Kaggle实战——泰坦尼克生存预测大赛
In [6]:
import csv
import numpy as np
csv_file_object = csv.reader(open('D:/In/kaggle/Titanic/train.csv', 'rt'))
data=[]
for row in csv_file_object:
data.append(row)
#data = np.array(data)
print (data[0])
print (np.array(data)[0])
In [ ]:
'''
#数据处理
import numpy as np
import pandas as pd
#绘图
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
#各种模型、数据处理方法
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from sklearn.metrics import precision_score
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
import warnings
warnings.filterwarnings('ignore')
'''
In [2]:
print (data[:3]) #list是一维的,array是二维的
print (np.array(data)[:3])
print (np.array(data)[:15,5])
#print (data[0:15,5])
data=np.array(data)
type(data) #data此时为一个二维的数组
Out[2]:
In [3]:
print(data[1:6,5])
print(data[1:6,5].astype(int))
print(data[1:6,5].astype(int).mean())
In [1]:
import pandas as pd
%matplotlib inline
df=pd.read_csv('D:/In/kaggle/Titanic/train.csv')
df_test=pd.read_csv('D:/In/kaggle/Titanic/test.csv')
print(df.info())
print(df[['Age','Sex','Pclass']][:10])
print(df[df['Age']>60][['Survived','Pclass','Sex','Age']])
df[df['Age'].isnull()][:10] #只显示年龄为空的数据
Out[1]:
In [2]:
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(context="paper", font="monospace")
sns.set(style="white")
f, ax = plt.subplots(figsize=(10,6))
train_corr = df.drop('PassengerId',axis=1).corr()
sns.heatmap(train_corr, ax=ax, vmax=.9, square=True)
ax.set_xticklabels(train_corr.index, size=15)
ax.set_yticklabels(train_corr.columns[::1], size=15)
ax.set_title('train feature corr', fontsize=20)
Out[2]:

In [5]:
for i in range(1,4):
print (i, len (df[ (df['Sex']=='male')&(df['Pclass'] == i) ]) ) #输出不同等级仓中男士的数量
In [6]:
import pylab as p
df['Age'].dropna().hist(range=(0,100),bins=19,alpha=0.8),p.show() #bins代表直方柱的个数 alpha控制颜色深浅

Out[6]:
In [7]:
from scipy import stats
fig,axes=plt.subplots(2,1,figsize=(8,6))
sns.set_style('darkgrid')#设置风格主题
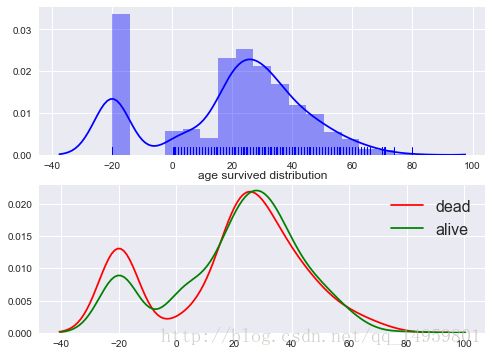
sns.distplot(df.Age.fillna(-20),rug=True,color='b',ax=axes[0])#rug强度(齿)
ax0=axes[0]
ax0.set_xlabel('')
ax1=axes[1]
ax1.set_title('age survived distribution')
k1=sns.distplot(df[df.Survived==0].Age.fillna(-20),hist=False,color='r',ax=ax1,label='dead')#罹难的年龄分布
k2=sns.distplot(df[df.Survived==1].Age.fillna(-20),hist=False,color='g',ax=ax1,label='alive')#存活的年龄分布
ax1.set_xlabel('')#x坐标轴名字
ax1.legend(fontsize=16)#小朋友和中青年比较容易存活
Out[7]:
In [8]:
f,ax=plt.subplots(figsize=(8,3))
ax.set_title('Sex Age dist',size=20)
sns.distplot(df[df.Sex=='female'].dropna().Age,hist=False,color='pink',label='female')
sns.distplot(df[df.Sex=='male'].dropna().Age,hist=False,color='blue',label='male')
ax.legend(fontsize=15)#训练集中的男女年龄分布 男性中老年较多 女性较年轻
Out[8]:

In [16]:
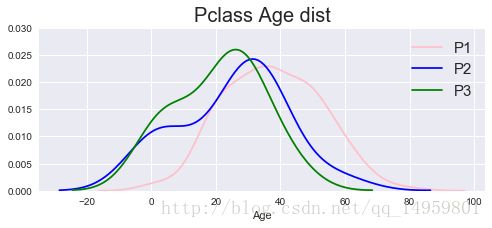
f,ax=plt.subplots(figsize=(8,3))
plt.ylim(0.0,0.03)
ax.set_title('Pclass Age dist',size=20)
sns.distplot(df[df.Pclass==1].dropna().Age,hist=False,color='pink',label='P1')
sns.distplot(df[df.Pclass==2].dropna().Age,hist=False,color='blue',label='P2')
sns.distplot(df[df.Pclass==3].dropna().Age,hist=False,color='green',label='P3')
ax.legend(fontsize=15)#不同仓级年龄分布
Out[16]:
In [35]:
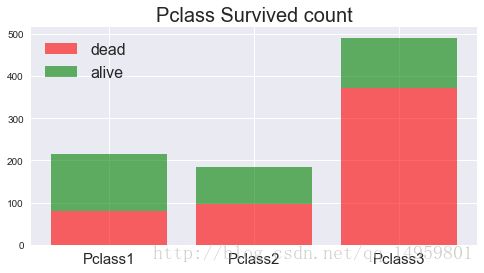
y_dead=df[df.Survived==0].groupby('Pclass')['Survived'].count()
y_alive=df[df.Survived==1].groupby('Pclass')['Survived'].count()
pos=[1,2,3]#横轴id
ax=plt.figure(figsize=(8,4)).add_subplot(111)
ax.bar(pos,y_dead,color='r',alpha=0.6,label='dead')
ax.bar(pos,y_alive,color='g',bottom=y_dead,alpha=0.6,label='alive')
ax.legend(fontsize=16,loc='best')
ax.set_xticks(pos)
ax.set_xticklabels(['Pclass%d'%(i) for i in range(1,4)],size=15)#x坐标轴信息
ax.set_title('Pclass Survived count',size=20)#不同仓级存活情况
Out[35]:
In [29]:
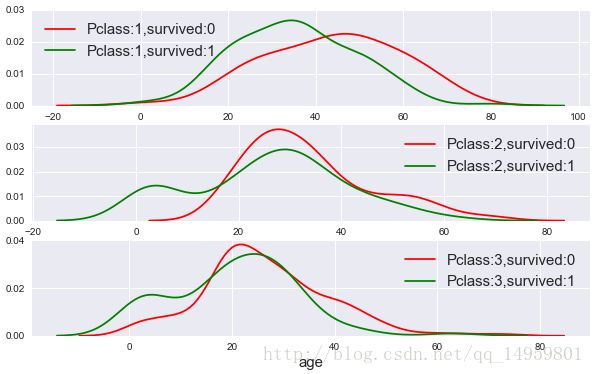
pos=range(0,6)
age_list=[]
for Pclass_ in range(1,4):
for Survived_ in range(0,2):
age_list.append(df[(df.Pclass==Pclass_)&(df.Survived==Survived_)].Age.values)
#三个仓级的存亡年龄
fig,axes=plt.subplots(3,1,figsize=(10,6))
sns.set_style('darkgrid')#设置风格主题
#plt.ylim(0.0,0.06)
#print(axes)
print(len(age_list))
i_Pclass=1
for ax in axes:
if i_Pclass==1:
ax.set_ylim(0.0, 0.03)#设置y轴范围
sns.distplot(age_list[i_Pclass*2-2],hist=False,ax=ax,label='Pclass:%d,survived:0'%(i_Pclass),color='r')
sns.distplot(age_list[i_Pclass*2-1],hist=False,ax=ax,label='Pclass:%d,survived:1'%(i_Pclass),color='g')
i_Pclass+=1
ax.set_xlabel('age',size=15)
ax.legend(fontsize=15)
In [33]:
#性别
print(df.Sex.value_counts())
print('******************************')
print(df.groupby('Sex')['Survived'].mean())#男女存活率
In [36]:
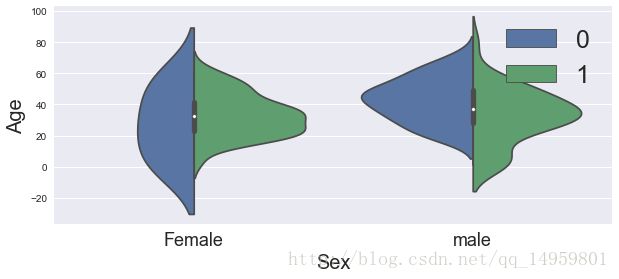
ax=plt.figure(figsize=(10,4)).add_subplot(111)
sns.violinplot(x='Sex',y='Age',hue='Survived',data=df.dropna(),split=True)#小提琴图
ax.set_xlabel('Sex',size=20)
ax.set_xticklabels(['Female','male'],size=18)
ax.set_ylabel('Age',size=20)
ax.legend(fontsize=25,loc='best')#男女存亡年龄分布
Out[36]:
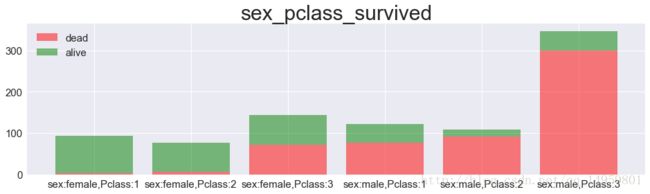
In [42]:
label=[]
for sex_i in ['female','male']:
for pclass_i in range(1,4):
label.append('sex:%s,Pclass:%d'%(sex_i,pclass_i))
pos=range(6)
fig=plt.figure(figsize=(16,4))
ax=fig.add_subplot(111)
ax.bar(pos,df[df['Survived']==0].groupby(['Sex','Pclass'])['Survived'].count().values,
color='r',
alpha=0.5,
align='center',
tick_label=label,
label='dead')
ax.bar(pos,
df[df['Survived']==1].groupby(['Sex','Pclass'])['Survived'].count().values,
bottom=df[df['Survived']==0].groupby(['Sex','Pclass'])['Survived'].count().values,
color='g',
alpha=0.5,
align='center',
tick_label=label,
label='alive')
ax.tick_params(labelsize=15)
ax.set_title('sex_pclass_survived',size=30)
ax.legend(fontsize=15,loc='best')#相同性别情况下,仓级越高越容易存活
Out[42]:
In [69]:
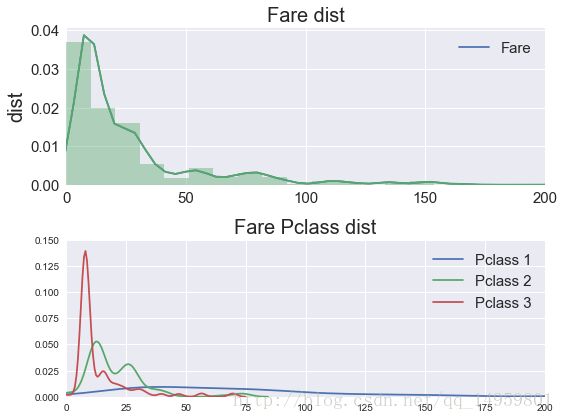
#Fare费用
fig=plt.figure(figsize=(8,6))
ax=plt.subplot2grid((2,2),(0,0),colspan=2)#角标
#fig,ax=plt.subplots(1,1,figsize=(8,6))
ax.tick_params(labelsize=15)
ax.set_title('Fare dist',size=20)
ax.set_ylabel('dist',size=20)
sns.kdeplot(df.Fare,ax=ax)
sns.distplot(df.Fare,hist=True,ax=ax)
ax.legend(fontsize=15)
pos=range(0,400,50)
ax.set_xticks(pos)
ax.set_xlim([0,200])
ax.set_xlabel('')
#fig,ax1=plt.subplots(1,1,figsize=(8,6))
ax1=plt.subplot2grid((2,2),(1,0),colspan=2)
ax1.set_title('Fare Pclass dist',size=20)
for i in range(1,4):
sns.kdeplot(df[df.Pclass==i].Fare,ax=ax1,label='Pclass %d'%(i))#不同仓级的票价分布
ax1.set_xlim([0,200])
ax1.set_ylim([0,0.15])
ax1.legend(fontsize=15)#船票价分布
plt.tight_layout()#间距松紧
In [70]:
fig=plt.figure(figsize=(8,3))
ax1=fig.add_subplot(111)
sns.kdeplot(df[df.Survived==0].Fare,ax=ax1,label='dead',color='r')
sns.kdeplot(df[df.Survived==1].Fare,ax=ax1,label='alive',color='g')
#sns.distplot(df[df.Survived==0].Fare,ax=ax1,color='r')
#sns.distplot(df[df.Survived==1].Fare,ax=ax1,color='g')
ax1.set_xlim([0,300])
ax1.legend(fontsize=15)
ax1.set_title('Fare survived',size=20)
ax1.set_xlabel('Fare',size=15)#存亡票价分布
Out[70]:

In [73]:
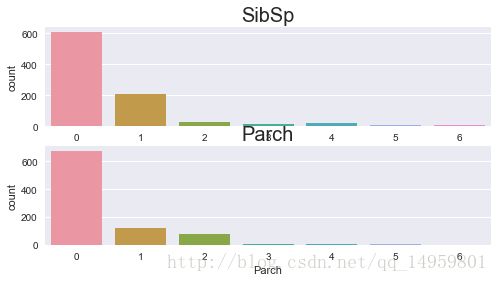
fig=plt.figure(figsize=(8,4))
ax1=fig.add_subplot(211)
sns.countplot(df.SibSp)#计数
ax1.set_title('SibSp',size=20)
ax2=fig.add_subplot(212,sharex=ax1)
sns.countplot(df.Parch)
ax2.set_title('Parch',size=20)#表亲和直亲
#plt.tight_layout()
Out[73]:
In [76]:
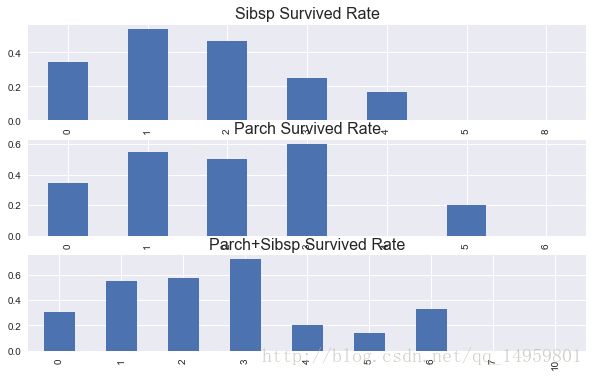
fig=plt.figure(figsize=(10,6))
ax1=fig.add_subplot(311)
df.groupby('SibSp')['Survived'].mean().plot(kind='bar',ax=ax1)#存活率
ax1.set_title('Sibsp Survived Rate',size=16)
ax1.set_xlabel('')
ax2=fig.add_subplot(312)
df.groupby('Parch')['Survived'].mean().plot(kind='bar',ax=ax2)
ax2.set_title('Parch Survived Rate',size=16)
ax2.set_xlabel('')
ax3=fig.add_subplot(313)
df.groupby(df.SibSp+df.Parch)['Survived'].mean().plot(kind='bar',ax=ax3)
ax3.set_title('Parch+Sibsp Survived Rate',size=16)
#plt.tight_layout()
Out[76]:
In [85]:
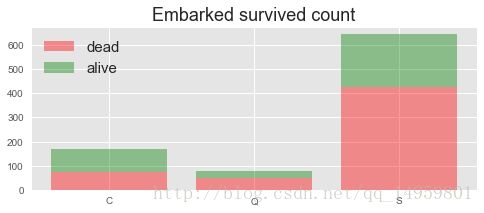
#上船地点
plt.style.use('ggplot')#美化
ax=plt.figure(figsize=(8,3)).add_subplot(111)
pos=[1,2,3]
y1=df[df.Survived==0].groupby('Embarked')['Survived'].count().sort_index().values#确保存亡的一一对应
print(y1)
y2=df[df.Survived==1].groupby('Embarked')['Survived'].count().sort_index().values
ax.bar(pos,y1,color='r',alpha=0.4,align='center',label='dead')
ax.bar(pos,y2,color='g',alpha=0.4,align='center',label='alive',bottom=y1)
ax.set_xticks(pos)
ax.set_xticklabels(['C','Q','S'])
ax.legend(fontsize=15,loc='best')
ax.set_title('Embarked survived count',size=18)
Out[85]:
In [94]:
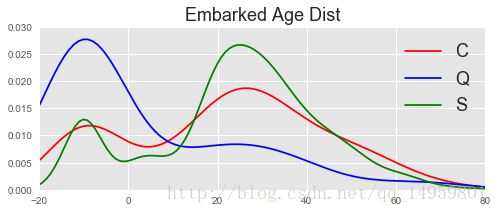
#C地存活概率较高
#不同的上船地点
ax=plt.figure(figsize=(8,3)).add_subplot(111)
ax.set_xlim([-20,80])
ax.set_ylim([0.0,0.03])
sns.kdeplot(df[df.Embarked=='C'].Age.fillna(-10),ax=ax,label='C',color='r')
sns.kdeplot(df[df.Embarked=='Q'].Age.fillna(-10),ax=ax,label='Q',color='b')
sns.kdeplot(df[df.Embarked=='S'].Age.fillna(-10),ax=ax,label='S',color='g')
ax.legend(fontsize=18)
ax.set_title('Embarked Age Dist',size=18)
#plt.tight_layout()
#Q上岸的年龄缺失比较多
#C和S上岸的年龄分布较相似,但是C的分布更扁平小孩和老人的占比更高
Out[94]:
In [103]:
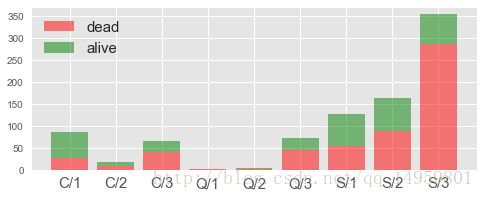
#不同仓位不同地点
y1=df[df.Survived==0].groupby(['Embarked','Pclass'])['Survived'].count().reset_index()['Survived'].values
print(y1)
y2=df[df.Survived==1].groupby(['Embarked','Pclass'])['Survived'].count().reset_index()['Survived'].values
ax=plt.figure(figsize=(8,3)).add_subplot(111)
pos=range(9)
ax.bar(pos,y1,align='center',alpha=0.5,color='r',label='dead')
ax.bar(pos,y2,align='center',bottom=y1,alpha=0.5,color='g',label='alive')
ax.set_xticks(pos)
xticklabels=[]
for embarked_val in ['C','Q','S']:
for pclass_val in range(1,4):
xticklabels.append('%s/%d'%(embarked_val,pclass_val))
ax.set_xticklabels(xticklabels,size=15)
ax.legend(fontsize=15,loc='best')#C地的存活率似乎更高
Out[103]:
In [123]:
#Cabin船舱号
print(df['Cabin'].isnull().value_counts())
df.groupby(df['Cabin'].isnull())['Survived'].mean()
#船舱号为空的存活率低,可以作为一个特征
Out[123]:
In [148]:
print(df[df['PassengerId']==28]['Cabin'])
print(len(df.loc[27,'Cabin']))
df[df.Cabin.apply(lambda x:len(x) if (x is not np.nan) else 0)>4].head(10)#返回Cabin大于4个字符的(有多个船舱的)
Out[148]:
In [149]:
#不同船舱的存亡统计
df['Cabin_Zone']=df.Cabin.fillna('0').str.split(' ').apply(lambda x: x[0][0])
df.groupby(by='Cabin_Zone')['Survived'].agg(['mean','count'])
#不同船舱的存亡率不一样
Out[149]:
In [155]:
#船票Ticket
print(df.Ticket.head())
print(len(df.Ticket.unique()))#船票有重复的
df[df.Ticket=='110152']
Out[155]:
In [165]:
#船票有重复的
print(df[df.Cabin=='B77'])
#有些船票有英文,有些则没有,使用正则!!!!!!
import re
def find_e_word(x):
pattern=re.compile('[a-z]|[A-Z]')
try:
re.search(pattern,x).group()
return 1
except:
return 0
df['Ticket_e']=df.Ticket.apply(lambda x: find_e_word(x))
df.groupby('Ticket_e')['Survived'].mean()
#存活率没区别
Out[165]:
In [174]:
#名字Name
print(df.Name.apply(lambda x: x.split(',')[1].split('.')[0]).value_counts())
df.Name.apply(lambda x: x.split(',')[1].split('.')[1]).value_counts()[:8]
Out[174]:
In [ ]:
#--------------------------------
In [183]:
df.head()
Out[183]:
In [177]:
#查看数据缺失情况
print(df.isnull().sum())
df_test.isnull().sum()
Out[177]:
In [179]:
df[df['Embarked'].isnull()]
Out[179]:
In [181]:
print(df['Embarked'].value_counts())
print(df[df['Pclass']==1].Embarked.value_counts())
df.Embarked.fillna('S',inplace=True)
#上船地点填充
Out[181]:
In [234]:
#Cabin缺失值的处理,方法一
df['Cabin_e']=df['Cabin'].isnull().map({True:0,False:1})
df_test['Cabin_e']=df_test['Cabin'].isnull().map({True:0,False:1})
#df=df.drop(['Cabin_e'],axis=1)
#df['Cabin_e']=df['Cabin'].isnull().map(lambda x:0 if x is True else 1)方法二!!!!!!
#df_test['Cabin_e']
#df.head()
#df=df.drop(['Cabin_e'],axis=1)
"""方法三
import re
def Cabin_isnull(x):
pattern=re.compile("\d$")
try:
re.search(pattern,x).group()
return 1
except:
return 0
df['Cabin_e']=df['Cabin'].apply(lambda x: Cabin_isnull(x))
df.head()
"""
df_test.head()
Out[234]:
In [8]:
df['Gender']=5
df['Gender']=df['Sex'].map(lambda x:x[0].upper())
print(df.head())
df['Gender']=df['Sex'].map({'male':1,'female':0}) #并行化执行
df.head()
Out[8]:
In [236]:
#Age年龄离散化,以5岁为一个周期
def age_map(x):
if x<10:
return '10-'
if x<60:
return '%d-%d'%(x//5*5,x//5*5+5)
elif x>=60:
return '60+'
else:
return 'Null'
df['Age_map']=df['Age'].apply(lambda x: age_map(x))
df_test['Age_map']=df_test['Age'].apply(lambda x:age_map(x))
df.groupby('Age_map')['Survived'].agg(['count','mean'])#不同年龄层的存亡情况
Out[236]:
In [247]:
#test中的Fare缺失
print(df_test[df_test['Fare'].isnull()])
df_test.loc[df_test.Fare.isnull(),'Fare']=df_test[(df_test['Pclass']==3)&(df_test['Embarked']=='S')&(df_test['Sex']=='male')].dropna().Fare.mean()
df_test[df_test['PassengerId']==1044]
Out[247]:
In [266]:
#数据归一化以加速模型收敛,Fare分布太宽
import sklearn.preprocessing as preprocessing
scaler=preprocessing.StandardScaler()
fare_scale_param=scaler.fit(df['Fare'].values.reshape(-1,1))
df['Fare_e']=fare_scale_param.transform(df['Fare'].values.reshape(-1,1))
df_test['Fare_e']=fare_scale_param.transform(df_test['Fare'].values.reshape(-1,1))
print(df.head())
df_test.head()
Out[266]:
In [267]:
#部分变量哑编码,onehot独热码
df_x = pd.concat([df[['SibSp','Parch','Fare']], pd.get_dummies(df[['Pclass','Sex','Cabin','Embarked','Age_map']])],axis=1)#按照列黏连
df_y = df.Survived
df_test_x = pd.concat([df_test[['SibSp','Parch','Fare']], pd.get_dummies(df_test[['Pclass', 'Sex','Cabin','Embarked', 'Age_map']])],axis=1)
print(df_x.head())
df_test_x.head()
Out[267]:
In [ ]:
#缺失年龄填补
In [9]:
M=np.random.randn(2,3) #i代表性别 j代表仓等级
for i in range(2):
for j in range(3):
M[i][j]=df[(df['Pclass']==j+1) & (df['Gender']==i)]['Age'].median() #取中位数
M
Out[9]:
In [10]:
df['AgeFill']=df['Age']
print(len(df[df['Age'].isnull()][['Gender','Pclass','Age','AgeFill']]))
print(df[df['Age'].isnull()][['Gender','Pclass','Age','AgeFill']].head())
for i in range(2):
for j in range(3):
df.loc[df[(df['Pclass']==j+1) & (df['Gender']==i) & (df['Age'].isnull())].index,['AgeFill']]=M[i][j] #.index取索引值
df[df['Age'].isnull()][['Gender','Pclass','Age','AgeFill']].head()
Out[10]:
In [11]:
#--------------特征工程
df['familysize']=df['SibSp']+df['Parch']
df['Pclass*AgeFill']=df['Pclass']*df['AgeFill']
In [12]:
for i in df.dtypes:
print (i)
In [13]:
#df=df.drop(['Pclass*Age'],axis=1) 丢弃一列
print(df.dtypes)
df.dtypes[df.dtypes.map(lambda x: x=='object')]
Out[13]:
In [14]:
df=df.drop(['Name','Sex','Age','Ticket','Cabin','Embarked'],axis=1)
df.head()
Out[14]:
In [15]:
from sklearn.cross_validation import train_test_split
from sklearn.linear_model.logistic import LogisticRegression
from sklearn import preprocessing
import seaborn as sns
feature_names=['Pclass','SibSp','Parch','Fare','Gender','AgeFill','familysize','Pclass*AgeFill']
X=df[feature_names]
Y=df['Survived']
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=0) #7:3拆分
lr_model=LogisticRegression()
lr_model.fit(X_train,y_train)
y_pred_score=lr_model.predict_proba(X_test)
y_pred_score[:10]
Out[15]:
In [16]:
#from sklearn.metrics import roc_curve
import sklearn
import matplotlib.pyplot as plt
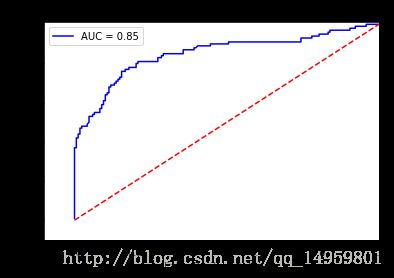
fpr,tpr,thresholds=sklearn.metrics.roc_curve(y_test,y_pred_score[:,1])#注意阈值
roc_auc=sklearn.metrics.auc(fpr,tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr,tpr,'b',label='AUC = %0.2f'%roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.0])
plt.ylim([-0.1,1.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
In [17]:
df=df.dropna() #有空值存在的所有行
train_data=df.values
train_data
Out[17]:
In [18]:
#使用网格搜索最佳模型参数!!!!!! X_train,X_test,y_train,y_test
from sklearn.model_selection import GridSearchCV
base_line_model = LogisticRegression()
param = {'penalty':['l1','l2'],
'C':[0.1, 0.5, 1.0,5.0]}
grd = GridSearchCV(estimator=base_line_model, param_grid=param, cv=5, n_jobs=3)
grd.fit(X_train,y_train)
grd.best_estimator_
Out[18]:
In [27]:
from sklearn.model_selection import learning_curve
from sklearn.utils import shuffle
X_train, y_train = shuffle(X_train, y_train)
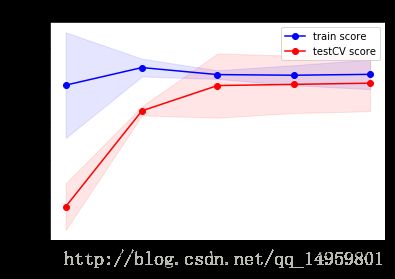
def plot_learning_curve(clf, title, X, y, ylim=None, cv=None, n_jobs=3, train_sizes=np.linspace(.05, 1., 5)):
train_sizes, train_scores, test_scores = learning_curve(
clf, X, y, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
ax = plt.figure().add_subplot(111)
ax.set_title(title)
if ylim is not None:
ax.ylim(*ylim)
ax.set_xlabel(u"train_num_of_samples")
ax.set_ylabel(u"score")
ax.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
ax.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
ax.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"train score")
ax.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"testCV score")
ax.legend(loc="best")
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
plot_learning_curve(grd, u"learning_rate", X_train, y_train)
Out[27]:
In [28]:
plt.show()
In [44]:
#from sklearn.metrics import roc_curve
import sklearn
import matplotlib.pyplot as plt
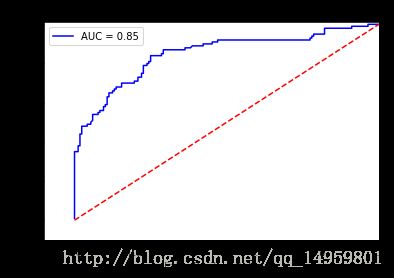
fpr,tpr,thresholds=sklearn.metrics.roc_curve(y_test,grd.predict_proba(X_test)[:,1],pos_label=1)#grd可以预测
roc_auc=sklearn.metrics.auc(fpr,tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr,tpr,'b',label='AUC = %0.2f'%roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.0])
plt.ylim([-0.1,1.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
In [45]:
#使用grd模型生成预测结果 并存入CSV
#df_test=pd.read_csv('D:/In/kaggle/Titanic/test.csv')
gender_submission = pd.DataFrame({'PassengerId':X_test.index,'Survived':grd.predict(X_test)})
gender_submission.to_csv('C://Users//zhangshuai_lc//submission_first.csv', index=None)