Hadoop DataNode启动和初始化过程
目录
简介
源码解析
总结
简介
我们先看DataNode的doc文档的介绍,DataNode是一个类,用于存储一组块,用于DFS部署。 单个部署可以有一个或多个DataNode。 每个DataNode通信定期与单个NameNode进行通信。 它还可以与客户端和其他的DataNodes通信。
DataNode存储一系列命名的块。 DataNode允许客户端代码读取这些块,或者写新的块数据。 DataNode也可以响应于以下指令从其NameNode中删除区块或将区块复制到/从其他的DataNodes。
DataNodes的一生都在无休止的循环中度过,询问NameNode需要做哪些事情。 NameNode不能直接连接到DataNode;NameNode只是从DataNode调用的函数中返回值。
DataNodes维护一个开放的 server socket,以便客户端代码 或其他数据节点可以读/写数据。 读取/写入数据的主机/端口为汇报给NameNode,然后将该服务器的向客户或其他可能感兴趣的数据节点提供信息。
概括如下:
1):一个集群里面可以有好很多个datanode ,这些datanode就是用来存储数据的。
2):datanode启动了以后会周期性的与namenode进行通信(心跳 、 回报块)。
3):namenode不能直接操作datanode , 而是通信心跳返回指令的方式去操作datanode。
4):datanode启动了以后会开放一个socket发服务(RPC),等待调用。
源码解析
启动datanode,主要是要完成3件事:
1、如何完成存储。
2、如何与namenode进行通信,这个通过IPC 心跳连接实现。此外还有和客户端 其它datanode之间的信息交换。
3、完成和客户端还有其它节点的大规模通信,这个需要直接通过socket 协议实现。

本方法干两件事:
1、打印datanode启动日志,一些基本信息日志(域名、参数、版本、jdk环境等)
2、创建datanode
3、线程挂起
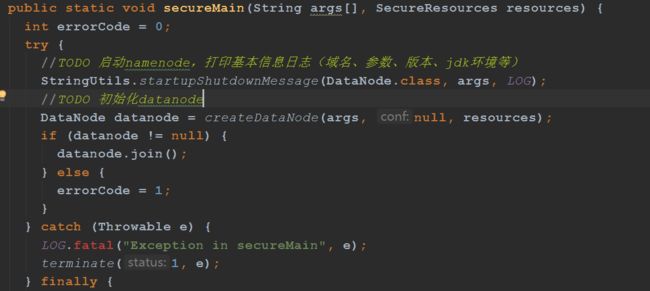
createDataNode方法主要两件事:
1、实例化一个DataNode
2、运行datanode的守护线程
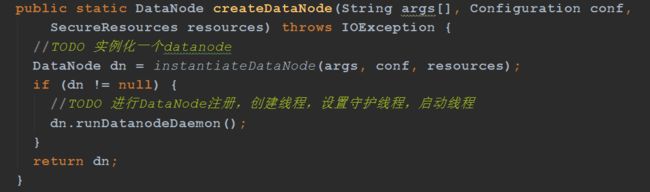
instantiateDataNode方法的作用
1、拿到数据存储路径(dfs.datanode.data.dir)
2、使用三个参数(数据存储路径、配置文件、SecureResources)去实例化Datanode
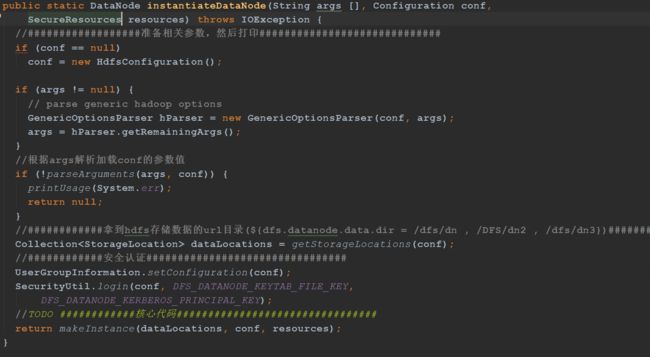
makeInstance方法主要的作用:
1、获取客户端校验类。
2、拿到存储数据目录的权限。
3、传入磁盘检测对象进行磁盘检测,并返回可用的目录列表。
4、创建datanode对象。
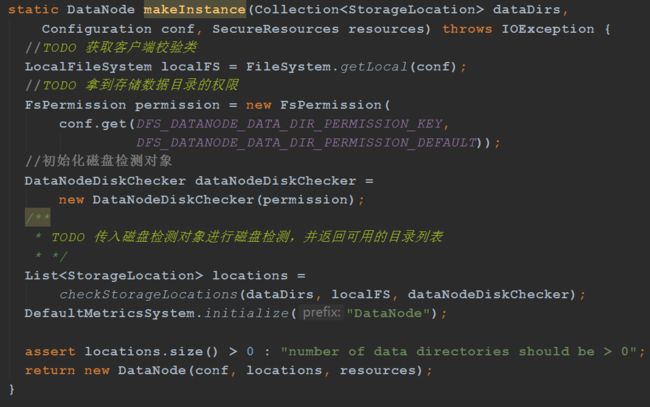
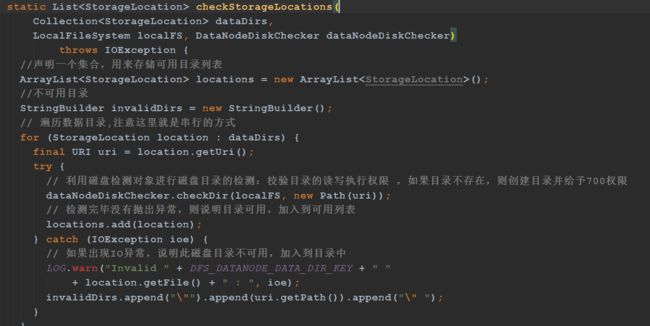
checkStorageLocations方法主要是利用磁盘检测对象进行磁盘目录的检测 , 返回可用磁盘目录列表
1、声明一个集合,用来存储可用目录列表
2、遍历数据目录,注意这里就是串行的方式
3、利用磁盘检测对象进行磁盘目录的检测:校验目录的读写执行权限 ,如果目录不存在,则创建目录并给予700权限
4、检测完毕没有抛出异常,则说明目录可用,加入到可用列表
5、如果出现IO异常,说明此磁盘目录不可用,加入到目录中
6、如果可用目录数量为0,表明所有的目录都不可用
7、最终,返回可用的磁盘目录列表
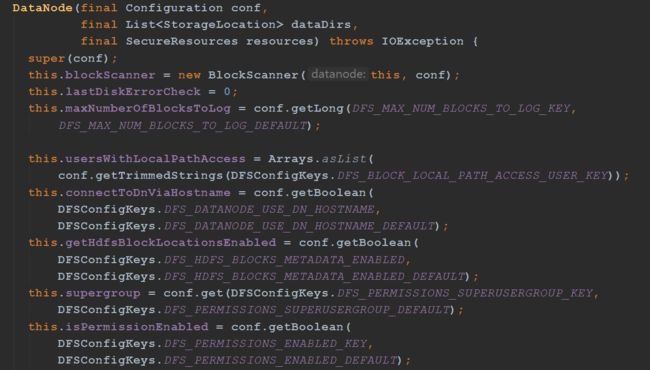
初始化方法,这个构造方法主要做了这几件事:
1、根据configuration,初始化一些成员变量
2、给出一个配置、一个dataDirs数组和一个Namenode代理,创建DataNode。
3、启动datanode
startDataNode方法启动datanode,这个方法很重要。
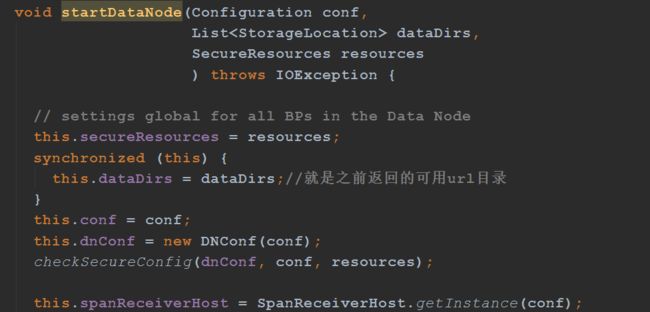
startDataNode是最关键的方法,非常非常重要
1、实例化管理磁盘目录的DataStorage
2、启动http和RPC
3、datanode向namenode注册和心跳
4、通过心跳汇报块
dfs.datanode.max.locked.memory: DataNode在内存中缓存副本块的最大内存数默认参数是0,表示不缓存副本块到内存;而且本地库还需要支持,如果不支持,也无法使用

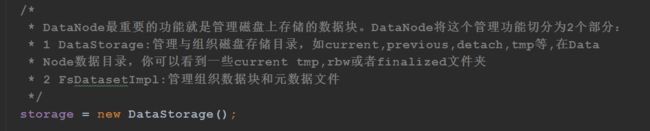
DataNode最重要的功能就是管理磁盘上存储的数据块。DataNode将这个管理功能切分为2个部分:
1 DataStorage:管理与组织磁盘存储目录,如current,previous,detach,tmp等,在Data
Node数据目录,你可以看到一些current tmp,rbw或者finalized文件夹
2 FsDatasetImpl:管理组织数据块和元数据文件
DataXceiverServer是数据节点DataNode上一个用于接收数据读写请求的后台工作线程,
为每个数据读写请求创建一个单独的线程去处理,DataNode#runDatanodeDaemon()中启动,后面再详细分析这个。
1、创建构造DataXceiverServer需要的TcpPeerServer实例tcpPeerServer,它内部封装了ServerSocket,是DataXceiverServer功能实现的最主要依托;
2、从tcpPeerServer中获取Socket地址InetSocketAddress,赋值给DataNode成员变量streamingAddr
3、然后构造DataXceiverServer实例xserver,传入tcpPeerServer;
4、构造dataXceiverServer守护线程,并将xserver加入之前创建的线程组threadGroup;
5、将线程组里的所有线程设置为设置为守护线程,方便虚拟机退出时自动销毁。
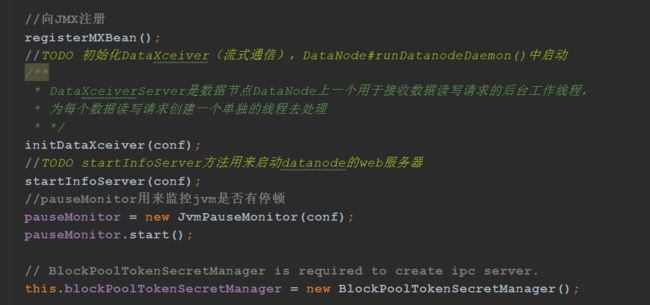
initIpcServer初始化IpcServer(RPC通信),DataNode#runDatanodeDaemon()中启动。用来启动datanode上的rpc服务,主要包括两个服务:ClientDatanodeProtocolPB和InterDatanodeProtocolPB。

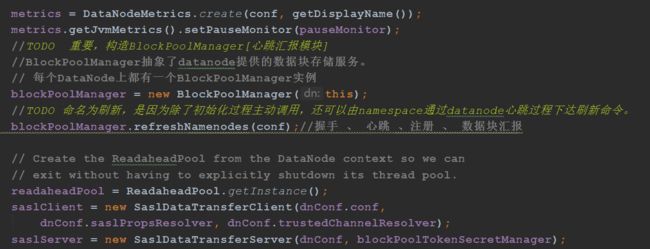
BlockPoolManager抽象了datanode提供的数据块存储服务,每个DataNode上都有一个BlockPoolManager实例
总结
这篇主要是DadaNode的启动和初始化的过程,可以看到还是比较复杂的,这篇文章只是写了一些大概的流程,一些细节还需要慢慢的去了解,每天学习一点点,持续行动,日拱一卒无有尽,功不唐捐终入海。