[Note]关于Python中文编码出现乱码的解决方案(涉及urllib.urlopen(),open()等函数)
问题描述:
在做学校的SRTP项目,需要下载网页并储存到本地。
但网页url可能存在中文,网页源文件中也可能存在中文,需要选择合适的编码方式,已便正常显示中文。
若编码方式错误,可能出现以下问题:
1. 相关函数传参出错,如urllib.urlopen(url)函数,若url编码方式不对,会出现以下错误信息:
File "c:\Python27\lib\httplib.py", line 940, in endheaders
self._send_output(message_body)
File "c:\Python27\lib\httplib.py", line 803, in _send_output
self.send(msg)
File "c:\Python27\lib\httplib.py", line 775, in send
self.sock.sendall(str)
File "c:\Python27\lib\socket.py", line 222, in meth
return getattr(self._sock,name)(*args)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 9-10: ordinal not in range(128)
2. 文件名读取出错,如果open(filename,mode)中的filename编码出错,则会出现以下情况:
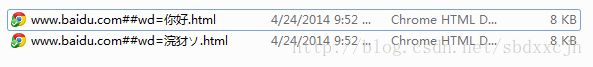
实际文件名应为“http://www.baidu.com/#wd=你好”(即第一行的文件名)
解决方案:
1. 使用urllib2库中的urlopen(url)函数来打开网页,函数参数url只能接受utf-8编码方式(因为博主的Python脚本文件用utf-8编码),
所以在传入url参数前,需要检查其编码方式:
from urllib2 import Request, urlopen, URLError, HTTPError
if isinstance(url,unicode):
url = url.encode("utf-8")
req = Request(url,headers=const.headers)
self.charset = const.default_charset
try:
response = urlopen(req, timeout = 10)
except Exception:
......上述代码中,isinstance()来检查url是否为unicode编码,若是,则转化为utf-8编码,否则不变。
为了保证和其他编码方式的兼容性(Compatibility),Unicode的前256字符保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需要特别考量。所以如果url中只含有英文字符(unicode的前256字符),它可以直接传入函数中,如果url中含有前256以外的字符,则需要用encode函数进行编码转换,再传入函数中。
本质上,isinstance(instance,class)可以用来检验一个对象(第一个参数),是否属于一个指定的类(第二个参数)
2. 在Windows系统下,中文文字用gbk编码,所以传入文件名参数时,应编码为GBK
if isinstance(filename,unicode):
filename = filename.encode("gbk")
else:
filename = filename.decode("utf-8").encode("gbk")
fp = open(filename,"w")
....这样,就会得到正确的文件名称。
注:博主一开始一直在utf-8与unicode之间转换,导致一晚上一直无法获得正确的文件名称.