简单的神经网络提高精度的方法(学习心得)——MNIST手写数字集
初始的代码
//载入数据集
//one_hot 转化数据某一位是1 其他位为0
mnist =input_data.read_data_sets("D:\Python\MNIST_data",one_hot=True)
//每个批次的大小 以矩阵形式一次性放入200张到神经网络中去
batch_size=200
//计算一共有多少个批次=总量/批次
n_batch=mnist.train.num_examples//batch_size
//定义两个placeholder
x=tf.placeholder(tf.float32,[None,784])#none和批次有关
y=tf.placeholder(tf.float32,[None,10])#y是标签
//创建一个简单的神经网络
//输入层784个神经元 输出层10个神经元
//权值,偏置值
W=tf.Variable(tf.zeros([784,10]))
b=tf.Variable(tf.zeros([10]))
prediction=tf.nn.softmax(tf.matmul(x,W)+b)
//二次代价函数
loss=tf.reduce_mean(tf.square(y-prediction))
//梯度下降法
train_strp=tf.train.GradientDescentOptimizer(0.2).minimize(loss)
//初始化变量
init=tf.global_variables_initializer()
//求准确率的方法: 两个结果是预测与真实的值判断 结果存放在一个布尔型列表中 equal相同返回true 不同false
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
//argmax返回一维向量中最大的值所在的位置 也就是他的标签
//求准确率
//tf.cast(correct_prediction,tf.float32) 将布尔型转化为浮点型数据 true=1.0 false=0.0
//reduce_mean求平均值
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
//开始训练
with tf.Session() as sess:
sess.run(init)
for epoch in range(30):#//把所有的图片训练30次
for batch in range(n_batch)://把所有的图片循环了一次
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
//图片数据保存在xs 图片标签保存在ys
sess.run(train_strp,feed_dict={x:batch_xs,y:batch_ys})
//执行accuracy这个方法 参数就是feed_dict里面的数据
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print('Iter'+str(epoch)+",Testing Accuracy"+str(acc))
不使用lstm和卷积神经网络的情况下提高识别准确率
1、批次的大小可以修改batch_size=200
2、可以增加隐藏层 激活函数、神经元都可尝试
3、将权值和偏置值初始化为0 或初始化方式 是否效果会好
4、代价函数 使用交叉熵
5、学习率
6、可以尝试更多的训练次数
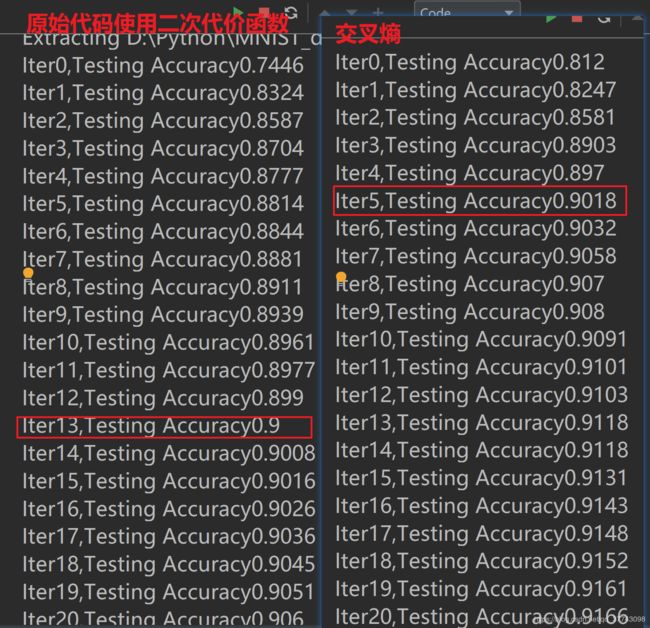
交叉熵(可以加快模型收敛速度)
// 将二次代价函数换为交叉熵 对比结果 其他都没变化
//交叉熵并且求平均值
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
看到交叉熵在迭代5个周期就到了90 而二次代价函数迭代了13个周期
所以交叉熵速度快很多 并且效果好 花费较少的时间达到同样的效果
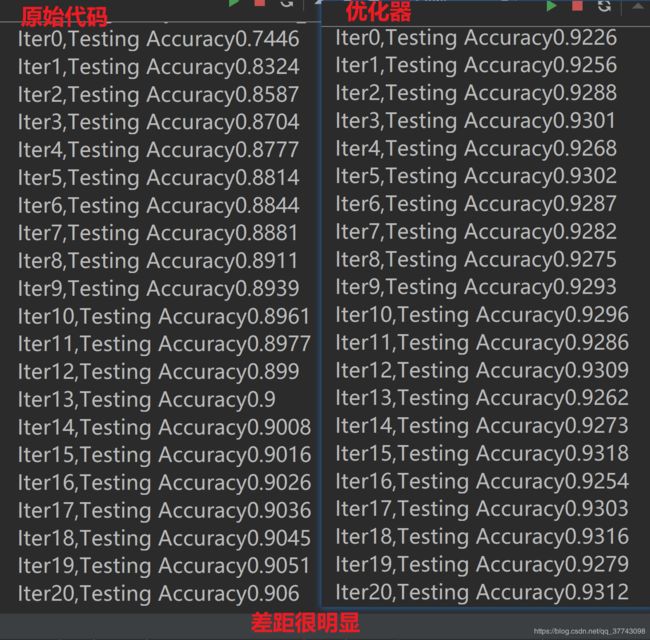
== 使用优化器==
// 使用优化器
//train_step=tf.train.GradientDescentOptimizer(0.2).minimize(loss)
train_step=tf.train.AdamOptimizer(1e-2).minimize(loss)
交叉熵+优化器
很快就到了93 但是没有提高 说明不是这么样用的 再学习一下

// 增加了中间层 还是采用二次代价函数
//定义神经网络中间层
W = tf.Variable(tf.zeros([784,100]))
b = tf.Variable(tf.random_normal([100]))
L1 = tf.nn.relu(tf.matmul(x,W) + b)
//定义神经网络输出层
W_2 = tf.Variable(tf.random_normal([100,10]))
b_2 = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(L1,W_2) + b_2)
//二次代价函数
loss=tf.reduce_mean(tf.square(y-prediction))
//优化器
train_strp=tf.train.MomentumOptimizer(0.2,0.9).minimize(loss)
精度提高到96

其他的方法陆续学习 并 尝试
第一次更新:2019/3/2
第二次更新:2019/3/3