【Keras学习笔记】4:Softmax多分类预测Iris鸢尾花数据集(one-hot编码)
读入数据和预处理
import keras
from keras import layers
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
Using TensorFlow backend.
df = pd.read_csv("./data/Iris.csv")
df.head()
| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
df.info()
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
Id 150 non-null int64
SepalLengthCm 150 non-null float64
SepalWidthCm 150 non-null float64
PetalLengthCm 150 non-null float64
PetalWidthCm 150 non-null float64
Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.1+ KB
看到最后一列(输出的种类)不是数值的,现在要把它数值化,用one-hot编码。
# 看一下有几类
df.Species.unique()
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)
# 对Species这一列进行one-hot编码,然后加入到DataFrame里
df = df.join(pd.get_dummies(df.Species))
del df["Species"]
df.head()
| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Iris-setosa | Iris-versicolor | Iris-virginica | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | 1 | 0 | 0 |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | 1 | 0 | 0 |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | 1 | 0 | 0 |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | 1 | 0 | 0 |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | 1 | 0 | 0 |
现在所有同种花都是挨在一起放的,现在做一个shuffle,不然不利于训练(注意一定要在划分x,y之前)。
# 生成该区间的随意唯一索引
index = np.random.permutation(len(df))
# 用生成的乱的索引就能将其打乱了
df = df.iloc[index ,:]
# 划分训练特征,标签
x = df.iloc[:, 1:-3]
y = df.iloc[:, -3:]
x.head(), y.head()
( SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm
5 5.4 3.9 1.7 0.4
88 5.6 3.0 4.1 1.3
84 5.4 3.0 4.5 1.5
27 5.2 3.5 1.5 0.2
121 5.6 2.8 4.9 2.0,
Iris-setosa Iris-versicolor Iris-virginica
5 1 0 0
88 0 1 0
84 0 1 0
27 1 0 0
121 0 0 1)
x.shape, y.shape
((150, 4), (150, 3))
建立模型
model = keras.Sequential()
model.add(layers.Dense(3, input_dim=4, activation='softmax'))
WARNING:tensorflow:From E:\MyProgram\Anaconda\envs\krs\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 3) 15
=================================================================
Total params: 15
Trainable params: 15
Non-trainable params: 0
_________________________________________________________________
这里参数量15=3*4+3,12个w和3个bias。
编译模型
# 之前Logistic回归二分类用的binary_crossentropy二元交叉熵,这里多分类就要用categorical_crossentropy
model.compile(
optimizer='adam',
loss='categorical_crossentropy', # 注意目标数据一定是one-hot编码的,才用这个计算softmax交叉熵
metrics=['acc']
)
训练数据
history = model.fit(x, y, epochs=300, verbose=0)
WARNING:tensorflow:From E:\MyProgram\Anaconda\envs\krs\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
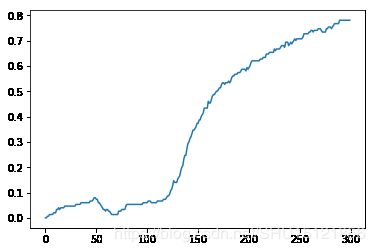
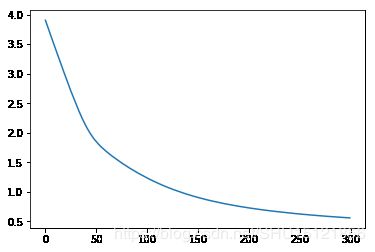
绘制loss和acc变化曲线
plt.plot(range(300),history.history.get('loss'))
[]
plt.plot(range(300),history.history.get('acc'))
[]