Keras学习小结
1、概述
Keras是一个高级神经网络搭建工具,比TensorFlow更加高级,当然灵活性也就没那么高。Keras给出了各种深度学习结构的基础部件,我们只需要定义每一个部件的参数,全部连起来即可,很多细节都可以跳过,从而使得构造网络十分简单快速,不容易出错。
Keras有Functional模型和Sequential模型,前者要更加灵活,后者编译速度快,Sequential是函数模型的一种特殊情况。
http://keras-cn.readthedocs.io/en/latest/for_beginners/concepts/
2、用Keras实现BP神经网络
很简单,例子如下:
from keras.layers import Dropout, Flatten, Dense
from keras.models import Sequential#用序贯模型
model = Sequential()
# 32指的是该层有32个神经元,input_shape是输入数据的形状
#需要注意的是,样本个数是不需要写在这里的,等于tensorflow里用None来填充
model.add(Dense(32, input_shape=(16,), activation="relu"))
# 再增加一层32个神经元的层
model.add(Dense(32, activation="relu"))
# 最后一层5个神经元,并使用softmax激活函数
model.add(Dense(5, activation="softmax"))
# 显示网络结构
model.summary()
网络结构输入如下:
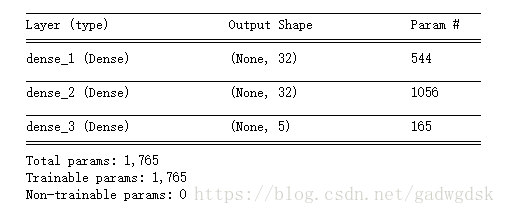
图中可以看到,每一层的OutputShape都有None,这就是batch。参数个数可以参考a=wx+b公式计算w和b的参数个数:
544 = 32*16+32
模型构造好了要编译
from keras import optimizers
model.compile(loss='categorical_crossentropy', optimizer=optimizers.Adam(lr=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0), metrics=['accuracy'])
由于输出层有多个输出,所以使用了多类别的交叉熵损失函数,优化器使用Adam,需要指定学习率,Momentum参数等,最后metrics使用准确率。
定义一下测试数据
import numpy as npn_perset = 50
x1 = np.random.rand(n_perset, 16)*0.5 + 0.1
x2 = np.random.rand(n_perset, 16)*0.5 + 0.2
x3 = np.random.rand(n_perset, 16)*0.5 + 0.3
x = np.r_[x1, x2, x3]
y = np.zeros(n_perset*3, dtype=np.int)
y[:n_perset] = np.ones(n_perset)
y[n_perset:n_perset*2] = np.ones(n_perset)*2
y = np.eye(3)[y[:]] # one hot
由于x1、x2、x3有很多交叉部分,所以准确率估计不会是100%,用来试试算法效果
然后就是训练:
from keras.callbacks import ModelCheckpoint
checkpointer = ModelCheckpoint(filepath='best.hdf5',
verbose=1, save_best_only=True)
his=model.fit(x, y,
# validation_data=(vx, vy),
epochs=20, batch_size=10, callbacks=[checkpointer], verbose=1)
这里保存最好的一个结果,就是损失最小的那一次的模型,validation_data没有设置,设置了后每一个epoch会验证一次模型准确率,当然模型训练数据的acc每一个batch都会计算

最后稳定在80%多的准确率,如果将x搞得更加有区分度,准确率可以到100%。这里有个提示,没有validation_data不会保存最优模型。好吧。。
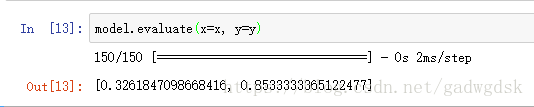
最后可以用训练好的模型来评估: