Flink1.10的特性剖析
文章来源:zhisheng
Flink 1.10 release 文档描述了一些比较重要的点,比如配置、操作、依赖、1.9 版本和 1.10 版本之间的区别,如果你准备将 Flink 升级到 1.10 版本,建议仔细看完下面的内容。
集群和部署
•文件系统需要通过插件的方式加载•Flink 客户端根据配置的类加载策略加载,parent-first 和 child-first 两种方式•允许在所有的 TaskManager 上均匀地分布任务,需要在 flink-conf.yaml 配置文件中配置 cluster.evenly-spread-out-slots: true 参数•高可用存储目录做了修改,在 HA_STORAGE_DIR/HA_CLUSTER_ID 下,HA_STORAGE_DIR 路径通过 high-availability.storageDir 参数配置,HA_CLUSTER_ID 路径通过 high-availability.cluster-id 参数配置•当使用 -yarnship 命令参数时,资源目录和 jar 文件会被添加到 classpath 中•移除了 --yn/--yarncontainer 命令参数•移除了 --yst/--yarnstreaming 命令参数•Flink Mesos 会拒绝掉所有的过期请求•重构了 Flink 的调度程序,其目标是使调度策略在未来可以定制•支持 Java 11,当使用 Java 11 启动 Flink 时,会有些 WARNING 的日志提醒,注意:Cassandra、Hive、HBase 等 connector 没有使用 Java 11 测试过
内存管理
•全新的 Task Executor 内存模型,会影响 standalone、YARN、Mesos、K8S 的部署,JobManager 的内存模型没有修改。如果你在没有调整的情况下,重用以前的 Flink 配置,则新的内存模型可能会导致 JVM 的计算内存参数不同,从而导致性能的变化。
以下选项已经删除,不再起作用:

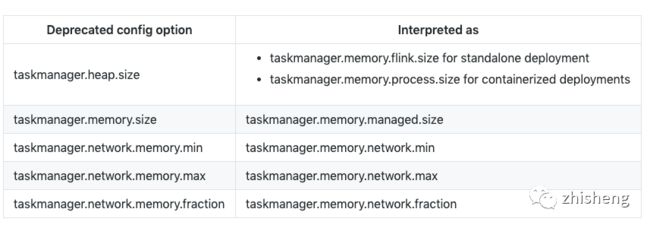
以下选项已经替换成其他的选项:
•RocksDB State Backend 内存可以控制,用户可以调整 RocksDB 的写/读内存比率 state.backend.rocksdb.memory.write-buffer-ratio(默认情况下 0.5)和为索引/过滤器保留的内存部分 state.backend.rocksdb.memory.high-prio-pool-ratio(默认情况下0.1)•细粒度的算子(Operator)资源管理,配置选项 table.exec.resource.external-buffer-memory,table.exec.resource.hash-agg.memory,table.exec.resource.hash-join.memory,和 table.exec.resource.sort.memory 已被弃用
Table API 和 SQL
•将 ANY 类型重命名为 RAW 类型,该标识符 raw 现在是保留关键字,在用作 SQL 字段或函数名称时必须转义•重命名 Table Connector 属性,以便编写 DDL 语句时提供更好的用户体验,比如 Kafka Connector 属性 connector.properties 和 connector.specific-offsets、Elasticsearch Connector 属性 connector.hosts•之前与临时表和视图进行交互的方法已经被弃用,目前使用 createTemporaryView()•移除了 ExternalCatalog API(ExternalCatalog、SchematicDescriptor、MetadataDescriptor、StatisticsDescriptor),建议使用新的 Catalog API
配置
•ConfigOptions 如果无法将配置的值解析成所需要的类型,则会抛出 IllegalArgumentException 异常,之前是会返回默认值•增加默认的重启策略延迟时间(fixed-delay 和 failure-rate 已经默认是 1s,之前是 0)•简化集群级别的重启策略配置,现在集群级别的重启策略仅由 restart-strategy 配置和是否开启 Checkpoint 确定•默认情况下禁用内存映射的 BoundedBlockingSubpartition•移除基于未认证的网络流量控制•移除 HighAvailabilityOptions 中的 HA_JOB_DELAY 配置
状态(State)
•默认开启 TTL 的状态后台清理•弃用 StateTtlConfig#Builder#cleanupInBackground()•使用 RocksDBStateBackend 时,默认将计时器存储在 RocksDB 中,之前是存储在堆内存(Heap)中•StateTtlConfig#TimeCharacteristic 已经被移除,目前使用 StateTtlConfig#TtlTimeCharacteristic•新增 MapState#isEmpty() 方法来检查 MapState 是否为空,该方法比使用 mapState.keys().iterator().hasNext() 的速度快 40%•RocksDB 升级,发布了自己的 FRocksDB(基于 RocksDB 5.17.2 版本),主要是因为高版本的 RocksDB 在某些情况下性能会下降•默认禁用 RocksDB 日志记录,需要启用的话需要利用 RocksDBOptionsFactory 创建 DBOptions 实例,并通过 setInfoLogLevel 方法设置 INFO_LEVEL•优化从 RocksDB Savepoint 恢复的机制,以前如果从包含大型 KV 对的 RocksDB Savepoint 恢复时,用户可能会遇到 OOM。现在引入了可配置的内存限制,RocksDBWriteBatchWrapper 默认值为 2MB。RocksDB的WriteBatch 将在达到内存限制之前刷新。可以在 flink-conf.yml 中修改 state.backend.rocksdb.write-batch-size 配置
PyFlink
•不再支持 Python2
监控
•InfluxdbReporter 会跳过 Inf 和 NaN(InfluxDB 不支持的类型,比如 Double.POSITIVE_INFINITY, Double.NEGATIVE_INFINITY, Double.NaN)
连接器(Connectors)
•改变 Kinesis 连接器的 License
接口更改
•ExecutionConfig#getGlobalJobParameters() 不再返回 null•MasterTriggerRestoreHook 中的 triggerCheckpoint 方法必须时非阻塞的•HA 服务的客户端/服务器端分离,HighAvailabilityServices 已分离成客户端 ClientHighAvailabilityServices 和集群端 HighAvailabilityServices•HighAvailabilityServices#getWebMonitorLeaderElectionService() 标记过期•LeaderElectionService 接口做了更改•弃用 Checkpoint 锁•弃用 OptionsFactory 和 ConfigurableOptionsFactory 接口
参考:https://github.com/apache/flink/blob/master/docs/release-notes/flink-1.10.zh.md
看了下官方的这份新版本的介绍,感觉还缺少很多新功能的介绍,比如:
•在 1.10 版本中把 Blink 版本的哪些功能整合过来了•竟然没有写 Flink 对原生 Kubernetes 的集成•PyFlink 的介绍是认真的吗?•对 Hive 的生产级别集成,完全没有提及呀•Table API/SQL 优化点讲得不太多
可能因为篇幅的问题,还有很多特性都没有讲解出来,得我们自己去找源码学习!