决策树——CART——之R语言rpart包
R是一种用于统计计算与作图的开源软件,同时也是一种编程语言,它广泛应用于企业和学术界的数据分析领域,正在成为最通用的语言之一。由于近几年数据挖掘、大数据等概念的走红,R也越来越多的被人关注。
一、环境准备
操作系统windows
下载安装R 地址:http://mirrors.xmu.edu.cn/CRAN/
下载安装RStudio(一个非常实用的R语言的IDE,是一个免费的软件)
地址:http://www.rstudio.com/products/RStudio/#Desk
二、下载安装rpart包

点击InstallPackages
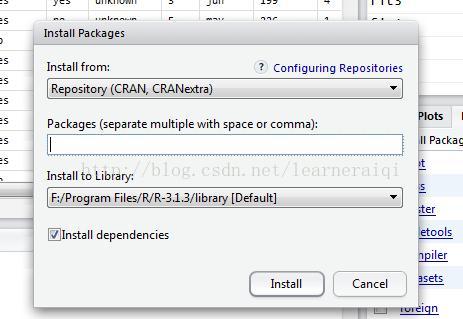
在packages中输入:rpart->Install
等待安装完成。
注:Installfrom中可以选择安装方式,图中显示的是从CRAN中通过网络连接下载,也可以选择在本地文件中寻找package安装。
三、下载数据
我试验的数据是从UCI上下载的数据,当然也可以用rpart包中自带的数据集。
UCI下载数据地址:http://archive.ics.uci.edu/ml/datasets/Bank+Marketing
将数据解压后,会有许多.csv格式的数据文件,在这里本次试验选择的是bank.csv
四、使用R读取数据
打开RStudio
在控制台
或者新建一个R Script
接下来我们在R Script中书写代码,同样,也可以在控制台上一行一行的书写,一条一条的执行,但是,代码换行时要按shift+Enter
bank <- read.csv("D:/data/MachineLearning/bank/bank.csv",header=TRUE,sep=";") #读取bank.csv数据文件
#注意:windows文件路径复制后文件的分隔符为“\”,但是R语言中不识别这种分隔符,她只识别“/”,
#header=TRUE表示使用文件的头标签,默认为FALSE,sep=";"表示数据用分号分隔,默认为"",
bank_train <- bank[1:4000,] #对读入的数据人为分割为训练组和测试组,
bank_test <- bank[4001:4521,1:16]
bank_test1 <- bank[4001:4521,]
library(rpart) #在使用包前首先要使用该命令导入包,也可以在Packages中包前的框框中打钩
fit <- rpart(y~age+job+marital+education+default+balance+housing+loan+contact
+day+month+duration+campaign+pdays+previous+poutcome,method="class",
data=bank_train)
# 我们可以使用help(rpart)来获取rpart的使用帮助,帮助文档Usage如下
# rpart(formula, data, weights, subset, na.action = na.rpart, method,
# model = FALSE, x = FALSE, y = TRUE, parms, control, cost, ...)
# 在这里我们只设置formula,data,model这三个参数
plot(fit,uniform=TRUE,main="Classification Tree for Bank") #画决策树图
text(fit,use.n=TRUE,all=TRUE)
#至此,第一个决策树图画好了,第一个训练的模型保存在fit中
#下面我们对测试数据进行预测(此处预测的是y值是yes or no)
result <- predict(fit,bank_test,type="class")
# 在控制台中直接输入result即可查看预测的结果,由于数目较多,我们写一个小的程序,将预测
# 结果同真实值比较一下,看正确率有多少
# 详情见 count_result.R
# 我们写完的函数保存在本地磁盘中,使用时必须指明路径,使用source()函数
source("D:/work/R_work/count_result.R")
count_result(result,bank_test1) #结果为0.9021
#通过观察数据,我们可以发现,在poutcome与contact属性中,有许多unknown的值,
#通过summary(bank)我们可以看到,unknown值在其所在属性框中所占比例过大,而且该
#值其实为缺失值,所以我们使用rpart()函数中的na.action参数,来处理缺失值
#由于R只识别NA缺失值,所以我们需要对数据框中的unknown值进行处理
n <- nrow(bank) #获得data的行数
for (i in 1:n){
if(bank[i,9]=="unknown"){ #判断第i,9个数据是否为unknown
bank[i,9] <- NA #将第i,9个数据替换为NA
}
if(bank[i,16]=="unknown"){
bank[i,16] <- NA
}
}
#我们已知第9、16列为含有unknown的属性框
fit2 <- rpart(y~age+job+marital+education+default+balance+housing+loan+contact
+ +day+month+duration+campaign+pdays+previous+poutcome,method="class",
+ data=bank_train,na.action=na.rpart)
plot(fit,uniform=TRUE,main="Classification Tree for Bank") #画决策树图
text(fit,use.n=TRUE,all=TRUE)
result2 <- predict(fit2,bank_test,type="class")
count_result(result2)# 结果仍为0.9021表示之前的关于缺失值的推测不准确
#下边我们探索使用rpart()的control参数设置
fit3 <- rpart(y~age+job+marital+education+default+balance+housing+loan+contact
+ +day+month+duration+campaign+pdays+previous+poutcome,method="class",
+ data=bank_train,na.action=na.rpart,control=rpart.control(minsplit=20,cp=0.001))
result3 <- predict(fit3,bank_test,type="class")
count_result(result3,bank_test1)# 结果为0.90403 预测的准确度有所上升
#下边我们队minsplit(最小分割点)设大一点 40
fit4 <- rpart(y~age+job+marital+education+default+balance+housing+loan+contact
+ +day+month+duration+campaign+pdays+previous+poutcome,method="class",
+ data=bank_train,na.action=na.rpart,control=rpart.control(minsplit=40,cp=0.001))
result4 <- predict(fit4,bank_test,type="class")
count_result(result4,bank_test1) #结果为0.9136 这说明随着分割点的增多,预测的准确率越高,关于rpart的其他函数的功能探索,请继续关注...
count_result.R
count_result <- function(result,data_test){
n <- length(result)
count_right <- 0
i <- 1
for (i in 1:n){
if (result[i]==data_test[i,17]){
count_right = count_right+1
}
}
print(count_right/n)
}