解读 Java 并发队列 BlockingQueue
最近得空,想写篇文章好好说说 java 线程池问题,我相信很多人都一知半解的,包括我自己在仔仔细细看源码之前,也有许多的不解,甚至有些地方我一直都没有理解到位。
说到线程池实现,那么就不得不涉及到各种 BlockingQueue 的实现,那么我想就 BlockingQueue 的问题和大家分享分享我了解的一些知识。
本文没有像之前分析 AQS 那样一行一行源码分析了,不过还是把其中最重要和最难理解的代码说了一遍,所以不免篇幅略长。本文涉及到比较多的 Doug Lea 对 BlockingQueue 的设计思想,希望有心的读者真的可以有一些收获,我觉得自己还是写了一些干货的。
本文直接参考 Doug Lea 写的 java doc 和注释,这也是我们在学习 java 并发包时最好的材料了。希望大家能有所思、有所悟,学习 Doug Lea 的代码风格,并将其优雅、严谨的作风应用到我们写的每一行代码中。
BlockingQueue
开篇先介绍下 BlockingQueue 这个接口的规则,后面再看其实现。
首先,最基本的来说, BlockingQueue 是一个先进先出的队列(Queue),为什么说是阻塞(Blocking)的呢?是因为 BlockingQueue 支持当获取队列元素但是队列为空时,会阻塞等待队列中有元素再返回;也支持添加元素时,如果队列已满,那么等到队列可以放入新元素时再放入。
BlockingQueue 是一个接口,继承自 Queue,所以其实现类也可以作为 Queue 的实现来使用,而 Queue 又继承自 Collection 接口。
BlockingQueue 对插入操作、移除操作、获取元素操作提供了四种不同的方法用于不同的场景中使用:1、抛出异常;2、返回特殊值(null 或 true/false,取决于具体的操作);3、阻塞等待此操作,直到这个操作成功;4、阻塞等待此操作,直到成功或者超时指定时间。总结如下:
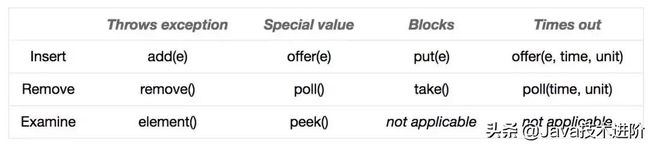
BlockingQueue 的各个实现都遵循了这些规则,当然我们也不用死记这个表格,知道有这么回事,然后写代码的时候根据自己的需要去看方法的注释来选取合适的方法即可。
对于 BlockingQueue,我们的关注点应该在 put(e) 和 take() 这两个方法,因为这两个方法是带阻塞的。
BlockingQueue 不接受 null 值的插入,相应的方法在碰到 null 的插入时会抛出 NullPointerException 异常。null 值在这里通常用于作为特殊值返回(表格中的第三列),代表 poll 失败。所以,如果允许插入 null 值的话,那获取的时候,就不能很好地用 null 来判断到底是代表失败,还是获取的值就是 null 值。
一个 BlockingQueue 可能是有界的,如果在插入的时候,发现队列满了,那么 put 操作将会阻塞。通常,在这里我们说的无界队列也不是说真正的无界,而是它的容量是 Integer.MAX_VALUE(21亿多)。
BlockingQueue 是设计用来实现生产者-消费者队列的,当然,你也可以将它当做普通的 Collection 来用,前面说了,它实现了 java.util.Collection 接口。例如,我们可以用 remove(x) 来删除任意一个元素,但是,这类操作通常并不高效,所以尽量只在少数的场合使用,比如一条消息已经入队,但是需要做取消操作的时候。
BlockingQueue 的实现都是线程安全的,但是批量的集合操作如 addAll, containsAll, retainAll 和 removeAll 不一定是原子操作。如 addAll(c) 有可能在添加了一些元素后中途抛出异常,此时 BlockingQueue 中已经添加了部分元素,这个是允许的,取决于具体的实现。
BlockingQueue 不支持 close 或 shutdown 等关闭操作,因为开发者可能希望不会有新的元素添加进去,此特性取决于具体的实现,不做强制约束。
最后,BlockingQueue 在生产者-消费者的场景中,是支持多消费者和多生产者的,说的其实就是线程安全问题。
相信上面说的每一句都很清楚了,BlockingQueue 是一个比较简单的线程安全容器,下面我会分析其具体的在 JDK 中的实现,这里又到了 Doug Lea 表演时间了。
BlockingQueue 实现之 ArrayBlockingQueue
ArrayBlockingQueue 是 BlockingQueue 接口的有界队列实现类,底层采用数组来实现。
其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。
ArrayBlockingQueue 共有以下几个属性:
// 用于存放元素的数组final Object[] items;// 下一次读取操作的位置int takeIndex;// 下一次写入操作的位置int putIndex;// 队列中的元素数量int count; // 以下几个就是控制并发用的同步器final ReentrantLock lock;private final Condition notEmpty;private final Condition notFull;
我们用个示意图来描述其同步机制:
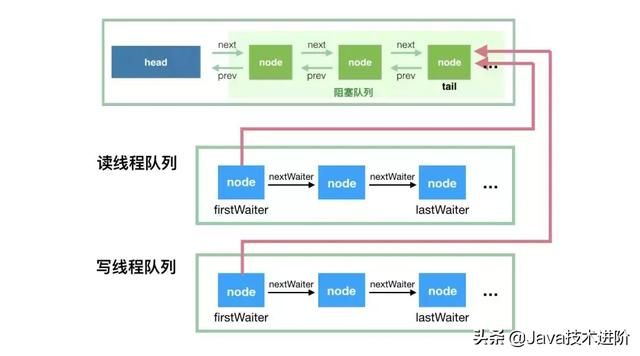
ArrayBlockingQueue 实现并发同步的原理就是,读操作和写操作都需要获取到 AQS 独占锁才能进行操作。如果队列为空,这个时候读操作的线程进入到读线程队列排队,等待写线程写入新的元素,然后唤醒读线程队列的第一个等待线程。如果队列已满,这个时候写操作的线程进入到写线程队列排队,等待读线程将队列元素移除腾出空间,然后唤醒写线程队列的第一个等待线程。
对于 ArrayBlockingQueue,我们可以在构造的时候指定以下三个参数:
- 队列容量,其限制了队列中最多允许的元素个数;
- 指定独占锁是公平锁还是非公平锁。非公平锁的吞吐量比较高,公平锁可以保证每次都是等待最久的线程获取到锁;
- 可以指定用一个集合来初始化,将此集合中的元素在构造方法期间就先添加到队列中。
BlockingQueue 实现之 LinkedBlockingQueue
底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。看构造方法:
// 传说中的无界队列public LinkedBlockingQueue() { this(Integer.MAX_VALUE);}// 传说中的有界队列public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node(null);}
我们看看这个类有哪些属性:
// 队列容量private final int capacity; // 队列中的元素数量private final AtomicInteger count = new AtomicInteger(0); // 队头private transient Nodehead; // 队尾private transient Node last; // take, poll, peek 等读操作的方法需要获取到这个锁private final ReentrantLock takeLock = new ReentrantLock(); // 如果读操作的时候队列是空的,那么等待 notEmpty 条件private final Condition notEmpty = takeLock.newCondition(); // put, offer 等写操作的方法需要获取到这个锁private final ReentrantLock putLock = new ReentrantLock(); // 如果写操作的时候队列是满的,那么等待 notFull 条件private final Condition notFull = putLock.newCondition();
这里用了两个锁,两个 Condition,简单介绍如下:
takeLock 和 notEmpty 怎么搭配:如果要获取(take)一个元素,需要获取 takeLock 锁,但是获取了锁还不够,如果队列此时为空,还需要队列不为空(notEmpty)这个条件(Condition)。
putLock 需要和 notFull 搭配:如果要插入(put)一个元素,需要获取 putLock 锁,但是获取了锁还不够,如果队列此时已满,还需要队列不是满的(notFull)这个条件(Condition)。
首先,这里用一个示意图来看看 LinkedBlockingQueue 的并发读写控制,然后再开始分析源码:
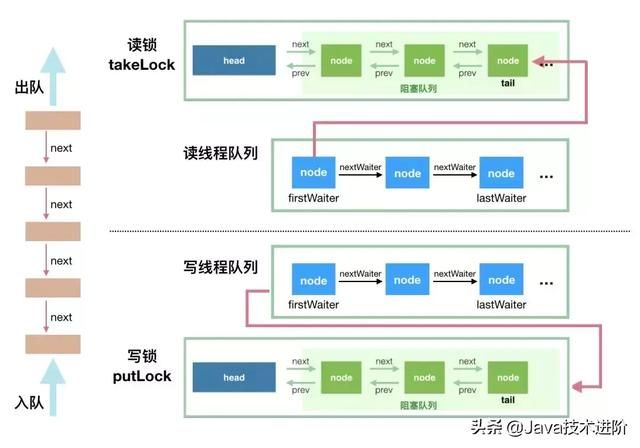
看懂这个示意图,源码也就简单了,读操作是排好队的,写操作也是排好队的,唯一的并发问题在于一个写操作和一个读操作同时进行,只要控制好这个就可以了。
先上构造方法:
public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node(null);}
注意,这里会初始化一个空的头结点,那么第一个元素入队的时候,队列中就会有两个元素。读取元素时,也总是获取头节点后面的一个节点。count 的计数值不包括这个头节点。
我们来看下 put 方法是怎么将元素插入到队尾的:
public void put(E e) throws InterruptedException { if (e == null) throw new NullPointerException(); // 如果你纠结这里为什么是 -1,可以看看 offer 方法。这就是个标识成功、失败的标志而已。 int c = -1; Nodenode = new Node(e); final ReentrantLock putLock = this.putLock; final AtomicInteger count = this.count; // 必须要获取到 putLock 才可以进行插入操作 putLock.lockInterruptibly(); try { // 如果队列满,等待 notFull 的条件满足。 while (count.get() == capacity) { notFull.await(); } // 入队 enqueue(node); // count 原子加 1,c 还是加 1 前的值 c = count.getAndIncrement(); // 如果这个元素入队后,还有至少一个槽可以使用,调用 notFull.signal() 唤醒等待线程。 // 哪些线程会等待在 notFull 这个 Condition 上呢? if (c + 1 < capacity) notFull.signal(); } finally { // 入队后,释放掉 putLock putLock.unlock(); } // 如果 c == 0,那么代表队列在这个元素入队前是空的(不包括head空节点), // 那么所有的读线程都在等待 notEmpty 这个条件,等待唤醒,这里做一次唤醒操作 if (c == 0) signalNotEmpty();} // 入队的代码非常简单,就是将 last 属性指向这个新元素,并且让原队尾的 next 指向这个元素// 这里入队没有并发问题,因为只有获取到 putLock 独占锁以后,才可以进行此操作private void enqueue(Node node) { // assert putLock.isHeldByCurrentThread(); // assert last.next == null; last = last.next = node;} // 元素入队后,如果需要,调用这个方法唤醒读线程来读private void signalNotEmpty() { final ReentrantLock takeLock = this.takeLock; takeLock.lock(); try { notEmpty.signal(); } finally { takeLock.unlock(); }}
我们再看看 take 方法:
public E take() throws InterruptedException { E x; int c = -1; final AtomicInteger count = this.count; final ReentrantLock takeLock = this.takeLock; // 首先,需要获取到 takeLock 才能进行出队操作 takeLock.lockInterruptibly(); try { // 如果队列为空,等待 notEmpty 这个条件满足再继续执行 while (count.get() == 0) { notEmpty.await(); } // 出队 x = dequeue(); // count 进行原子减 1 c = count.getAndDecrement(); // 如果这次出队后,队列中至少还有一个元素,那么调用 notEmpty.signal() 唤醒其他的读线程 if (c > 1) notEmpty.signal(); } finally { // 出队后释放掉 takeLock takeLock.unlock(); } // 如果 c == capacity,那么说明在这个 take 方法发生的时候,队列是满的 // 既然出队了一个,那么意味着队列不满了,唤醒写线程去写 if (c == capacity) signalNotFull(); return x;}// 取队头,出队private E dequeue() { // assert takeLock.isHeldByCurrentThread(); // assert head.item == null; // 之前说了,头结点是空的 Nodeh = head; Node first = h.next; h.next = h; // help GC // 设置这个为新的头结点 head = first; E x = first.item; first.item = null; return x;}// 元素出队后,如果需要,调用这个方法唤醒写线程来写private void signalNotFull() { final ReentrantLock putLock = this.putLock; putLock.lock(); try { notFull.signal(); } finally { putLock.unlock(); }}
源码分析就到这里结束了吧,毕竟还是比较简单的源码,基本上只要读者认真点都看得懂。
BlockingQueue 实现之 SynchronousQueue
它是一个特殊的队列,它的名字其实就蕴含了它的特征 – - 同步的队列。为什么说是同步的呢?这里说的并不是多线程的并发问题,而是因为当一个线程往队列中写入一个元素时,写入操作不会立即返回,需要等待另一个线程来将这个元素拿走;同理,当一个读线程做读操作的时候,同样需要一个相匹配的写线程的写操作。这里的 Synchronous 指的就是读线程和写线程需要同步,一个读线程匹配一个写线程。
我们比较少使用到 SynchronousQueue 这个类,不过它在线程池的实现类 ScheduledThreadPoolExecutor 中得到了应用,感兴趣的读者可以在看完这个后去看看相应的使用。
虽然上面我说了队列,但是 SynchronousQueue 的队列其实是虚的,其不提供任何空间(一个都没有)来存储元素。数据必须从某个写线程交给某个读线程,而不是写到某个队列中等待被消费。
你不能在 SynchronousQueue 中使用 peek 方法(在这里这个方法直接返回 null),peek 方法的语义是只读取不移除,显然,这个方法的语义是不符合 SynchronousQueue 的特征的。SynchronousQueue 也不能被迭代,因为根本就没有元素可以拿来迭代的。虽然 SynchronousQueue 间接地实现了 Collection 接口,但是如果你将其当做 Collection 来用的话,那么集合是空的。当然,这个类也是不允许传递 null 值的(并发包中的容器类好像都不支持插入 null 值,因为 null 值往往用作其他用途,比如用于方法的返回值代表操作失败)。
接下来,我们来看看具体的源码实现吧,它的源码不是很简单的那种,我们需要先搞清楚它的设计思想。
源码加注释大概有 1200 行,我们先看大框架:
// 构造时,我们可以指定公平模式还是非公平模式,区别之后再说public SynchronousQueue(boolean fair) { transferer = fair ? new TransferQueue() : new TransferStack();}abstract static class Transferer { // 从方法名上大概就知道,这个方法用于转移元素,从生产者手上转到消费者手上 // 也可以被动地,消费者调用这个方法来从生产者手上取元素 // 第一个参数 e 如果不是 null,代表场景为:将元素从生产者转移给消费者 // 如果是 null,代表消费者等待生产者提供元素,然后返回值就是相应的生产者提供的元素 // 第二个参数代表是否设置超时,如果设置超时,超时时间是第三个参数的值 // 返回值如果是 null,代表超时,或者中断。具体是哪个,可以通过检测中断状态得到。 abstract Object transfer(Object e, boolean timed, long nanos);}
Transferer 有两个内部实现类,是因为构造 SynchronousQueue 的时候,我们可以指定公平策略。公平模式意味着,所有的读写线程都遵守先来后到,FIFO 嘛,对应 TransferQueue。而非公平模式则对应 TransferStack。
我们先采用公平模式分析源码,然后再说说公平模式和非公平模式的区别。
接下来,我们看看 put 方法和 take 方法:
// 写入值public void put(E o) throws InterruptedException { if (o == null) throw new NullPointerException(); if (transferer.transfer(o, false, 0) == null) { // 1 Thread.interrupted(); throw new InterruptedException(); }}// 读取值并移除public E take() throws InterruptedException { Object e = transferer.transfer(null, false, 0); // 2 if (e != null) return (E)e; Thread.interrupted(); throw new InterruptedException();}
我们看到,写操作 put(E o) 和读操作 take() 都是调用 Transferer.transfer(…) 方法,区别在于第一个参数是否为 null 值。
我们来看看 transfer 的设计思路,其基本算法如下:
- 当调用这个方法时,如果队列是空的,或者队列中的节点和当前的线程操作类型一致(如当前操作是 put 操作,而队列中的元素也都是写线程)。这种情况下,将当前线程加入到等待队列即可。
- 如果队列中有等待节点,而且与当前操作可以匹配(如队列中都是读操作线程,当前线程是写操作线程,反之亦然)。这种情况下,匹配等待队列的队头,出队,返回相应数据。
其实这里有个隐含的条件被满足了,队列如果不为空,肯定都是同种类型的节点,要么都是读操作,要么都是写操作。这个就要看到底是读线程积压了,还是写线程积压了。
我们可以假设出一个男女配对的场景:一个男的过来,如果一个人都没有,那么他需要等待;如果发现有一堆男的在等待,那么他需要排到队列后面;如果发现是一堆女的在排队,那么他直接牵走队头的那个女的。
既然这里说到了等待队列,我们先看看其实现,也就是 QNode:
static final class QNode { volatile QNode next; // 可以看出来,等待队列是单向链表 volatile Object item; // CAS'ed to or from null volatile Thread waiter; // 将线程对象保存在这里,用于挂起和唤醒 final boolean isData; // 用于判断是写线程节点(isData == true),还是读线程节点 QNode(Object item, boolean isData) { this.item = item; this.isData = isData; } ......
相信说了这么多以后,我们再来看 transfer 方法的代码就轻松多了。
/** * Puts or takes an item. */Object transfer(Object e, boolean timed, long nanos) { QNode s = null; // constructed/reused as needed boolean isData = (e != null); for (;;) { QNode t = tail; QNode h = head; if (t == null || h == null) // saw uninitialized value continue; // spin // 队列空,或队列中节点类型和当前节点一致, // 即我们说的第一种情况,将节点入队即可。读者要想着这块 if 里面方法其实就是入队 if (h == t || t.isData == isData) { // empty or same-mode QNode tn = t.next; // t != tail 说明刚刚有节点入队,continue 即可 if (t != tail) // inconsistent read continue; // 有其他节点入队,但是 tail 还是指向原来的,此时设置 tail 即可 if (tn != null) { // lagging tail // 这个方法就是:如果 tail 此时为 t 的话,设置为 tn advanceTail(t, tn); continue; } // if (timed && nanos <= 0) // can't wait return null; if (s == null) s = new QNode(e, isData); // 将当前节点,插入到 tail 的后面 if (!t.casNext(null, s)) // failed to link in continue; // 将当前节点设置为新的 tail advanceTail(t, s); // swing tail and wait // 看到这里,请读者先往下滑到这个方法,看完了以后再回来这里,思路也就不会断了 Object x = awaitFulfill(s, e, timed, nanos); // 到这里,说明之前入队的线程被唤醒了,准备往下执行 if (x == s) { // wait was cancelled clean(t, s); return null; } if (!s.isOffList()) { // not already unlinked advanceHead(t, s); // unlink if head if (x != null) // and forget fields s.item = s; s.waiter = null; } return (x != null) ? x : e; // 这里的 else 分支就是上面说的第二种情况,有相应的读或写相匹配的情况 } else { // complementary-mode QNode m = h.next; // node to fulfill if (t != tail || m == null || h != head) continue; // inconsistent read Object x = m.item; if (isData == (x != null) || // m already fulfilled x == m || // m cancelled !m.casItem(x, e)) { // lost CAS advanceHead(h, m); // dequeue and retry continue; } advanceHead(h, m); // successfully fulfilled LockSupport.unpark(m.waiter); return (x != null) ? x : e; } }} void advanceTail(QNode t, QNode nt) { if (tail == t) UNSAFE.compareAndSwapObject(this, tailOffset, t, nt);}
// 自旋或阻塞,直到满足条件,这个方法返回Object awaitFulfill(QNode s, Object e, boolean timed, long nanos) { long lastTime = timed ? System.nanoTime() : 0; Thread w = Thread.currentThread(); // 判断需要自旋的次数, int spins = ((head.next == s) ? (timed ? maxTimedSpins : maxUntimedSpins) : 0); for (;;) { // 如果被中断了,那么取消这个节点 if (w.isInterrupted()) // 就是将当前节点 s 中的 item 属性设置为 this s.tryCancel(e); Object x = s.item; // 这里是这个方法的唯一的出口 if (x != e) return x; // 如果需要,检测是否超时 if (timed) { long now = System.nanoTime(); nanos -= now - lastTime; lastTime = now; if (nanos <= 0) { s.tryCancel(e); continue; } } if (spins > 0) --spins; // 如果自旋达到了最大的次数,那么检测 else if (s.waiter == null) s.waiter = w; // 如果自旋到了最大的次数,那么线程挂起,等待唤醒 else if (!timed) LockSupport.park(this); // spinForTimeoutThreshold 这个之前讲 AQS 的时候其实也说过,剩余时间小于这个阈值的时候,就 // 不要进行挂起了,自旋的性能会比较好 else if (nanos > spinForTimeoutThreshold) LockSupport.parkNanos(this, nanos); }}
Doug Lea 的巧妙之处在于,将各个代码凑在了一起,使得代码非常简洁,当然也同时增加了我们的阅读负担,看代码的时候,还是得仔细想想各种可能的情况。
下面,再说说前面说的公平模式和非公平模式的区别。
相信大家心里面已经有了公平模式的工作流程的概念了,我就简单说说 TransferStack 的算法,就不分析源码了。
- 当调用这个方法时,如果队列是空的,或者队列中的节点和当前的线程操作类型一致(如当前操作是 put 操作,而栈中的元素也都是写线程)。这种情况下,将当前线程加入到等待栈中,等待配对。然后返回相应的元素,或者如果被取消了的话,返回 null。
- 如果栈中有等待节点,而且与当前操作可以匹配(如栈里面都是读操作线程,当前线程是写操作线程,反之亦然)。将当前节点压入栈顶,和栈中的节点进行匹配,然后将这两个节点出栈。配对和出栈的动作其实也不是必须的,因为下面的一条会执行同样的事情。
- 如果栈顶是进行匹配而入栈的节点,帮助其进行匹配并出栈,然后再继续操作。
应该说,TransferStack 的源码要比 TransferQueue 的复杂一些,如果读者感兴趣,请自行进行源码阅读。
BlockingQueue 实现之 PriorityBlockingQueue
带排序的 BlockingQueue 实现,其并发控制采用的是 ReentrantLock,队列为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容)。
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
它的源码相对比较简单,本节将介绍其核心源码部分。
我们来看看它有哪些属性:
// 构造方法中,如果不指定大小的话,默认大小为 11private static final int DEFAULT_INITIAL_CAPACITY = 11;// 数组的最大容量private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 这个就是存放数据的数组private transient Object[] queue; // 队列当前大小private transient int size; // 大小比较器,如果按照自然序排序,那么此属性可设置为 nullprivate transient Comparator comparator; // 并发控制所用的锁,所有的 public 且涉及到线程安全的方法,都必须先获取到这个锁private final ReentrantLock lock; // 这个很好理解,其实例由上面的 lock 属性创建private final Condition notEmpty; // 这个也是用于锁,用于数组扩容的时候,需要先获取到这个锁,才能进行扩容操作// 其使用 CAS 操作private transient volatile int allocationSpinLock; // 用于序列化和反序列化的时候用,对于 PriorityBlockingQueue 我们应该比较少使用到序列化private PriorityQueue q;
此类实现了 Collection 和 Iterator 接口中的所有接口方法,对其对象进行迭代并遍历时,不能保证有序性。如果你想要实现有序遍历,建议采用 Arrays.sort(queue.toArray()) 进行处理。PriorityBlockingQueue 提供了 drainTo 方法用于将部分或全部元素有序地填充(准确说是转移,会删除原队列中的元素)到另一个集合中。还有一个需要说明的是,如果两个对象的优先级相同(compare 方法返回 0),此队列并不保证它们之间的顺序。
PriorityBlockingQueue 使用了基于数组的二叉堆来存放元素,所有的 public 方法采用同一个 lock 进行并发控制。
二叉堆:一颗完全二叉树,它非常适合用数组进行存储,对于数组中的元素 a[i],其左子节点为 a[2i+1],其右子节点为 a[2i + 2],其父节点为 a[(i-1)/2],其堆序性质为,每个节点的值都小于其左右子节点的值。二叉堆中最小的值就是根节点,但是删除根节点是比较麻烦的,因为需要调整树。
简单用个图解释一下二叉堆,我就不说太多专业的严谨的术语了,这种数据结构的优点是一目了然的,最小的元素一定是根元素,它是一棵满的树,除了最后一层,最后一层的节点从左到右紧密排列。

下面开始 PriorityBlockingQueue 的源码分析,首先我们来看看构造方法:
// 默认构造方法,采用默认值(11)来进行初始化public PriorityBlockingQueue() { this(DEFAULT_INITIAL_CAPACITY, null);}// 指定数组的初始大小public PriorityBlockingQueue(int initialCapacity) { this(initialCapacity, null);}// 指定比较器public PriorityBlockingQueue(int initialCapacity, Comparator comparator) { if (initialCapacity < 1) throw new IllegalArgumentException(); this.lock = new ReentrantLock(); this.notEmpty = lock.newCondition(); this.comparator = comparator; this.queue = new Object[initialCapacity];}// 在构造方法中就先填充指定的集合中的元素public PriorityBlockingQueue(Collection c) { this.lock = new ReentrantLock(); this.notEmpty = lock.newCondition(); // boolean heapify = true; // true if not known to be in heap order boolean screen = true; // true if must screen for nulls if (c instanceof SortedSet) { SortedSet ss = (SortedSet) c; this.comparator = (Comparator) ss.comparator(); heapify = false; } else if (c instanceof PriorityBlockingQueue) { PriorityBlockingQueue pq = (PriorityBlockingQueue) c; this.comparator = (Comparator) pq.comparator(); screen = false; if (pq.getClass() == PriorityBlockingQueue.class) // exact match heapify = false; } Object[] a = c.toArray(); int n = a.length; // If c.toArray incorrectly doesn't return Object[], copy it. if (a.getClass() != Object[].class) a = Arrays.copyOf(a, n, Object[].class); if (screen && (n == 1 || this.comparator != null)) { for (int i = 0; i < n; ++i) if (a[i] == null) throw new NullPointerException(); } this.queue = a; this.size = n; if (heapify) heapify();}
接下来,我们来看看其内部的自动扩容实现:
private void tryGrow(Object[] array, int oldCap) { // 这边做了释放锁的操作 lock.unlock(); // must release and then re-acquire main lock Object[] newArray = null; // 用 CAS 操作将 allocationSpinLock 由 0 变为 1,也算是获取锁 if (allocationSpinLock == 0 && UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset, 0, 1)) { try { // 如果节点个数小于 64,那么增加的 oldCap + 2 的容量 // 如果节点数大于等于 64,那么增加 oldCap 的一半 // 所以节点数较小时,增长得快一些 int newCap = oldCap + ((oldCap < 64) ? (oldCap + 2) : (oldCap >> 1)); // 这里有可能溢出 if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow int minCap = oldCap + 1; if (minCap < 0 || minCap > MAX_ARRAY_SIZE) throw new OutOfMemoryError(); newCap = MAX_ARRAY_SIZE; } // 如果 queue != array,那么说明有其他线程给 queue 分配了其他的空间 if (newCap > oldCap && queue == array) // 分配一个新的大数组 newArray = new Object[newCap]; } finally { // 重置,也就是释放锁 allocationSpinLock = 0; } } // 如果有其他的线程也在做扩容的操作 if (newArray == null) // back off if another thread is allocating Thread.yield(); // 重新获取锁 lock.lock(); // 将原来数组中的元素复制到新分配的大数组中 if (newArray != null && queue == array) { queue = newArray; System.arraycopy(array, 0, newArray, 0, oldCap); }}
扩容方法对并发的控制也非常的巧妙,释放了原来的独占锁 lock,这样的话,扩容操作和读操作可以同时进行,提高吞吐量。
下面,我们来分析下写操作 put 方法和读操作 take 方法。
public void put(E e) { // 直接调用 offer 方法,因为前面我们也说了,在这里,put 方法不会阻塞 offer(e); }public boolean offer(E e) { if (e == null) throw new NullPointerException(); final ReentrantLock lock = this.lock; // 首先获取到独占锁 lock.lock(); int n, cap; Object[] array; // 如果当前队列中的元素个数 >= 数组的大小,那么需要扩容了 while ((n = size) >= (cap = (array = queue).length)) tryGrow(array, cap); try { Comparator cmp = comparator; // 节点添加到二叉堆中 if (cmp == null) siftUpComparable(n, e, array); else siftUpUsingComparator(n, e, array, cmp); // 更新 size size = n + 1; // 唤醒等待的读线程 notEmpty.signal(); } finally { lock.unlock(); } return true;}
对于二叉堆而言,插入一个节点是简单的,插入的节点如果比父节点小,交换它们,然后继续和父节点比较。
// 这个方法就是将数据 x 插入到数组 array 的位置 k 处,然后再调整树private staticvoid siftUpComparable(int k, T x, Object[] array) { Comparable key = (Comparable) x; while (k > 0) { // 二叉堆中 a[k] 节点的父节点位置 int parent = (k - 1) >>> 1; Object e = array[parent]; if (key.compareTo((T) e) >= 0) break; array[k] = e; k = parent; } array[k] = key;}
我们用图来示意一下,我们接下来要将 11 插入到队列中,看看 siftUp 是怎么操作的。

我们再看看 take 方法:
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; // 独占锁 lock.lockInterruptibly(); E result; try { // dequeue 出队 while ( (result = dequeue()) == null) notEmpty.await(); } finally { lock.unlock(); } return result;}
private E dequeue() { int n = size - 1; if (n < 0) return null; else { Object[] array = queue; // 队头,用于返回 E result = (E) array[0]; // 队尾元素先取出 E x = (E) array[n]; // 队尾置空 array[n] = null; Comparator cmp = comparator; if (cmp == null) siftDownComparable(0, x, array, n); else siftDownUsingComparator(0, x, array, n, cmp); size = n; return result; }}
dequeue 方法返回队头,并调整二叉堆的树,调用这个方法必须先获取独占锁。
废话不多说,出队是非常简单的,因为队头就是最小的元素,对应的是数组的第一个元素。难点是队头出队后,需要调整树。
private staticvoid siftDownComparable(int k, T x, Object[] array, int n) { if (n > 0) { Comparable key = (Comparable)x; // 这里得到的 half 肯定是非叶节点 // a[n] 是最后一个元素,其父节点是 a[(n-1)/2]。所以 n >>> 1 代表的节点肯定不是叶子节点 // 下面,我们结合图来一行行分析,这样比较直观简单 // 此时 k 为 0, x 为 17,n 为 9 int half = n >>> 1; // 得到 half = 4 while (k < half) { // 先取左子节点 int child = (k << 1) + 1; // 得到 child = 1 Object c = array[child]; // c = 12 int right = child + 1; // right = 2 // 如果右子节点存在,而且比左子节点小 // 此时 array[right] = 20,所以条件不满足 if (right < n && ((Comparable) c).compareTo((T) array[right]) > 0) c = array[child = right]; // key = 17, c = 12,所以条件不满足 if (key.compareTo((T) c) <= 0) break; // 把 12 填充到根节点 array[k] = c; // k 赋值后为 1 k = child; // 一轮过后,我们发现,12 左边的子树和刚刚的差不多,都是缺少根节点,接下来处理就简单了 } array[k] = key; }}
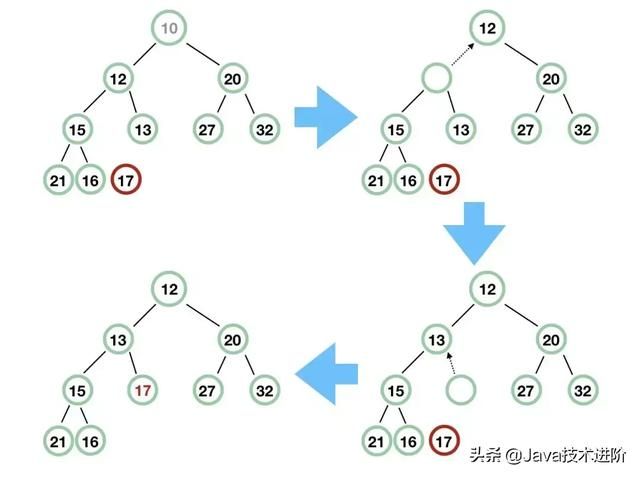
记住二叉堆是一棵完全二叉树,那么根节点 10 拿掉后,最后面的元素 17 必须找到合适的地方放置。首先,17 和 10 不能直接交换,那么先将根节点 10 的左右子节点中较小的节点往上滑,即 12 往上滑,然后原来 12 留下了一个空节点,然后再把这个空节点的较小的子节点往上滑,即 13 往上滑,最后,留出了位子,17 补上即可。
我稍微调整下这个树,以便读者能更明白:
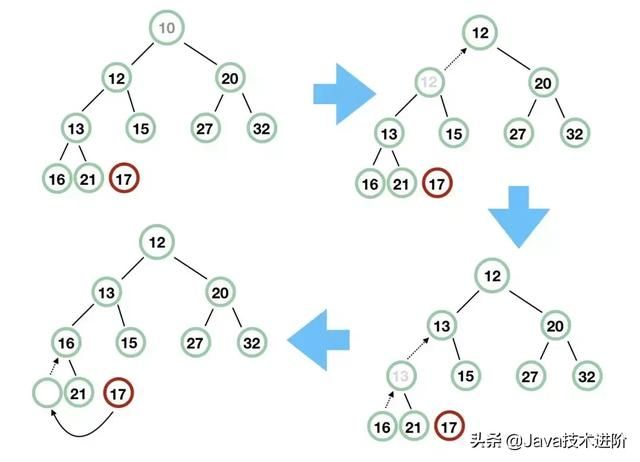
好了, PriorityBlockingQueue 我们也说完了。
总结
我知道本文过长,相信一字不漏看完的读者肯定是少数。
ArrayBlockingQueue 底层是数组,有界队列,如果我们要使用生产者-消费者模式,这是非常好的选择。
LinkedBlockingQueue 底层是链表,可以当做无界和有界队列来使用,所以大家不要以为它就是无界队列。
SynchronousQueue 本身不带有空间来存储任何元素,使用上可以选择公平模式和非公平模式。
PriorityBlockingQueue 是无界队列,基于数组,数据结构为二叉堆,数组第一个也是树的根节点总是最小值。
”我自己是一名从事了十余年的后端的老程序员,辞职后目前在做讲师,近期我花了一个月整理了一份最适合2018年学习的JAVA干货(里面有高可用、高并发、高性能及分布式、Jvm性能调优、Spring源码,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多个知识点的架构资料)从事后端的小伙伴们都可以来了解一下的,这里是程序员秘密聚集地,各位还在架构师的道路上挣扎的小伙伴们速来。“
加QQ群:611481448(名额有限哦!)