ORB-SLAM2代码(五)DBoW2词袋模型
参考:orb-slam2源码注释版、【泡泡机器人SLAM原创专栏-回环检测】DBoW2库详解、SLAM笔记(七)回环检测中的词袋BOW
orb-slam在SearchByBoW()函数中做特征匹配时,用到词袋模型BoW来加速匹配过程,不仅如此,在重定位和闭环检测中,也要使用这个BoW,所以很有必要搞明白其原理.
文章目录
- 1、视觉词袋模型
- 2、单词的权重
- 2、构造离线词典
- 2.1 存储结构
- 2.2 聚类实现
- 3、图像识别
- 3.1 查找
- 3.1 正向索引,用于加速匹配
- 3.2 逆向索引,用于回环和重定位
1、视觉词袋模型
特征点是由兴趣点和描述子表达的,把具有某一类特征的特征点放到一起就构成了一个单词(word),由所有这些单词就可以构成字典(vocabulary)了,有了字典之后,给定任意特征 f i f_i fi,只要在字典中逐层查找(使用的是汉明距离),最后就能找到与之对应的单词 w j w_j wj了.
2、单词的权重
每一类用该类中所有特征的平均特征(meanValue)作为代表,称为单词(word)。每个叶节点被赋予一个权重. 比较常用的一种权重是TF-IDF.
- 如果某个词或短语在一篇文章中出现的频率
TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类. TF-IDF实际上是TF * IDF,TF代表词频(Term Frequency),表示词条在文档d中出现的频率。IDF代表逆向文件频率(Inverse Document Frequency)。如果包含词条t的文档越少,IDF越大,表明词条t具有很好的类别区分能力.
DBoW2作者提供了TF、IDF、BINARY、TF-IDF等权重作为备选,默认为TF-IDF.
2、构造离线词典
orb-slam中的离线词典就是那个比较大的文件ORBvoc.txt,它是DBoW2作者使用orb特征,使用大量图片训练的结果.
2.1 存储结构
对每一幅训练图像,提取特征点,将所有这些特征点,通过对描述子(descriptors)聚类的方法,如,k-means++,将其分成若干类(每一类即表示一个单词),即实现聚类的过程,但是由于我们使用的描述子是256维的,那么这个类别(单词)数量不能太小(不然造成误匹配),至少是成千上万,那么这就带来一个查找效率问题,O(N)肯定是不行了,所以视觉BoW一般使用树的结构进行存储(以空间换时间呗),时间效率将达到log(N)级别.
2.2 聚类实现
由于单词过多,需要提高查找效率,简单的方法是进行二分法、N叉树等,使用k叉树,深度为d,一共可以构成 k d k^d kd个单词,聚类过程如下:
- 从训练图像中抽取特征
- 将抽取的特征用 k-means++ 算法聚类(使用汉明距离),将描述子空间划分成 k 类
- 将划分的每个子空间,继续利用 k-means++ 算法做聚类
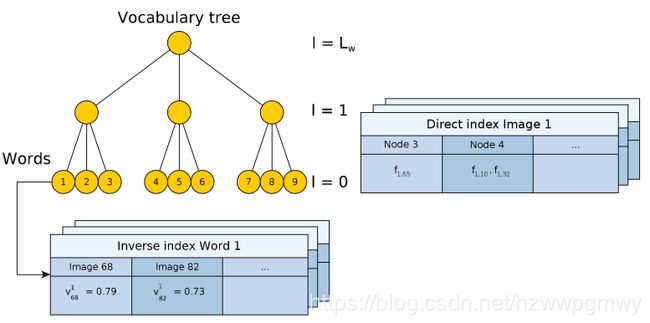
- 重复 L w L_w Lw次上述过程,将描述子建立成树形结构,如下图所示
3、图像识别
3.1 查找
离线生成视觉词典以后,在slam过程中(相对于离线,这里也叫,在线查找),对一新进来的图像帧,将其中每个特征点都从单词树根节点往下遍历,取汉明距离最小的节点接着往下遍历直到叶节点,就可以找到位于叶子节点的单词了.
为了查找方便,DBoW2使用了两种数据结构,逆向索引inverse index和正向索引direct index.
使用下面的代码,计算词包mBowVec和mFeatVec,其中mFeatVec记录了在第4层所有node节点正向索引.
void Frame::ComputeBoW()
{
if(mBowVec.empty())
{
vector<cv::Mat> vCurrentDesc = Converter::toDescriptorVector(mDescriptors);
mpORBvocabulary->transform(vCurrentDesc,mBowVec,mFeatVec,4); //第四层
}
}
3.1 正向索引,用于加速匹配
正向索引的数据结构如下,继承自std::map,NodeId为第4层上node节点的编号,其范围在 [ 0 , k l ) [0, k^l) [0,kl)内, l l l表示当前层数(这里以最上层为0层),std::vector是所有经过该node节点特征编号集合
/// Vector of nodes with indexes of local features
class FeatureVector: public std::map<NodeId, std::vector<unsigned int> >
TrackReferenceKeyFrame() 函数中的 SearchByBoW() 对pKF和F中属于同一node的特征点,进行快速匹配. 过程如下:
DBoW2::FeatureVector::const_iterator KFit = vFeatVecKF.begin();
DBoW2::FeatureVector::const_iterator Fit = F.mFeatVec.begin();
DBoW2::FeatureVector::const_iterator KFend = vFeatVecKF.end();
DBoW2::FeatureVector::const_iterator Fend = F.mFeatVec.end();
while(KFit != KFend && Fit != Fend)
{
/*【步骤1】: 分别取出属于同一node的ORB特征点(只有属于同一node,才有可能是匹配点)*/
if(KFit->first == Fit->first)
{
const vector<unsigned int> vIndicesKF = KFit->second;
const vector<unsigned int> vIndicesF = Fit->second;
/*【步骤2】: 遍历KF中属于该node的特征点*/
for(size_t iKF=0; iKF<vIndicesKF.size(); iKF++)
{
const unsigned int realIdxKF = vIndicesKF[iKF];
MapPoint* pMP = vpMapPointsKF[realIdxKF]; // 取出KF中该特征对应的MapPoint
......
这种加速特征匹配的方法在ORB-SLAM2中被大量使用。注意到,
- 正向索引的层数如果选择第
0层(根节点),那么时间复杂度和暴力搜索一样 - 如果是叶节点层,则搜索范围有可能太小,错失正确的特征点匹配
- 作者一般选择第二层或者第三层作为父节点(
L=6),正向索引的复杂度约为O(N^2/K^m)
3.2 逆向索引,用于回环和重定位
作者用反向索引记录每个叶节点对应的图像编号。当识别图像时,根据反向索引选出有着公共叶节点的备选图像并计算得分,而不需要计算与所有图像的得分。
- 为图像生成一个表征向量 v v v,图像中的每个特征都在词典中搜索其最近邻的叶节点。所有叶节点上的
TF-IDF权重集合构成了BoW向量 v v v - 根据BoW向量,计算当前图像和其它图像之间的 L 1 L_1 L1范数,有了距离定义,即可根据距离大小选取合适的备选图像
s ( v 1 , v 2 ) = 1 − 1 2 ∣ v 1 ∣ v 1 ∣ − v 2 ∣ v 2 ∣ ∣ s({{v}_{1}},\ {{v}_{2}})=1-\frac{1}{2}|\frac{{{v}_{1}}}{|{{v}_{1}}|}-\frac{{{v}_{2}}}{|{{v}_{2}}|}| s(v1, v2)=1−21∣∣v1∣v1−∣v2∣v2∣
使用词袋模型,在重定位过程中找出和当前帧具有公共单词的所有关键帧,代码如下:
// words是检测图像是否匹配的枢纽,遍历该pKF的每一个word
for(DBoW2::BowVector::const_iterator vit=F->mBowVec.begin(), vend=F->mBowVec.end(); vit != vend; vit++)
{
// 提取所有包含该word的KeyFrame
list<KeyFrame*> &lKFs = mvInvertedFile[vit->first];
for(list<KeyFrame*>::iterator lit=lKFs.begin(), lend= lKFs.end(); lit!=lend; lit++)
{
KeyFrame* pKFi=*lit;
if(pKFi->mnRelocQuery!=F->mnId)// pKFi还没有标记为pKF的候选帧
{
pKFi->mnRelocWords=0;
pKFi->mnRelocQuery=F->mnId;
lKFsSharingWords.push_back(pKFi);
}
pKFi->mnRelocWords++;
}
}
@todo
未完待续
<完>
@leatherwang