SLAM基础问题总结(3)
1、推导直接法BA,直接法的分类,三个假设及优劣
p 1 = [ u v 1 ] = 1 Z 1 K P \boldsymbol{p}_{1}=\left[\begin{array}{c}{u} \\ {v} \\ {1}\end{array}\right]=\frac{1}{Z_{1}} \boldsymbol{K} \boldsymbol{P} p1=⎣⎡uv1⎦⎤=Z11KP. p 2 = [ u v 1 ] = 1 Z 2 K ( R P + t ) = 1 Z 2 K ( exp ( ξ ∧ ) P ) 1 : 3 \boldsymbol{p}_{2}=\left[\begin{array}{c}{u} \\ {v} \\ {1}\end{array}\right]=\frac{1}{Z_{2}} \boldsymbol{K}(\boldsymbol{R} \boldsymbol{P}+\boldsymbol{t})=\frac{1}{Z_{2}} \boldsymbol{K}\left(\exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P}\right)_{1 : 3} p2=⎣⎡uv1⎦⎤=Z21K(RP+t)=Z21K(exp(ξ∧)P)1:3
优化相机的位姿,来寻找与 p1 更相似的 p2 。这同样可以通过解一个优化问题,但此时最小化的不是重投影误差,而是光度误差(Photometric Error),也就是 P 的两个像素的亮度误差: e = I 1 ( p 1 ) − I 2 ( p 2 ) e=\boldsymbol{I}_{1}\left(\boldsymbol{p}_{1}\right)-\boldsymbol{I}_{2}\left(\boldsymbol{p}_{2}\right) e=I1(p1)−I2(p2)在直接法中,假设一个空间点在各个视角下,成像的灰度是不变的。有许多个(比如 N 个)空间点 Pi ,那么,整个相机位姿估计问题变为: min ξ J ( ξ ) = ∑ i = 1 N e i T e i , e i = I 1 ( p 1 , i ) − I 2 ( p 2 , i ) \min _{\xi} J(\boldsymbol{\xi})=\sum_{i=1}^{N} e_{i}^{T} e_{i}, \quad e_{i}=\boldsymbol{I}_{1}\left(\boldsymbol{p}_{1, i}\right)-\boldsymbol{I}_{2}\left(\boldsymbol{p}_{2, i}\right) ξminJ(ξ)=i=1∑NeiTei,ei=I1(p1,i)−I2(p2,i)给 exp(ξ) 左乘一个小扰动 exp(δξ),得: e ( ξ ⊕ δ ξ ) = I 1 ( 1 Z 1 K P ) − I 2 ( 1 Z 2 K exp ( δ ξ ∧ ) exp ( ξ ∧ ) P ) ≈ I 1 ( 1 Z 1 K P ) − I 2 ( 1 Z 2 K ( 1 + δ ξ ∧ ) exp ( ξ ∧ ) P ) = I 1 ( 1 Z 1 K P ) − I 2 ( 1 Z 2 K exp ( ξ ∧ ) P + 1 Z 2 K δ ξ ∧ exp ( ξ ∧ ) P ) \begin{aligned} e(\boldsymbol{\xi} \oplus \delta \boldsymbol{\xi}) &=\boldsymbol{I}_{1}\left(\frac{1}{Z_{1}} \boldsymbol{K} \boldsymbol{P}\right)-\boldsymbol{I}_{2}\left(\frac{1}{Z_{2}} \boldsymbol{K} \exp \left(\delta \boldsymbol{\xi}^{\wedge}\right) \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P}\right) \\ & \approx \boldsymbol{I}_{1}\left(\frac{1}{Z_{1}} \boldsymbol{K} \boldsymbol{P}\right)-\boldsymbol{I}_{2}\left(\frac{1}{Z_{2}} \boldsymbol{K}\left(1+\delta \boldsymbol{\xi}^{\wedge}\right) \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P}\right) \\ &=\boldsymbol{I}_{1}\left(\frac{1}{Z_{1}} \boldsymbol{K} \boldsymbol{P}\right)-\boldsymbol{I}_{2}\left(\frac{1}{Z_{2}} \boldsymbol{K} \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P}+\frac{1}{Z_{2}} \boldsymbol{K} \delta \boldsymbol{\xi}^{\wedge} \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P}\right) \end{aligned} e(ξ⊕δξ)=I1(Z11KP)−I2(Z21Kexp(δξ∧)exp(ξ∧)P)≈I1(Z11KP)−I2(Z21K(1+δξ∧)exp(ξ∧)P)=I1(Z11KP)−I2(Z21Kexp(ξ∧)P+Z21Kδξ∧exp(ξ∧)P)记: q = δ ξ ∧ exp ( ξ ∧ ) P u = 1 Z 2 K q \begin{aligned} \boldsymbol{q} &=\delta \boldsymbol{\xi}^{\wedge} \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P} \\ \boldsymbol{u} &=\frac{1}{Z_{2}} \boldsymbol{K} \boldsymbol{q} \end{aligned} qu=δξ∧exp(ξ∧)P=Z21Kq利用一阶泰勒展开,有: e ( ξ ⊕ δ ξ ) = I 1 ( 1 Z 1 K P ) − I 2 ( 1 Z 2 K exp ( ξ ∧ ) P + u ) ≈ I 1 ( 1 Z 1 K P ) − I 2 ( 1 Z 2 K exp ( ξ ∧ ) P ) − ∂ I 2 ∂ u ∂ u ∂ q ∂ q ∂ δ ξ δ ξ = e ( ξ ) − ∂ I 2 ∂ u ∂ u ∂ q ∂ q ∂ δ ξ δ ξ \begin{aligned} e(\boldsymbol{\xi} \oplus \delta \boldsymbol{\xi}) &=\boldsymbol{I}_{1}\left(\frac{1}{Z_{1}} \boldsymbol{K} \boldsymbol{P}\right)-\boldsymbol{I}_{2}\left(\frac{1}{Z_{2}} \boldsymbol{K} \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P}+\boldsymbol{u}\right) \\ & \approx \boldsymbol{I}_{1}\left(\frac{1}{Z_{1}} \boldsymbol{K} \boldsymbol{P}\right)-\boldsymbol{I}_{2}\left(\frac{1}{Z_{2}} \boldsymbol{K} \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{P}\right)-\frac{\partial \boldsymbol{I}_{2}}{\partial \boldsymbol{u}} \frac{\partial \boldsymbol{u}}{\partial \boldsymbol{q}} \frac{\partial \boldsymbol{q}}{\partial \delta \xi} \delta \boldsymbol{\xi} \\ &=e(\boldsymbol{\xi})-\frac{\partial \boldsymbol{I}_{2}}{\partial \boldsymbol{u}} \frac{\partial \boldsymbol{u}}{\partial \boldsymbol{q}} \frac{\partial \boldsymbol{q}}{\partial \delta \boldsymbol{\xi}} \delta \boldsymbol{\xi} \end{aligned} e(ξ⊕δξ)=I1(Z11KP)−I2(Z21Kexp(ξ∧)P+u)≈I1(Z11KP)−I2(Z21Kexp(ξ∧)P)−∂u∂I2∂q∂u∂δξ∂qδξ=e(ξ)−∂u∂I2∂q∂u∂δξ∂qδξ ∂I2 /∂u 为 u 处的像素梯度;
∂u/∂q 为投影方程关于相机坐标系下的三维点的导数。 ∂ u ∂ q = [ ∂ u ∂ X ∂ u ∂ Y ∂ u ∂ Z ∂ v ∂ X ∂ v ∂ Y ∂ v ∂ Z ] = [ f x Z 0 − f x X Z 2 0 f y Z − f y Y Z 2 ] \frac{\partial \boldsymbol{u}}{\partial \boldsymbol{q}}=\left[\begin{array}{ccc}{\frac{\partial u}{\partial X}} & {\frac{\partial u}{\partial Y}} & {\frac{\partial u}{\partial Z}} \\ {\frac{\partial v}{\partial X}} & {\frac{\partial v}{\partial Y}} & {\frac{\partial v}{\partial Z}}\end{array}\right]=\left[\begin{array}{ccc}{\frac{f_{x}}{Z}} & {0} & {-\frac{f_{x} X}{Z^{2}}} \\ {0} & {\frac{f_{y}}{Z}} & {-\frac{f_{y} Y}{Z^{2}}}\end{array}\right] ∂q∂u=[∂X∂u∂X∂v∂Y∂u∂Y∂v∂Z∂u∂Z∂v]=[Zfx00Zfy−Z2fxX−Z2fyY]∂q/∂δξ 为变换后的三维点对变换的导数: ∂ q ∂ δ ξ = [ I , − q ∧ ] \frac{\partial \boldsymbol{q}}{\partial \delta \boldsymbol{\xi}}=\left[\boldsymbol{I},-\boldsymbol{q}^{\wedge}\right] ∂δξ∂q=[I,−q∧]推导了误差相对于李代数的雅可比矩阵: J = − ∂ I 2 ∂ u ∂ u ∂ ξ \boldsymbol{J}=-\frac{\partial \boldsymbol{I}_{2}}{\partial \boldsymbol{u}} \frac{\partial \boldsymbol{u}}{\partial \boldsymbol{\xi}} J=−∂u∂I2∂ξ∂u其中: ∂ u ∂ δ ξ = [ f x Z 0 − f x X Z 2 − f x X Y Z 2 f x + f x X 2 Z 2 − f x Y Z 0 f y Z − f y Y Z 2 − f y − f y Y 2 Z 2 f y X Y Z 2 f y X Z ] \frac{\partial \boldsymbol{u}}{\partial \delta \boldsymbol{\xi}}=\left[\begin{array}{cccccc}{\frac{f_{x}}{Z}} & {0} & {-\frac{f_{x} X}{Z^{2}}} & {-\frac{f_{x} X Y}{Z^{2}}} & {f_{x}+\frac{f_{x} X^{2}}{Z^{2}}} & {-\frac{f_{x} Y}{Z}} \\ {0} & {\frac{f_{y}}{Z}} & {-\frac{f_{y} Y}{Z^{2}}} & {-f_{y}-\frac{f_{y} Y^{2}}{Z^{2}}} & {\frac{f_{y} X Y}{Z^{2}}} & {\frac{f_{y} X}{Z}}\end{array}\right] ∂δξ∂u=[Zfx00Zfy−Z2fxX−Z2fyY−Z2fxXY−fy−Z2fyY2fx+Z2fxX2Z2fyXY−ZfxYZfyX]然后使用 G-N 或L-M 计算增量,迭代求解。
直接法分类:
- 稀疏直接法通常我们使用数百个至上千个关键点,并且像 L-K 光流那样,假设它周围像素也是不变的。这种稀疏直接法不必计算描述子,并且只使用数百个像素,因此速度最快,但只能计算稀疏的重构。
- 考虑只使用带有梯度的像素点,舍弃像素梯度不明显的地方。这称之为半稠密(Semi-Dense)的直接法,可以重构一个半稠密结构。
- P 为所有像素,称为稠密直接法。稠密重构需要计算所有像素(一般几十万至几百个),因此多数不能在现有的 CPU 上实时计算,需要GPU 的加速。
直接法完全依靠优化来求解相机位姿。像素梯度引导着优化的方向。如果我们想要得到正确的优化结果,就必须保证大部分像素梯度能够把优化引导到正确的方向。
优点:
- 可以省去计算特征点、描述子的时间。
- 只要求有像素梯度即可,无须特征点。因此,直接法可以在特征缺失的场合下使用。比较极端的例子是只有渐变的一张图像。它可能无法提取角点类特征,但可以用直接法估计它的运动。
- 可以构建半稠密乃至稠密的地图,这是特征点法无法做到的。
缺点:
- 非凸性——直接法完全依靠梯度搜索,降低目标函数来计算相机位姿。其目标函数中需要取像素点的灰度值,而图像是强烈非凸的函数。这使得优化算法容易进入极小,只在运动很小时直接法才能成功。
- 单个像素没有区分度。找一个和他像的实在太多了!——于是我们要么计算图像块,要么计算复杂的相关性。由于每个像素对改变相机运动的“意见”不一致。只能少数服从多数,以数量代替质量。
- 灰度值不变是很强的假设。如果相机是自动曝光的,当它调整曝光参数时,会使得图像整体变亮或变暗。光照变化时亦会出现这种情况。特征点法对光照具有一定的容忍性,而直接法由于计算灰度间的差异,整体灰度变化会破坏灰度不变假设,使算法失败。针对这一点,目前的直接法开始使用更细致的光度模型标定相机,以便在曝光时间变化时也能让直接法工作。
2、什么是闭环检测?常用的方法有哪些?有没有创新?
闭环检测:
- 相机经过了同一个地方,采集到了相似的数据。回环检测的关键,就是如何有效地检测出相机经过同一个地方这件事。可以为后端的 Pose
Graph 提供更多的有效数据,使之得到更好的估计,特别是得到一个全局一致(GlobalConsistent)的估计。还可以利用回环检测进行重定位。
方法:
- 对任意两张图像都做一遍特征匹配,根据正确匹配的数量确定哪两个图像存在关联。
- Bag-of-Words(BoW)----k-means++、K 叉树字典
创新:
- 是否能对机器学习的图像特征进行聚类,而不是 SURF、ORB 这样的人工设计特征 进行聚类?
- 是否有更好的方式进行聚类,而不是用树结构加上 K-means 这些较朴素的方式?结合目前机器学习的发展,二进制描述子的学习和无监督的聚类,都是很有望在深度学习框架中得以解决的问题。
- HBST:https://gitlab.com/srrg-software/srrg_hbst
3、简单描述Ceres优化库
Ceres 库面向通用的最小二乘问题的求解,Ceres 求解的最小二乘问题最一般的形式如下(带边界的核函数最小二乘): min x 1 2 ∑ i ρ i ( ∥ f i ( x i 1 , … x i n ) ∥ 2 ) s.t. l j ≤ x j ≤ u j \begin{array}{ll}{\min _{x}} & {\frac{1}{2} \sum_{i} \rho_{i}\left(\left\|f_{i}\left(x_{i_{1}}, \ldots x_{i_{n}}\right)\right\|^{2}\right)} \\ {\text { s.t. }} & {l_{j} \leq x_{j} \leq u_{j}}\end{array} minx s.t. 21∑iρi(∥fi(xi1,…xin)∥2)lj≤xj≤uj核函数 ρ(·),优化变量为 x1 ,…,xn ,fi 称为代价函数(Cost function),在 SLAM 中亦可理解为误差项。lj 和 uj 为第 j 个优化变量的上限和下限。在 Ceres 中,将定义优化变量 x 和每个代价函数 fi ,再调用 Ceres 进行求解。可以选择使用 G-N 或者 L-M 进行梯度下降,并设定梯度下降的条件,Ceres 会在优化之后,将最优估计值返回
4、描述(扩展)卡尔曼滤波与粒子滤波。
KF:主要参考这篇博客https://blog.csdn.net/u010720661/article/details/63253509
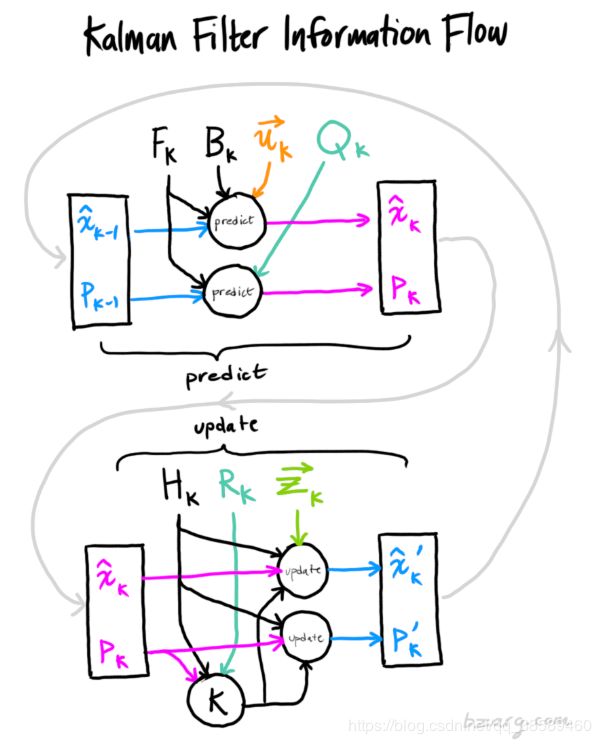
EKF:
- KF主要针对的是线性系统,SLAM 中的运动方程和观测方程通常是非线性函数,尤其是视觉 SLAM中的相机模型,需要使用相机内参模型以及李代数表示的位姿,更不可能是一个线性系统。
- 一个高斯分布,经过非线性变换后,往往不再是高斯分布,所以在非线性系统中,必须取一定的近似,将一个非高斯的分布近似成一个高斯分布。
把卡尔曼滤波器的结果拓展到非线性系统中来,称为扩展卡尔曼滤波器(Ex-tended Kalman Filter,EKF)。通常的做法是,在某个点附近考虑运动方程以及观测方程的一阶泰勒展开,只保留一阶项,即线性的部分,然后按照线性系统进行推导。令 k−1 时刻的均值与协方差矩阵为:
x ^ k − 1 , P ^ k − 1 \hat{\boldsymbol{x}}_{k-1}, \hat{\boldsymbol{P}}_{k-1} x^k−1,P^k−1卡尔曼增益 K k \boldsymbol{K}_{k} Kk K k = P ‾ k H T ( H P ‾ k H T + Q k ) − 1 \boldsymbol{K}_{k}=\overline{\boldsymbol{P}}_{k} \boldsymbol{H}^{\mathrm{T}}\left(\boldsymbol{H} \overline{\boldsymbol{P}}_{k} \boldsymbol{H}^{\mathrm{T}}+\boldsymbol{Q}_{k}\right)^{-1} Kk=PkHT(HPkHT+Qk)−1预测和更新方程: x ^ k = x ‾ k + K k ( z k − h ( x ‾ k ) ) , P ^ k = ( I − K k H ) P ‾ k \hat{\boldsymbol{x}}_{k}=\overline{\boldsymbol{x}}_{k}+\boldsymbol{K}_{k}\left(\boldsymbol{z}_{k}-h\left(\overline{\boldsymbol{x}}_{k}\right)\right), \hat{\boldsymbol{P}}_{k}=\left(\boldsymbol{I}-\boldsymbol{K}_{k} \boldsymbol{H}\right) \overline{\boldsymbol{P}}_{k} x^k=xk+Kk(zk−h(xk)),P^k=(I−KkH)Pk
EKF的局限:
- 滤波器方法在一定程度上假设了马尔可夫性,也就是 k 时刻的状态只与 k −1时刻相关,而与 k − 1 之前的状态和观测都无关。如果当前帧确实与很久之前的数据有关(例如回环),那么滤波器就会难以处理这种情况。
- EKF 滤波器仅在 x ^ k − 1 \hat{\boldsymbol{x}}_{k-1} x^k−1处做了一次线性化,但一阶泰勒展开并不一定能够近似整个函数。如果系统有强烈的非线性,那线性近似就只在很小范围内成立,不能认为在很远的地方仍能用线性来近似。这就是 EKF 的非线性误差,是它的主要问题所在。
- 从程序实现上来说,EKF 需要存储状态量的均值和方差,并对它们进行维护和更新。如果把路标也放进状态的话,由于视觉 SLAM 中路标数量很大,这个存储量是相当可观的,且与状态量呈平方增长(因为要存储协方差矩阵)。因此,EKF SLAM 普遍被认为不可适用于大型场景。
通常认为,在同等计算量的情况下,非线性优化能取得更好的效果。
粒子滤波:
主要参考博客:https://blog.csdn.net/piaoxuezhong/article/details/78619150
未完待续。。。。