一步步带你看懂orbslam2源码--orb特征点提取(二)

ORB-SLAM2目录:
一步步带你看懂orbslam2源码–总体框架(一)
一步步带你看懂orbslam2源码–orb特征点提取(二)
一步步带你看懂orbslam2源码–单目初始化(三)
一步步带你看懂orbslam2源码–单应矩阵/基础矩阵,求解R,t(四)
一步步带你看懂orbslam2源码–单目初始化(五)
回顾:
上一节我们主要讲解了SLAM的基本分类,具体场景应用点以及目前现有的部分开源方案.最后讲解了ORB-SLAM2的总体框架和主要贡献.
由于整个系统都是基于ORB特征点进行运行的,因此本章节将主要讲解ORB特征点的原理以及根据orb-slam2源码讲解实现细节.
理论环节
ORB特征点的原理
特征点,顾名思义就是图片中具备明显特征的点.在许多学者长期的研究下,著名的特征点有诸如:SIFT,SURF,FAST,ORB等.通常我们说提取特征点,实际上则包括提取关键点和计算描述子两个过程.
SIFT特征点具备良好的尺度和方向不变性,而且对光照,抖动等噪声具有较强的鲁棒性.但由于SIFT的计算量比较大,根据orbslam2作者发表的论文"ORB-SLAM a Versatile and Accurate Monocular SLAM System"中可以知道,一张照片提取1000个SIFT特征点的平均时间为300ms,无法实现实时的SLAM系统,虽然后面有学者提出了在GPU加速下能够实现实时,但是毕竟实际的应用场景中,SLAM主要是为上层应用提高感知信息,理应不能占用过多的计算资源.而基于SIFT描述子改进的SURF描述子尽管提高了一个数量级的提取效率,但仍然无法满足SLAM系统的要求.
FAST特征点则直接利用了关键点与周围像素点灰度值的关系,提取时间非常短,能够实现实时计算,但是FAST关键点不具备尺度和方向不变性,无法应用与SLAM系统.而ORB特征点则结合了一种改进的FAST关键点和BRIEF,具备有良好的尺度和方向不变性.提取一张照片的ORB特征点大约需要15ms,既实现了实时性,同时还保证了所提取特征点的可靠性.
ORB特征点的提取是基于图像金字塔的,在不同尺度的图像上面提取Oriented FAST 关键点(增加了方向的FAST关键点)和 BRIEF 描述子,以此来实现尺度和方向的不变性,具体原理将在下文阐述.
提取FAST关键点

检测像素点P是否为FAST关键点,首先以P点为中心,取半径为3的圆上的16个像素点,如上图所示.假设P点处的灰度值: I p I_p Ip,设定阈值 T T T,如果在这16个点当中,有连续 N N N( N N N通常取12,即为 FAST-12)个点不满足:
I p − T ≤ I p ≤ I p + T I_p-T\le I_p≤I_p+T Ip−T≤Ip≤Ip+T
即判断该像素点P为FAST关键点.不过,通常为了再进一步的提高提取速度,大家都会先进行一步预测试操作,即先判断 P 点周围上下左右4个像素点,如果有3个点符合要求才进一步判断其他的像素点.但是如果仅仅是这样子提取,难免会出现特征点扎堆等情况.因此,我们通常在提取特征点的时候都会进行非极大值抑制(Non-maximal suppression),即在一小块区域内,只取最大Harris响应值的前 N N N个.
你以为这样子就算提取FAST关键点完成了??其实并不然,ORB特征点提取的是Oriented FAST,即加入了方向,具体操作步骤如下:

至此,才算完成了FAST关键点的提取.
计算BRIEF描述子
orbslam2中的brief描述子是一种二进制描述子,总共具有256bit,即32个字节的长度.每位bit为0或1.根据一定的点对选取规则选择点对,该选取规则应当使点对与点对之间的相关性最低(换言之,点对与点对之间尽量垂直,毕竟本科时候概率论中应该说过吧…哈哈哈…如果你有细看源码,你会发现在 ORBextractor.cc 文件中有一个bit_pattern_31_数组,里面就是存放了256点对的坐标 )并判断该点对两个像素点的灰度值大小(比如说 p p p和 q q q的关系, p > q p>q p>q则取1,否则取0)

图像金字塔的构建
谈完了Oriented FAST关键点的提取和BRIEF描述子的计算,笔者还是觉得有必要讲解一下金字塔构建的机理,毕竟Oriented FAST和BRIEF的计算都是基于图像金字塔上面操作的.
为什么要构建图像金字塔呢?假想你在很远的地方看到一个美女,真特么漂亮,但是你走近了之后发现,特么油光满面,满面痘痘…咳咳咳~~举这个例子呢,主要是为了说明在不同的距离情况下,观看同一事物会产生不同的结果,毕竟太远了,变模糊了,看不清了是吧.同样,在相机中也会发生这种情况,这个时候我们就人为的构造不同尺度的图像,来模拟不同距离下观看同一事物的结果,这就是传说中的图像金字塔.如果在进行尺度变换之前图片有进行高斯模糊过,即用高斯核进行卷积,则又可以称之为高斯图像金字塔.
在opencv库中,pyrDown/pyrUp和resize都可以达到缩放图像的目的,区别是前者是先高斯模糊然后采样,后者通过插值的方法实现.很遗憾的是orbslam2中采用的是插值的方法(resize函数)(咳咳~这样我就不用去讲解麻烦的卷积过程了…真好…虽然后面还是有对金字塔的图片进行了高斯模糊…)
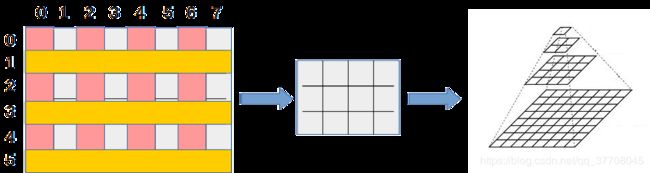
如上,假设一张8×6的图片,尺度因子 s c a l e scale scale为2,意味着把原图像的 w i d t h width width和 h i g h t hight hight缩小为原来的 1 2 \dfrac{1}{2} 21,整张图片将缩放为原来的 1 4 \dfrac{1}{4} 41.如上图所示,把图片中有颜色的行和列从图片矩阵中删除掉,剩下的行和列组成一张新的图片,这不就是变成 1 4 \dfrac{1}{4} 41了么.图像金字塔构建的层数可以由自己设定,orbslam2中的 l e v e l level level为8层,其中第0层即为原图像,层数越高图片越小,越模糊,第 n n n层为原图像大小的 1 s c a l e n \dfrac{1}{scale^n} scalen1.
源码分析环节
讲完以上三点基本内容,我们接下来就可以结合orbslam2–单目版本的源代码给大家讲解下啦~~~~
根据前讲的介绍,程序将进入单目Tracking接口:
SLAM.TrackMonocular(im,tframe);// im为图片 tframe为时间
然后,系统将时刻判断当前是否激活定位模式和是否系统复位,这个主要是系统在运行时,显示界面中的选择按钮,读者可以在运行系统时尝试改变界面上的选项,实现代码主要如下:
// Check mode change
{
unique_lock<mutex> lock(mMutexMode);
if(mbActivateLocalizationMode)//激活定位模式
{
mpLocalMapper->RequestStop();
// Wait until Local Mapping has effectively stopped
while(!mpLocalMapper->isStopped())
{
usleep(1000);
}
mpTracker->InformOnlyTracking(true);
mbActivateLocalizationMode = false;//确保只执行一次
}
if(mbDeactivateLocalizationMode)//非激活定位模式
{
mpTracker->InformOnlyTracking(false);
mpLocalMapper->Release();
mbDeactivateLocalizationMode = false;//确保只执行一次
}
}
// Check reset
{
unique_lock<mutex> lock(mMutexReset);
if(mbReset)
{
mpTracker->Reset();
mbReset = false;
}
}
中间部分代码比较简单,就不一一介绍,也没办法整个源码一字不差的介绍,最后程序将进入下列该入口,进行ORB特征点的提取:
// ORB extraction
ExtractORB(0,imGray);
让我们来看看这个函数里面是什么东西,点开一看,发现此处调用了一个重载过的括号运算符.
void Frame::ExtractORB(int flag, const cv::Mat &im)
{
// mpORBextractorLeft是ORBextractor对象,因为ORBextractor重载了()
// 所以才会有下面这种用法
if(flag==0)
(*mpORBextractorLeft)(im,cv::Mat(),mvKeys,mDescriptors);
else
(*mpORBextractorRight)(im,cv::Mat(),mvKeysRight,mDescriptorsRight);
}
进入重载括号运算符之中,其大体流程图如下.其中,主要包含了图像金字塔的构建,ORB特征点的提取两大模块,具体且听下文讲解.

图像金字塔的构建
其中,让我们看看它是如何实现金字塔的构建的(看源码之前,建议读者可以先看下后文简化后的版本,更易于理解哦~~):
void ORBextractor::ComputePyramid(cv::Mat image)
{
for (int level = 0; level < nlevels; ++level)
{
float scale = mvInvScaleFactor[level];
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));//Size(width,height)
Size wholeSize(sz.width + EDGE_THRESHOLD*2, sz.height + EDGE_THRESHOLD*2);//加上边缘阈值,算出整个大小
Mat temp(wholeSize, image.type()), masktemp;//按照scale比例缩放后,定义的相应大小的Mat
//Rect(矩形左上角横坐标,纵坐标以及矩形的宽度,高度),每经过一次循环,照片大小将按scale缩放,creat pre-created dist image
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
// Compute the resized image
if( level != 0 )
{
resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, INTER_LINEAR);
copyMakeBorder(mvImagePyramid[level], temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101+BORDER_ISOLATED);
}
else
{
copyMakeBorder(image, mvImagePyramid[0], EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101); //处理金字塔level为0的照片,即原图像
}
}
}
大体思路是先将原图片 image 存入 mvImagePyramid[0] ,然后每次循环都调用resize()函数,利用上一层的 mvImagePyramid[level-1] 构建下一层的 mvImagePyramid[level] ,以此类推…
最下面的一条语句中,笔者有些不解,原源码是这么写的:
copyMakeBorder(image, temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101); //处理金字塔level为0的照片,即原图像
笔者感觉如何此处将 mvImagePyramid[0] 改写成 temp ,还能实现金字塔的构建吗?虽然笔者改后,源码照样可以运行,但是却好像有点不太稳定~~
(PS:如有人知晓其缘由,还请不惜赐教)
不过貌似orbslam2源码中金字塔的构建有些冗余,其实在其他人的博文之中也有提到过,并有人对其进行简化版,如下:
void ORBextractor::ComputePyramid_brief(cv::Mat image) {
for (int level = 0; level < nlevels; ++level) {
float scale = mvInvScaleFactor[level];
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
// Compute the resized image
if (level != 0) {
resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, INTER_LINEAR);
} else {
mvImagePyramid[level] = image;
}
}
}
上面的这种写法其实就是我修改后的样子吧,只不过简化了,所以问题来了…源码那样子写怎么也没问题呢…留个疑问.
FAST关键点的提取
接着,程序将进入计算关键点并进行四叉树存储的,程序接口如下:
vector < vector<KeyPoint> > allKeypoints;
ComputeKeyPointsOctTree(allKeypoints);//关键点全部存在allKeypoints中
这个时候读者就会吐槽笔者了,明明上面写的是OctTree,这不是摆明的八叉树么,欺负我不认识英语么…其实不然,虽然函数名称写的是八叉树,但是实际执行过程确实是四叉树,所以为了更加准确的描述,笔者还是说为四叉树吧…
好了,先说说关键点的提取吧,为了保证提取关键点的均匀,作者将一张图片分为了30×30大小网格,在每个网格中提取关键点,并且在提取关键点时采用了非极大值抑制的方法.
注意:这里虽然是划分网格为30×30,但毕竟现实总不是那么理想了,哪有那么巧图片刚好就给你整数划分.所以,实际上后面在具体划分过程中都进行了微调.
首先,系统将会根据配置表(在ORB_SLAM2/Examples/Monocular/TUM2.yaml中可以查看到)中配置的iniThFAST阈值进行提取FAST关键点,如何提取不到,则降低阈值,采用minThFAST阈值进行提取.
ORBextractor.iniThFAST: 20
ORBextractor.minThFAST: 7
当然,它在对图像进行分割过程中,设置了上下左右边界,即不考虑图片的边缘,系统中设置边缘为16个像素点,具体解释看下面代码注释.
allKeypoints.resize(nlevels);
const float W = 30;//定义了网格的大小,实际大小会根据图片大小而定,看下文
for (int level = 0; level < nlevels; ++level)//一张图片,遍历整个金字塔
{
const int minBorderX = EDGE_THRESHOLD-3;//x,y轴边界阈值为16个像素
const int minBorderY = minBorderX;
const int maxBorderX = mvImagePyramid[level].cols-EDGE_THRESHOLD+3;
const int maxBorderY = mvImagePyramid[level].rows-EDGE_THRESHOLD+3;
vector<cv::KeyPoint> vToDistributeKeys;
vToDistributeKeys.reserve(nfeatures*10);
//计算出除去不考虑的边缘外,图片的width和height
const float width = (maxBorderX-minBorderX);
const float height = (maxBorderY-minBorderY);
const int nCols = width/W;//网格列,实际上可以值为21.6,然后取21,最多分为21个
const int nRows = height/W;//网格行
const int wCell = ceil(width/nCols);//向上取整,大于该值的最小整数,计算出实际上每个网格的宽
const int hCell = ceil(height/nRows);//计算出实际上每个网格的高
for(int i=0; i<nRows; i++)//遍历所有网格
{
const float iniY =minBorderY+i*hCell;
float maxY = iniY+hCell+6;
if(iniY>=maxBorderY-3)//超出图片Y轴范围
continue;
if(maxY>maxBorderY)//确保maxY的上限
maxY = maxBorderY;
for(int j=0; j<nCols; j++)
{
const float iniX =minBorderX+j*wCell;
float maxX = iniX+wCell+6;
if(iniX>=maxBorderX-6)
continue;
if(maxX>maxBorderX)
maxX = maxBorderX;
vector<cv::KeyPoint> vKeysCell;
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,iniThFAST,true);//提取FAST关键点,采用非极大值抑制,采用初始阈值提取FAST
if(vKeysCell.empty())//如果初始阈值提取不到FAST,则采用minTHFAST阈值提取
{
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,minThFAST,true);
}
if(!vKeysCell.empty())//将每个网格中的FAST关键点坐标转换为实际图像中(不包含边界)的坐标,并存入vToDistributeKeys
{
for(vector<cv::KeyPoint>::iterator vit=vKeysCell.begin(); vit!=vKeysCell.end();vit++)
{
(*vit).pt.x+=j*wCell;
(*vit).pt.y+=i*hCell;
vToDistributeKeys.push_back(*vit);
}
}
}
}
通过上述代码提取完该level图像上的FAST关键点后,此时关键点已存放于 vToDistributeKeys 向量当中 (该坐标已经从对应网格中的坐标转换为整幅图像的坐标,但是不包含边缘空隙),并进行四叉树存储,然后分别在四叉树的每个节点筛选出最高质量关键点,具体实现代码如下:
vector<KeyPoint> & keypoints = allKeypoints[level];
keypoints.reserve(nfeatures);
//将图片进行四叉树存储,筛选高质量关键点,确保均匀
keypoints = DistributeOctTree(vToDistributeKeys, minBorderX, maxBorderX,
minBorderY, maxBorderY,mnFeaturesPerLevel[level], level);
const int scaledPatchSize = PATCH_SIZE*mvScaleFactor[level];
// Add border to coordinates and scale information
const int nkps = keypoints.size();
for(int i=0; i<nkps ; i++)//记录关键点在图片实际坐标(包含边界),记录该金字塔level
{
keypoints[i].pt.x+=minBorderX;
keypoints[i].pt.y+=minBorderY;
keypoints[i].octave=level;
keypoints[i].size = scaledPatchSize;
}
经过筛选后的高质量的关键点将被存放于 keypoints 向量中 (此时关键点已经从不包含边缘的坐标转换为包含边缘的坐标).其中,四叉树存储思路如下:
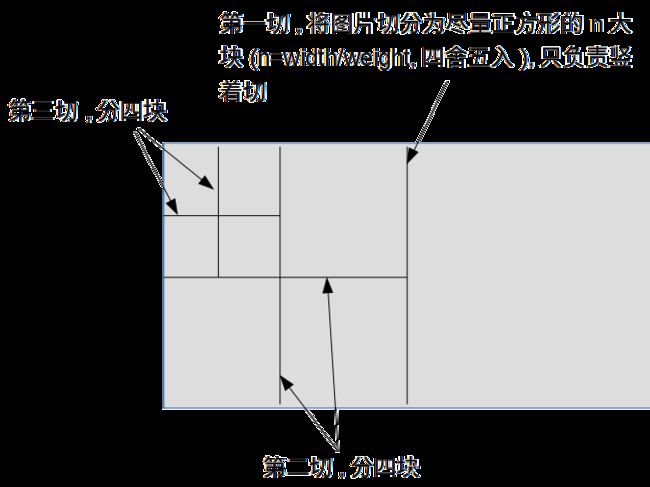
首先根据图片的 width/height 比值(四舍五入后的比值),将图片竖着划分为若干个根节点
const int nIni = round(static_cast<float>(maxX-minX)/(maxY-minY));//要求图片width/height≥0.5,TUM数据集nIni=1
然后开始使用四叉树的方法,每次切分,都将一个网格分为四等分,直至该节点只有一个关键点或者图片提取的关键点数量已经满足要求了,则停止切分.最后,通过以下代码,将每个节点中的最大 Harris 响应值存入 vResultKeys 向量,并返回.至此就算完成了FAST关键点的提取工作,实现代码如下.接下来就差描述子的计算了.
// Retain the best point in each node
vector<cv::KeyPoint> vResultKeys;
vResultKeys.reserve(nfeatures);
for(list<ExtractorNode>::iterator lit=lNodes.begin(); lit!=lNodes.end(); lit++)
{
vector<cv::KeyPoint> &vNodeKeys = lit->vKeys;
cv::KeyPoint* pKP = &vNodeKeys[0];
float maxResponse = pKP->response;
for(size_t k=1;k<vNodeKeys.size();k++)
{
if(vNodeKeys[k].response>maxResponse)
{
pKP = &vNodeKeys[k];
maxResponse = vNodeKeys[k].response;
}
}
vResultKeys.push_back(*pKP);//将每个节点中响应值最大的节点存入vResultKeys
}
到这里,可能就有同学想发出提问了:“老师,你不是说是Oriented FAST关键点的提取吗,FAST是提取了,但是Oriented呢!”
老师:“咳咳~~差点忘了…好吧,那我现在就讲解关于方向的计算,以下是实现代码.”
static void computeOrientation(const Mat& image, vector<KeyPoint>& keypoints, const vector<int>& umax)
{
for (vector<KeyPoint>::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
{
keypoint->angle = IC_Angle(image, keypoint->pt, umax);
}
}
其中,在传参中, image 为传入图像,这个就无需多言了.keypoints向量为需要计算描述子的关键点.umax向量为circular块的对应纵坐标v的最大正整数横坐标u.
这个时候,相信同学们也懵逼了,什么叫circular块的对应纵坐标v的最大正整数横坐标u呢?请继续耐心得看下去.
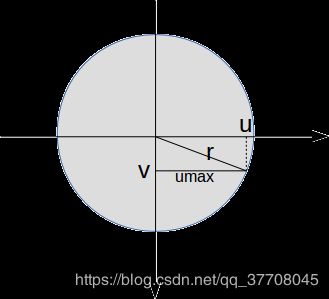
不知道同学看上面那个图能否看懂笔者想要表达的意思呢?FAST关键点在计算方向的时候,是针对一小图像块B进行计算的,在上面的理论环节中也有提及过.而orbslam2中的图像块就是选取了circular块,所以需要计算出每个纵坐标绝对值v下对应的横坐标的绝对值,知道了这个值就相当于知道了整个circular对应的范围在哪里了,不是吗?后面将会依赖该umax[v]进行计算整个图像块的像素值之和.
至此,Oriented FAST关键点才算真正地提取完成!!!
BRIEF描述子的计算
上面的FAST关键点提取是在金字塔的基础上进行操作的.同样的,BRIEF描述子的计算也是基于图像金字塔.主要通过以下代码实现:
static void computeDescriptors(const Mat& image, vector<KeyPoint>& keypoints, Mat& descriptors,
const vector<Point>& pattern)
{
descriptors = Mat::zeros((int)keypoints.size(), 32, CV_8UC1);
for (size_t i = 0; i < keypoints.size(); i++)
computeOrbDescriptor(keypoints[i], image, &pattern[0], descriptors.ptr((int)i));
}
其中,传参中的 pattern 为输入的点对,从如下源码中我们可以发现
const int npoints = 512;
const Point* pattern0 = (const Point*)bit_pattern_31_;
std::copy(pattern0, pattern0 + npoints, std::back_inserter(pattern));
传入的是一个 bit_pattern_31_ 数组,该数组总共有512个字节,256组点对,相信同学们没忘记前文理论中所写的计算描述子的方式吧,就是通过判断点对的像素值关系,决定该赋值1还是0.那个数组稍微有点长,笔者就贴一点代码也大家看看,大概有个直观感受就好了…
static int bit_pattern_31_[256*4] =
{
8,-3, 9,5/*mean (0), correlation (0)*/,
4,2, 7,-12/*mean (1.12461e-05), correlation (0.0437584)*/,
-11,9, -8,2/*mean (3.37382e-05), correlation (0.0617409)*/,
...
};
到这里,本章节的学习内容就差不多了,相信同学们到此肯定会有所收获,但是具体的各种实现细节和语句,还需要同学们从源码中再细细体会.
总结
- ORB特征点的原理,其中是如何实现尺度和方向不变性的.
- Oriented FAST关键点提取.
- BRIEF描述子的计算.
- 图像金字塔的构建方法.
参考文献:
- 高翔–视觉SLAM十四讲
- ORB-SLAM a Versatile and Accurate Monocular SLAM System
PS:
- 如果您觉得我的博客对您有所帮助,欢迎关注我的博客。此外,欢迎转载我的文章,但请注明出处链接。
- 本博客仅代表个人观点,不一定完全正确,如有出错之处,也欢迎批评指正.
上一章节:一步步带你看懂orbslam2源码–总体框架(一)
下一章节:一步步带你看懂orbslam2源码–单目初始化(三)