可以当做笔记的前端面试题(一:HTML和CSS、JS基础)
这些面试题都来自于网络,只记录了一部分,以后可以当做笔记来看。
一、HTML和CSS
1、为什么利用多个域名来存储网站资源会更有效?
- CDN缓存更方便
- 突破浏览器并发限制
- 节约cookie带宽
- 节约主域名的连接数,优化页面响应速度
- 防止不必要的安全问题
2、请描述一下cookies,sessionStorage和localStorage的区别?
cookie- 数据的声明周期:一般在服务器生成,可以设置有效时间。如果在浏览器端设置
cookie,默认是关闭浏览器失效 - 存放数据的大小一般4k左右
- 与服务器端的通信:每次都会携带在HTTP请求头中,如果使用
cookie保存过多数据会带来性能问题 - 易用性:需要程序员自己封装,原生的
cookie接口不友好
- 数据的声明周期:一般在服务器生成,可以设置有效时间。如果在浏览器端设置
localStorage和sessionStorage- 数据的声明周期:
localStorage除非手动清除,否则永久保存;sessionStorage仅在当前回话下有效,关闭页面或关闭浏览器后会被清除 - 存放数据的大小:一般为5MB左右
- 仅仅在客户端(浏览器)中保存,不参与服务器的通信
- 易用性:原生接口可以接受,也可以再次封装来对Object和Array有更好的支持
- 数据的声明周期:
3、知道的网页制作会用到的图片格式有哪些?
png-8,png-24,jpeg,gif,svg。
但是上面的那些都不是面试官想要的最后答案。面试官希望听到是Webp。(是否有关注新技术,新鲜事物)
科普一下Webp:WebP格式,谷歌(google)开发的一种旨在加快图片加载速度的图片格式。图片压缩体积大约只有JPEG的2/3,并能节省大量的服务器带宽资源和数据空间。Facebook Ebay等知名网站已经开始测试并使用WebP格式。
在质量相同的情况下,WebP格式图像的体积要比JPEG格式图像小40%
4、一个页面上有大量的图片(大型电商网站),加载很慢,你有哪些方法优化这些图片的加载,给用户更好的体验。
- 图片懒加载:在页面上的未可视区域可以添加一个滚动条事件,判断图片位置与浏览器顶端的距离与页面的距离,如果前者小于后者,优先加载。
如果为幻灯片、相册等,可以使用图片预加载技术,将当前展示图片的前一张和后一张优先下载。 - 如果图片为css图片,可以使用CSSsprite,SVGsprite,Iconfont、Base64等技术。
- 如果图片过大,可以使用特殊编码的图片,加载时会先加载一张压缩的特别厉害的缩略图,以提高用户体验。
- 如果图片展示区域小于图片的真实大小,则因在服务器端根据业务需要先行进行图片压缩,图片压缩后大小与展示一致。
5、谈谈以前端角度出发做好SEO需要考虑什么?
- 了解搜索引擎如何抓取网页和如何索引网页
你需要知道一些搜索引擎的基本工作原理,各个搜索引擎之间的区别,搜索机器人(SE robot 或叫 web crawler)如何进行工作,搜索引擎如何对搜索结果进行排序等等。 - Meta标签优化
主要包括主题(Title),网站描述(Description),和关键词(Keywords)。还有一些其它的隐藏文字比如Author(作者),Category(目录),Language(编码语种)等。 - 如何选取关键词并在网页中放置关键词
搜索就得用关键词。关键词分析和选择是SEO最重要的工作之一。首先要给网站确定主关键词(一般在5个上下),然后针对这些关键词进行优化,包括关键词密度(Density),相关度(Relavancy),突出性(Prominency)等等。 - 了解主要的搜索引擎
虽然搜索引擎有很多,但是对网站流量起决定作用的就那么几个。比如英文的主要有Google,Yahoo,Bing等;中文的有百度,搜狗,有道等。不同的搜索引擎对页面的抓取和索引、排序的规则都不一样。还要了解各搜索门户和搜索引擎之间的关系,比如AOL网页搜索用的是Google的搜索技术,MSN用的是Bing的技术。 - 主要的互联网目录
Open Directory自身不是搜索引擎,而是一个大型的网站目录,他和搜索引擎的主要区别是网站内容的收集方式不同。目录是人工编辑的,主要收录网站主页;搜索引擎是自动收集的,除了主页外还抓取大量的内容页面。 - 按点击付费的搜索引擎
搜索引擎也需要生存,随着互联网商务的越来越成熟,收费的搜索引擎也开始大行其道。最典型的有Overture和百度,当然也包括Google的广告项目Google Adwords。越来越多的人通过搜索引擎的点击广告来定位商业网站,这里面也大有优化和排名的学问,你得学会用最少的广告投入获得最多的点击。 - 搜索引擎登录
网站做完了以后,别躺在那里等着客人从天而降。要让别人找到你,最简单的办法就是将网站提交(submit)到搜索引擎。如果你的是商业网站,主要的搜索引擎和目录都会要求你付费来获得收录(比如Yahoo要299美元),但是好消息是(至少到目前为止)最大的搜索引擎Google目前还是免费,而且它主宰着60%以上的搜索市场。 - 链接交换和链接广泛度(Link Popularity)
网页内容都是以超文本(Hypertext)的方式来互相链接的,网站之间也是如此。除了搜索引擎以外,人们也每天通过不同网站之间的链接来Surfing(“冲浪”)。其它网站到你的网站的链接越多,你也就会获得更多的访问量。更重要的是,你的网站的外部链接数越多,会被搜索引擎认为它的重要性越大,从而给你更高的排名。 - 合理的标签使用
6、CSS中可以通过哪些属性定义,使得一个DOM元素不显示在浏览器可视范围内?
- 最基本的:
设置display属性为none,或者设置visibility属性为hidden - 技巧性:
设置宽高为0,设置透明度为0,设置z-index位置在-1000em
7、超链接访问过后hover样式就不出现的问题是什么?如何解决?
答案:被点击访问过的超链接样式不在具有hover和active了,解决方法是改变CSS属性的排列顺序: L-V-H-A(link,visited,hover,active)
8、什么是外边距重叠?重叠的结果是什么?
外边距重叠就是margin-collapse。
在CSS当中,相邻的两个盒子(可能是兄弟关系也可能是祖先关系)的外边距可以结合成一个单独的外边距。这种合并外边距的方式被称为折叠,并且因而所结合成的外边距称为折叠外边距。
折叠结果遵循下列计算规则:
- 两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值。
- 两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值。
- 两个外边距一正一负时,折叠结果是两者的相加的和。
9、px和em的区别。
px和em都是长度单位,区别是,px的值是固定的,指定是多少就是多少,计算比较容易。em得值不是固定的,并且em会继承父级元素的字体大小。
浏览器的默认字体高都是16px。所以未经调整的浏览器都符合: 1em=16px。那么12px=0.75em, 10px=0.625em。
10、Sass、LESS是什么?大家为什么要使用他们?
- 他们是CSS预处理器。他是CSS上的一种抽象层。他们是一种特殊的语法/语言编译成CSS。
例如Less是一种动态样式语言. 将CSS赋予了动态语言的特性,如变量,继承,运算, 函数. LESS 既可以在客户端上运行 (支持IE 6+, Webkit, Firefox),也可一在服务端运行 (借助 Node.js)。 - 为什么要使用它们?
- 结构清晰,便于扩展。
- 可以方便地屏蔽浏览器私有语法差异。这个不用多说,封装对浏览器语法差异的重复处理,减少无意义的机械劳动。
- 可以轻松实现多重继承。
- 完全兼容 CSS 代码,可以方便地应用到老项目中。LESS 只是在 CSS 语法上做了扩展,所以老的 CSS 代码也可以与 LESS 代码一同编译。
11、CSS中link和@import的区别是:
link是html的标签,不存在什么兼容问题,而@import是CSS提供的,只有在ie5以上版本才可以被识别,在页面加载的时候,link会同时被加载,而@import引用的CSS会在页面加载完成后才会加载引用
Link引入样式的权重大于@import的引用(@import是将引用的样式导入到当前的页面中)
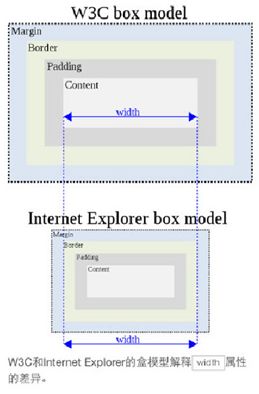
12、简介盒子模型:
CSS的盒子模型有两种:IE盒子模型、标准的W3C盒子模型模型
盒模型:内容、内边距、外边距(一般不计入盒子实际宽度)、边框
13、html常见兼容性问题?
- 双边距BUG float引起的 使用display
- 3像素问题 使用float引起的 使用dislpay:inline -3px
- 超链接hover 点击后失效 使用正确的书写顺序 link visited hover active
- Ie z-index问题 给父级添加position:relative
- Png 透明 使用js代码 改
- Min-height 最小高度 !Important 解决’
- select 在ie6下遮盖 使用iframe嵌套
- 为什么没有办法定义1px左右的宽度容器(IE6默认的行高造成的,使用over:hidden,zoom:0.08 line-height:1px)
- IE5-8不支持opacity,解决办法:
.opacity {
opacity: 0.4
filter: alpha(opacity=60); /* for IE5-7 /
-ms-filter: “progid:DXImageTransform.Microsoft.Alpha(Opacity=60)”; / for IE 8*/
} - IE6不支持PNG透明背景,解决办法: IE6下使用gif图片
14、前端页面有哪三层构成,分别是什么?作用是什么?
答:结构层 Html 表示层 CSS 行为层 js。
15、列出display的值,说明他们的作用。position的值, relative和absolute定位原点是?
- block 像块类型元素一样显示。
none 缺省值。向行内元素类型一样显示,还有隐藏元素。
inline-block 象行内元素一样显示,但其内容象块类型元素一样显示。
list-item 象块类型元素一样显示,并添加样式列表标记。 - position的值
*absolute
生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定位。
*fixed (老IE不支持)
生成绝对定位的元素,相对于浏览器窗口进行定位。
- relative
生成相对定位的元素,相对于其正常位置进行定位。 - static 默认值。没有定位,元素出现在正常的流中
*(忽略 top, bottom, left, right z-index 声明)。 - inherit 规定从父元素继承 position 属性的值。
16、浏览器标准模式和怪异模式之间的区别是什么?
怪异模式:在HTML和CSS的标准化未完成之前,各个浏览器对于HTML和CSS的解析各有不同的实现,我们称之为怪异模式标准模式:浏览器遵循一个标准去解析页面-HTML和CSSDE规范(W3C)
17、什么是外边距重叠?重叠的结果是什么?
外边距重叠margin-collapse:在CSS当中,相邻的两个盒子(可能是兄弟关系也可能是祖先关系)的外边距可以结合成一个单独的外边距。这种合并外边距的方式被称为折叠,并且因而所结合成的外边距称为折叠外边距- 折叠结果遵循下列计算规则:
- 两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值。
- 两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值。
- 两个外边距一正一负时,折叠结果是两者的相加的和、
18、描述一个"reset"的CSS文件并如何使用它。知道normalize.css吗?你了解他们的不同之处?
- 重置样式非常多,凡是一个前端开发人员肯定有一个常用的重置CSS文件并知道如何使用它们。他们是盲目的在做还是知道为什么这么做呢?原因是不同的浏览器对一些元素有不同的默认样式,如果你不处理,在不同的浏览器下会存在必要的风险,或者更有戏剧性的性发生。
- 你可能会用Normalize来代替你的重置样式文件。它没有重置所有的样式风格,但仅提供了一套合理的默认样式值。既能让众多浏览器达到一致和合理,但又不扰乱其他的东西(如粗体的标题)。
- 在这一方面,无法做每一个复位重置。它也确实有些超过一个重置,它处理了你永远都不用考虑的怪癖,像HTML的audio元素不一致或line-height不一致。
19、css优先级算法如何计算?
!important > id > class > 标签
!important 比 内联优先级高
*优先级就近原则,样式定义最近者为准;
*以最后载入的样式为准;
20、哪些css属性可以继承?
可继承:font-size font-family color, ul li dl dd dt;
不可继承 :border padding margin width height ;
二、JS基础
1、例举3种强制类型转换和2种隐式类型转换?
强制(parseInt(),parseFloat(),Number())
隐式(== ,!!)
2、事件绑定和普通事件有什么区别
- 普通添加事件的方法:
var btn = document.getElementById("hello"); btn.onclick = function(){ alert(1); } btn.onclick = function(){ alert(2); } // 执行上面的代码只会alert 2 - 事件绑定方式添加事件:
var btn = document.getElementById("hello"); btn.addEventListener("click",function(){ alert(1); },false); btn.addEventListener("click",function(){ alert(2); },false); // 执行上面的代码会先alert 1 再 alert 2 - 普通事件和事件绑定的区别:
普通添加事件的方法不支持添加多个事件,最下面的事件会覆盖上面的,而事件绑定(addEventListener)方式添加事件可以添加多个。
addEventListener不兼容低版本IE
普通事件无法取消
addEventLisntener还支持事件冒泡+事件捕获
3、IE和DOM事件流的区别
1.执行顺序不一样、
2.参数不一样
3.事件加不加on
4.this指向问题
4、IE和标准下有哪些兼容性的写法
Var ev = ev || window.event
document.documentElement.clientWidth || document.body.clientWidth
Var target = ev.srcElement||ev.target
5、如何阻止事件冒泡和默认事件
canceBubble()只支持IE
return false,stopPropagation()
6、javascript的本地对象,内置对象和宿主对象
- 本地对象为array obj regexp等可以new实例化
- 内置对象为gload Math 等不可以实例化的
- 宿主为浏览器自带的document,window 等
7、==和===的不同
==会自动转换类型
===不会
8、已知ID的Input输入框,希望获取这个输入框的输入值,怎么做?(不使用第三方框架)
-
document.getElementById("ID").value
9、希望获取到页面中所有的checkbox怎么做?(不使用第三方框架)
-
var domList = document.getElementsByTagName(‘input’) var checkBoxList = []; var len = domList.length; //缓存到局部变量 while (len--) { //使用while的效率会比for循环更高 if (domList[len].type == ‘checkbox’) { checkBoxList.push(domList[len]); } }
10、iframe的优缺点?
- 优点:
- 解决加载缓慢的第三方内容如图标和广告等的加载问题
- Security sandbox
- 并行加载脚本
- 缺点:
- iframe会阻塞主页面的Onload事件
- 即时内容为空,加载也需要时间
- 没有语意
11、请你谈谈Cookie的弊端?
- 缺点:
- 1.Cookie数量和长度的限制。每个domain(作用域)最多只能有20条cookie,每个cookie长度不能超过4KB,否则会被截掉。
- 2.安全性问题。如果cookie被人拦截了,那人就可以取得所有的session信息。即使加密也与事无补,因为拦截者并不需要知道cookie的意义,他只要原样转发cookie就可以达到目的了。
- 3.有些状态不可能保存在客户端。例如,为了防止重复提交表单,我们需要在服务器端保存一个计数器。如果我们把这个计数器保存在客户端,那么它起不到任何作用。
• 由于在HTTP请求中的cookie是明文传递的,潜在的安全风险,Cookie 可能会被篡改
• 有些状态不可能保存在客户端
• cookie会被附加在每个HTTP请求中,所以无形中增加了流量
• cookie一般不可跨域使用
• 没有封装好的setCookie和getCookie方法,需要开发者自省封装
12、js延迟加载的方式有哪些?
- defer /dɪ’fɝ/和async /æˈsɪŋk/
- 动态创建DOM方式(创建script,插入到DOM中,加载完毕后callBack)
- 按需异步载入js
- defer是标签的属性,只使用于外部脚本文件,在js中设置defer属性,表示脚本在执行时不会影响页面的结构,也就是说脚本会延迟到整个页面结束之后再执行,多个有defer的脚本不一定会按照顺序执行。
1、defer 和 async 都是延迟加载,都适用于外部脚本文件,都不能控制加载顺序。
2、将脚本语言放到的上面。
13、哪些操作会造成内存泄漏?
内存泄漏指任何对象在您不再拥有或需要它之后仍然存在。
垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
- setTimeout 的第一个参数使用字符串而非函数的话,会引发内存泄漏。
- 闭包
- 控制台日志
- 循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
14、事件委托是什么
让利用事件冒泡的原理,让自己的所触发的事件,让他的父元素代替执行!

知乎专栏地址:https://zhuanlan.zhihu.com/p/26536815
15、闭包是什么,有什么特性,对页面有什么影响
- 闭包就是能够读取其他函数内部变量的函数。在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁
-
function outer(){ var num = 1; function inner(){ var n = 2; alert(n + num); } return inner; } outer()();
16、解释jsonp的原理,以及为什么不是真正的ajax
- jsonp是一种跨域通信的手段,它的原理其实很简单,动态创建script标签,回调函数:
- 1、首先是利用
script标签的src属性来实现跨域。 - 2、通过将前端方法作为参数传递到服务器端,然后由服务器端注入参数之后再返回,实现服务器端向客户端通信。
- 3、由于使用script标签的src属性,因此只支持get方法
- 1、首先是利用
- jsonp为什么不是真正的ajax
- 1、
ajax和jsonp这两种技术在调用方式上"看起来"很像,目的也一样,都是请求一个url,然后把服务器返回的数据进行处理,因此jquery和ext等框架都把jsonp作为ajax的一种形式进行了封装; - 2、但ajax和jsonp其实本质上是不同的东西。ajax的核心是通过XmlHttpRequest获取非本页内容,而jsonp的核心则是动态添加
- 1、