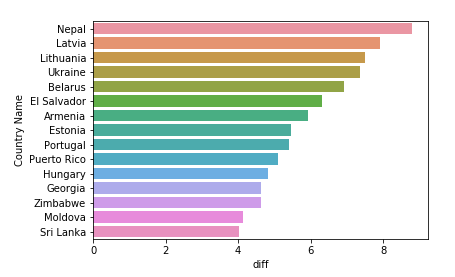
这个相差的幅度明显没那么大,top1也就差了8%,并且这些国家都不是人口大国。那我们来看看人口超过1亿的国家有哪些是女性占比超过男性
pop_sex_2019[pop_sex_2019['total'] > 100000000].sort_values(by='diff', ascending=False)[0:5]

可以看到日本、墨西哥、巴西和美国这四个人口大国女性占比超过了男性。
性别也了解的差不多了,我们再来看看年龄分布。因为我比较关注各国年轻人群的占比,所以我们先对各国0-14岁人口占比进行排序。
pop_0_14_2019 = pop_total[columns].merge(pop_0_14[columns], on = 'Country Name')
pop_0_14_2019.rename(columns={'2019_x': 'total', '2019_y': '0_14'}, inplace=True)
pop_0_14_2019['0_14_r(%)'] = pop_0_14_2019['0_14'] / pop_0_14_2019['total'] * 100
# 我们仍然只看大于1亿人的国家
pop_0_14_top = pop_0_14_2019[pop_0_14_2019['Country Name'].isin(countries_dict.keys())][pop_0_14_2019['total'] > 100000000]\
.sort_values(by='0_14_r(%)', ascending=False)[:15]
sns.barplot(y=pop_0_14_top['Country Name'], x=pop_0_14_top['0_14_r(%)'])

可以看到菲律宾、孟加拉国、印尼和印度等东南亚国家0-14岁人口占比远超中国,甚至美国也比我们要高。我们只有17%,这也是近几年世界工厂在往东南亚迁移的原因。
最后,我们再看看中国从1960年至2019年中国各年龄段人口占比的变化趋势
# 筛选我们需要的列
pop_0_14_ch = pop_0_14[pop_0_14['Country Name'] == 'China'].drop(['Country Name', 'Country Code', 'Indicator Name', 'Indicator Code',\
'Unnamed: 64'], axis=1)
#列(年份)转行
pop_0_14_ch_unstack = pop_0_14_ch.unstack()
# 重新构造DateFrame
pop_0_14_ch = pd.DataFrame(pop_0_14_ch_unstack.values, \
index=[x[0] for x in pop_0_14_ch_unstack.index.values], columns=['0_14'])
pop_0_14_ch.head()
同样的方式,处理一下其他两个年龄段
# 15-64岁
pop_15_64_ch = pop_15_64[pop_15_64['Country Name'] == 'China'].drop(['Country Name', 'Country Code', 'Indicator Name', 'Indicator Code',\
'Unnamed: 64'], axis=1)
pop_15_64_ch_unstack = pop_15_64_ch.unstack()
pop_15_64_ch = pd.DataFrame(pop_15_64_ch_unstack.values,\
index=[x[0] for x in pop_15_64_ch_unstack.index.values], columns=['15_64'])
# 65岁以上
pop_65up_ch = pop_65up[pop_65up['Country Name'] == 'China'].drop(['Country Name', 'Country Code', 'Indicator Name', 'Indicator Code',\
'Unnamed: 64'], axis=1)
pop_65up_ch_unstack = pop_65up_ch.unstack()
pop_65up_ch = pd.DataFrame(pop_65up_ch_unstack.values, \
index=[x[0] for x in pop_65up_ch_unstack.index.values], columns=['65up'])
将各年龄人口按照年份关联起来,然后计算总人口以及各年龄段人口占比
pop_age_level = pop_0_14_ch.merge(pop_15_64_ch.merge(pop_65up_ch, left_index=True, right_index=True), left_index=True, right_index=True)
pop_age_level['total'] = pop_age_level['0_14'] + pop_age_level['15_64'] + pop_age_level['65up']
pop_age_level['0_14(%)'] = pop_age_level['0_14'] / pop_age_level['total'] * 100
pop_age_level['15_64(%)'] = pop_age_level['15_64'] / pop_age_level['total'] * 100
pop_age_level['65up(%)'] = pop_age_level['65up'] / pop_age_level['total'] * 100
pop_age_level.head()

最后我们来画一个堆叠柱状图展示
pop_age_level['year'] = pop_age_level.index
pop_age_level.plot.bar(x='year', y=['0_14(%)', '15_64(%)', '65up(%)'], stacked=True, figsize=(15,8), fontsize=10, rot=60)

可以放大后看看,蓝色的是0-14岁人口,六七十年代,中国0-14岁人口占比40%多,算是挺高的了,随着80年代实行计划生育,0-14岁人口开始下降,一直降到现在的17%,少的有点可怜了。现在国家放开二胎,也是希望未来我们能有更多的年轻人,这样才能增强我们的国际竞争力。
我的分析就到这里了,有兴趣的朋友可以自行探索,数据和源码已经打包,公众号回复关键字人口即可。
欢迎公众号 「渡码」,输出别地儿看不到的干货。
