当我说要做大数据工程师时他们都笑我,直到七个月后……
1
前言
之前写了篇面经 《一个月面试近20家大中小厂,在互联网寒冬突破重围,成功上岸!》,有不少小伙伴留言和私信我关于大数据学习路线,以及咨询我一些关于有工作经验想转行大数据的问题。
因此我花了一个月时间整理了一份我当初学习的大数据学习路线,从最基础的大数据集群搭建开始,希望能帮助到大家。
不过在开始之前,我还是希望大家能想清楚,如果自己很迷茫,为了什么原因想往大数据方向发展,还有就是我就想问一下,你的专业是什么,对于计算机/软件,你的兴趣是什么?
是计算机专业,对操作系统、硬件、网络、服务器感兴趣?是软件专业,对软件开发、编程、写代码感兴趣?还是数学、统计学专业,对数据和数字特别感兴趣?
这其实也就关系到大数据的三个发展方向:
1、平台搭建/优化/运维/监控
2、大数据开发/设计/架构
3、数据分析/挖掘
2
大数据技术概览
现如今,正式为了应对大数据的这几个特点,开源的大数据框架越来越多,越来越强,先列举一些常见的:
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
实时计算:Storm、Spark Streaming、Flink
NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop
任务调度:Oozie
……
眼花了吧,上面的有30多种吧,别说精通了,全部都会使用的,估计也没几个。
就我个人而言,主要目前是在第二个方向(开发/设计/架构),那我就从大数据的发展史讲起。由于自己经验有限,本文内容参考了圈内不少老师的观点,供大家参考和互相学习。
3
大数据的发展史
关于大数据的发展史,我觉得骆俊武老师在《AI 时代,还不了解大数据?》一文中讲的非常清楚。大数据在它近三十年的发展史中,共经历了5个阶段。
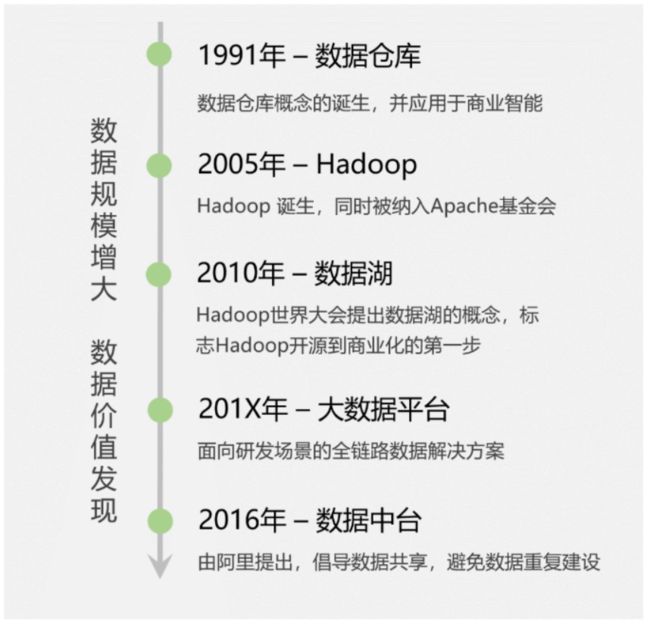
启蒙阶段:数据仓库的出现。传统的数据仓库,第一次明确了数据分析的应用场景,并采用单独的解决方案去实现,不依赖业务数据库。

技术变革:Hadoop诞生。2003年,Google公布了3篇鼻祖型论文俗称「谷歌三驾马车」),包括:分布式处理技术MapReduce,列式存储BigTable,分布式文件系统GFS,这3篇论文奠定了现代大数据技术的理论基础。
数据工厂时代:大数据平台兴起。大数据平台(平台即服务的思想,PaaS)应运而生,它让数据像在流水线上一样快速完成加工,原始数据变成指标,出现在各个报表或者数据产品中。
数据价值时代:阿里提出数据中台。极富远见的马云爸爸此时喊出了数据中台」的概念,「One Data,One Service」的口号开始响彻大数据界。
数据中台的核心思想是:避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能业务。
4
大数据方面核心技术有哪些?
大数据的概念比较抽象,而大数据技术栈的庞大程度将让你叹为观止。
大数据技术的体系庞大且复杂,基础的技术主要分为下面几个方面:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。

数据采集:这是大数据处理的第一步,数据来源主要是两类,第一类是各个业务系统的关系数据库,通过Sqoop或者Cannal等工具进行定时抽取或者实时同步;第二类是各种埋点日志,通过Flume进行实时收集。
数据存储:收集到数据后,下一步便是将这些数据存储在HDFS中,实时日志流情况下则通过Kafka输出给后面的流式计算引擎。
数据分析:这一步是数据处理最核心的环节,包括离线处理和流处理两种方式,对应的计算引擎包括MapReduce、Spark、Flink等,处理完的结果会保存到已经提前设计好的数据仓库中,或者HBase、Redis、RDBMS等各种存储系统上。
数据应用:包括数据的可视化展现、业务决策、或者AI等各种数据应用场景。
通过上述的内容,可能大家对大数据都有了初步的了解,接下来就是核心的部分,因为任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。大数据所需学习的内容纷繁复杂,难度较大,有一个合理的大数据技术栈学习路线图帮忙理清思路就显得尤为必要。
5
大数据下的数仓体系架构
数据仓库是从业务角度出发的一种数据组织形式,它是大数据应用和数据中台的基础。数仓系统一般采用下图所示的分层结构。
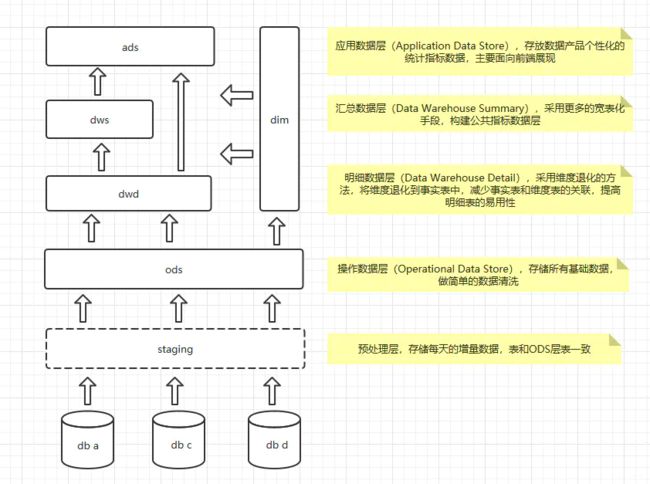
按照这种分层方式,我们的开发重心就在dwd层,就是明细数据层,这里主要是一些宽表,存储的还是明细数据;到了dws层,我们就会针对不同的维度,对数据进行聚合了,按道理说,dws层算是集市层,这里一般按照主题进行划分,属于维度建模的范畴;ads就是偏应用层,各种报表的输出了。
6
大数据学习指南
我会再出一期大数据学习的相关书籍的文章,同样我也非常推荐大家去阿里云学习大数据ACA和大数据ACP(两个是阿里云的大数据认证,值得一考!)
下面,是我用阿里云的大数据开发组件设计的一套系统架构图(具体的设计思路,有机会我会和大家再细说) 。
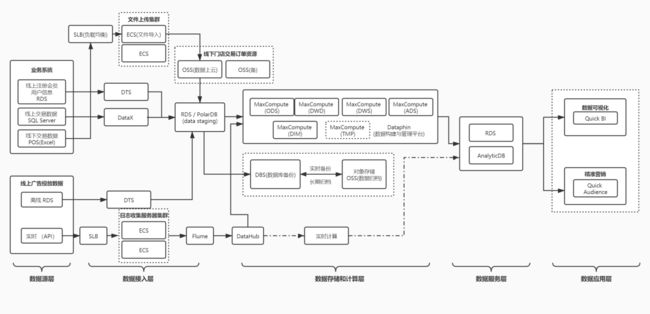
物理架构设计图
到这里,得强烈推荐阿里的这本书,《大数据之路:阿里巴巴大数据实践》 !精华大作啊!!
具体的大数据开源框架的学习指南,我会在后面再详细讲述,这里我们可以看一下一位这份大数据开源框架学习脑图:
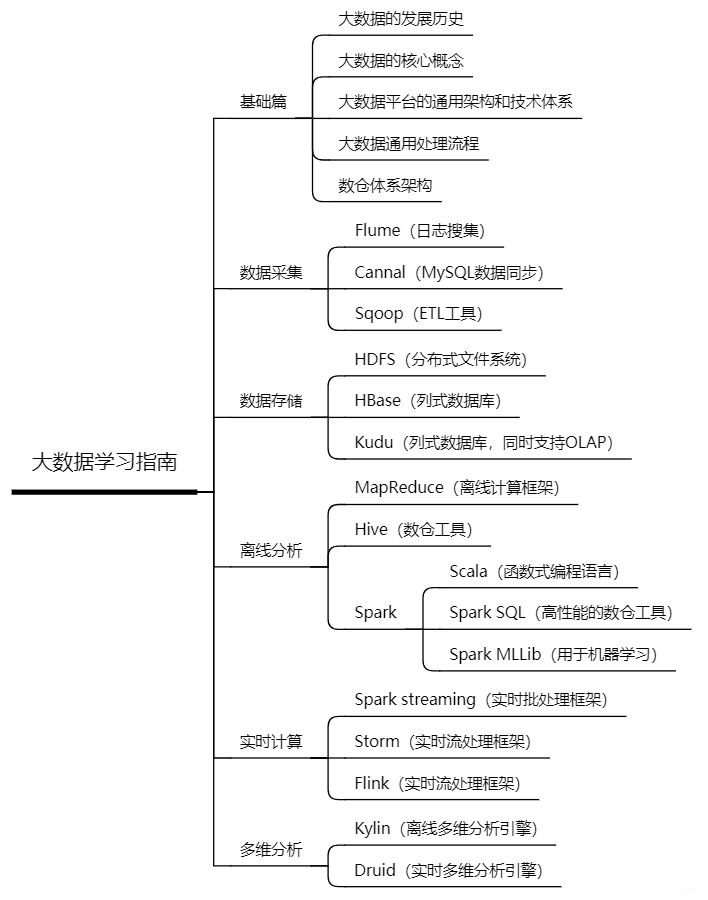
7
写在最后
写在最后,毕竟博主入行也就两年时间。然后对于一些小伙伴的问题,我尽量,针对不同的人给一些不同的建议。
对应届生
个人觉得应届生应该打好基础,大学本科一般都会开设数据结构,算法基础,操作系统,编译原理,计算机网络等课程。这些课程一定要好好学,基础扎实了学其他东西问题都不大,而且好多大公司面试都会问这些东西。如果你准备从事IT行业,这些东西对你会很有帮助。
至于学什么语言,我觉得对大数据行业来说,Java还是比较多。有时间有兴趣的话可以学学Scala,这个语言写Spark比较棒。
集群环境一定要搭起来。有条件的话可以搭一个小的分布式集群,没条件的可以在自己电脑上装个虚拟机然后搭一个伪分布式的集群。一来能帮助你充分认识Hadoop,而来可以在上面做点实际的东西。你所有踩得坑都是你宝贵的财富。
然后就可以试着写一些数据计算中常见的去重,排序,表关联等操作。
对有工作经验想转行的
主要考察三个方面,一是基础,二是学习能力,三是解决问题的能力。
基础很好考察,给几道笔试题做完基本上就知道什么水平了。
学习能力还是非常重要的,毕竟写Javaweb和写Mapreduce还是不一样的。大数据处理技术目前都有好多种,而且企业用的时候也不单单使用一种,再一个行业发展比较快,要时刻学习新的东西并用到实践中。
解决问题的能力在什么时候都比较重要,数据开发中尤为重要,我们同常会遇到很多数据问题,比如说最后产生的BI数据对不上,一般来说一份最终的数据往往来源于很多原始数据,中间又经过了N多处理。要求你对数据敏感,并能把握问题的本质,追根溯源,在尽可能短的时间里解决问题。
基础知识好加强,换工作前两周复习一下就行。学习能力和解决问题的能力就要在平时的工作中多锻炼。社招的最低要求就上面三点,如果你平日还自学了一些大数据方面的东西,都是很好的加分项。
以上是个人的一些经历和见解,希望能帮到你,欢迎大家关注我的公众号:云祁QI。

我是「云祁」,一枚热爱技术、会写诗的大数据开发猿,Love&Peace!