Kaggle超市客户分类-KMeans无监督案例
KMeans无监督案例:Kaggle超市客户分类
案例背景
现有超市购物中心客户的一些基本数据,如客户ID,年龄,性别,年收入和消费分数。消费分数是根据客户行为和购买数据等条件分配给客户的分数。
需要解决问题:利用现有资料,划分不同客户类型,以便可以了解哪些客户为超市优质客户,并向营销团队提供意见。
案例资料:链接:https://pan.baidu.com/s/1w04nEWJUgjgxulj3VixE2A 提取码:sfp3
项目
1.模块导入和数据读取
#导入对应的模块
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
#设置全部列显示和浮点数格式
pd.options.display.max_columns=None
pd.set_option('display.float_format',lambda x:'%.6f'%x)
#数据读取
df=pd.read_csv(open(r"C:\Users\angella.li\Desktop\案例\customer-segmentation-tutorial-in-python\Mall_Customers.csv"),encoding='utf-8',index_col=0)
#为了方便分析数据,需要重新定义列名
df=df.rename(columns={'Gender':'gender','Age':'age','Annual Income (k$)':'annual_income','Spending Score (1-100)':'spending_score'})
df.gender.replace(['Male','Female'],[1,0],inplace=True)#用数字表示性别
df.head(2)
数据读取结果

2.数据处理
#对缺失值处理
df.isnull().sum()

数据无缺失值。
3. 数据划分
第一步将数据标准化。
#计算出数据的均值和标准差
dfms=pd.concat([df.mean().to_frame(),df.std().to_frame()],axis=1).transpose()
dfms.index=['mean','std']
#数据标准化
df_scaled=pd.DataFrame()
for i in df.columns:
if (i=='gender'): df_scaled[i]=df[i]
else:
df_scaled[i]=(df[i] - dfms.loc['mean', i]) / dfms.loc['std', i]
df_scaled.head()

第二步选择最优质心点
#按照男女划分
dff=df_scaled.loc[df_scaled.gender==0].iloc[:,1:]
dfm=df_scaled.loc[df_scaled.gender==1].iloc[:,1:]
#选择最优的质心点数
def numbers_of_clusters(df):
wcss=[]
for i in range(1,20):
km=KMeans(n_clusters=i,random_state=0)
km.fit(df)
wcss.append(km.inertia_)#用来评估簇的个数是否合适
df_elbow=pd.DataFrame(wcss)
df_elbow=df_elbow.reset_index()
df_elbow.columns=['n_clusters','within_cluster_sum_of_square']
return df_elbow
#生成质心点
dff_elbow=numbers_of_clusters(dff)
dfm_elbow=numbers_of_clusters(dfm)
dfm_elbow

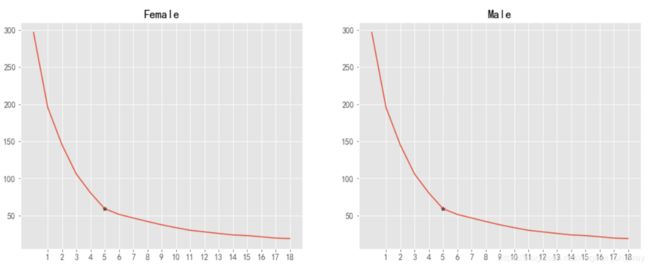
分别绘制折线图,选择方差最小值对应的质心点数。最终选择5作为数据的质心点数。
plt.subplot(1,2,1)
matplotlib.rcParams['font.family']='SimHei'
matplotlib.rcParams['figure.figsize']=(16,10)
matplotlib.rcParams['font.size']=12
plt.plot(dff_elbow.n_clusters,dff_elbow.within_cluster_sum_of_square)
plt.xticks(range(1,19,1))
plt.title('Female')
plt.scatter(x=dff_elbow.n_clusters[5:6],y=dff_elbow.within_cluster_sum_of_square[5:6],color='black',marker='*')
plt.subplot(1,2,2)
matplotlib.rcParams['font.family']='SimHei'
matplotlib.rcParams['figure.figsize']=(16,6)
matplotlib.rcParams['font.size']=12
plt.plot(dfm_elbow.n_clusters,dff_elbow.within_cluster_sum_of_square)
plt.xticks(range(1,19,1))
plt.title('Male')
plt.scatter(x=dfm_elbow.n_clusters[5:6],y=dff_elbow.within_cluster_sum_of_square[5:6],color='black',marker='*')
第三步划分客户分类
def k_means(n_clusters,df,gender):
kmf=KMeans(n_clusters=n_clusters,random_state=0)
kmf.fit(df)
centroids=kmf.cluster_centers_
cdf=pd.DataFrame(centroids,columns=df.columns)
cdf['gender']=gender
cdf['count']=pd.Series(kmf.labels_).value_counts()
return cdf
df1=k_means(5,dfm,'Male')
df2=k_means(5,dff,'Female')
dfc_scaled=pd.concat([df1,df2],axis=0)
dfc_scaled

#数据非标准化
dfc=pd.DataFrame()
for i in dfc_scaled.columns:
if (i=='gender'):dfc[i]=dfc_scaled[i]
elif (i=='count'):dfc[i]=dfc_scaled[i]
else:
dfc[i]=(dfc_scaled[i]*dfms.loc['std',i]+dfms.loc['mean',i])
dfc[i]=dfc[i].astype(int)
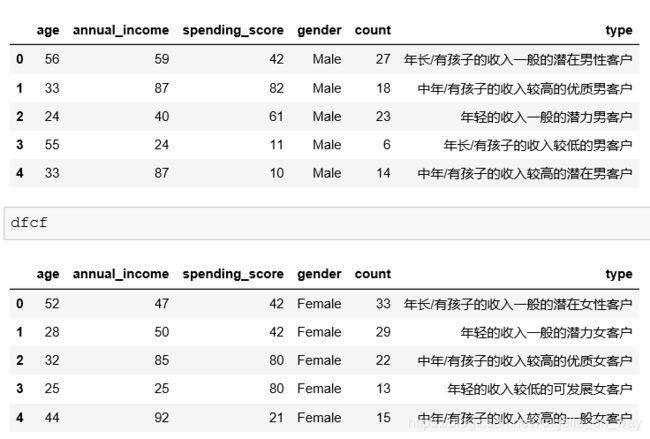
dfc

最后完成数据划分
#分类
dfc['type']=1
a_i=dfms.loc['mean']['annual_income']
s_s=dfms.loc['mean']['spending_score']
dfcm=dfc[dfc['gender']=='Male']
dfcf=dfc[dfc['gender']=='Female']
remark=['年长/有孩子的收入一般的潜在男性客户','中年/有孩子的收入较高的优质男客户','年轻的收入一般的潜力男客户','年长/有孩子的收入较低的男客户','中年/有孩子的收入较高的潜在男客户']
dfcm['type']=pd.Series(remark)
remark=['年长/有孩子的收入一般的潜在女性客户','年轻的收入一般的潜力女客户','中年/有孩子的收入较高的优质女客户','年轻的收入较低的可发展女客户','中年/有孩子的收入较高的一般女客户']
dfcf['type']=pd.Series(remark)
以上为超市客户分类全部处理。