在首届阿里巴巴中间件峰会上,来自阿里的中间件架构师,Apache RocketMQ创始人冯嘉分享了《万亿级数据洪峰下的分布式消息引擎》。他主要从阿里消息引擎家族史、消息引擎面临的挑战,未来展望三个方面进行了分享。在分享中,他从可用性&可靠性挑战、熔断机制、开源HA机制改进三个方面入手着重介绍了“双十一”在高可用方面面临的挑战以及阿里消息引擎在高可用方面的优化改进。
以下内容根据直播视频整理而成。
阿里消息引擎的今生前世

上图展示了从2007年开始阿里消息引擎的发展。消息引擎围绕着RocketMQ内核,在阿里内部有三大块:Notify解决事务消息,采用服务端push模型,用于交易核心消息分发;MetaQ用于有序消息,采用pull模型,可以解决海量消息堆积;Aliware MQ是RocketMQ商业版,支持公有云、金融云、私有云、聚石塔。

上图展示了服务端的分层架构,整个的Server架构是对VM友好的,在容器中可以轻量化的启动,最上层是授权和认证,codec针对协议编码(TCP层面),中间是限流和熔断,下面是缓存cache,Mix Storage可以支持混合存储。
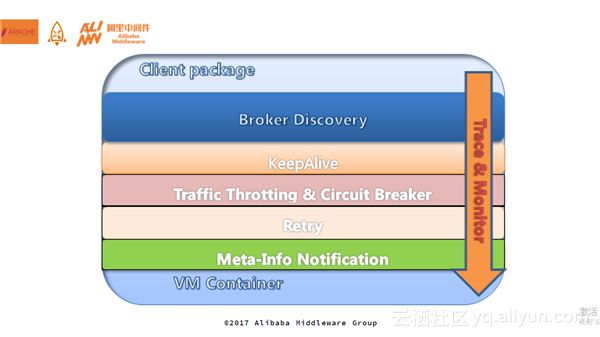
Client端的分层架构也类似。不论是微服务还是RPC,都会面临Broker Discovery服务发现、keepAlive长连接保持、限流和熔断。
消息引擎的主要使用场景包括异构系统互操作、异步解耦、微服务、Backbone for EDA or CEP、数据复制同步、流计算。
万亿级数据洪峰下的挑战

上图展示了“双十一”期间交易、购物车、红包火山的情况。通过这个场景可以看出,在“双十一”当日,面临两大挑战:可用性和可靠性。
可用性

根据上图公式可知,如果平均故障恢复时间是1秒的话,那么可用性可以达到五个9,注意是一天的时间里奥。在消息引擎中,我们希望可用性能够做到:1.每秒支撑千万级消息发布;2.每条消息发布最大响应时间不超过20ms;3.每条消息发布平均响应时间不超过3ms。但是,实际的场景中难免会出现慢请求的情况。针对慢请求、长尾效应,阿里给出的解决方案是:低延迟存储,使用预分配+内存锁,读写分离,二次异步;限流、熔断,降级,秒级隔离;多副本高可用机制,Zab、Paxos/Raft,自动/手动切换,容灾演练。
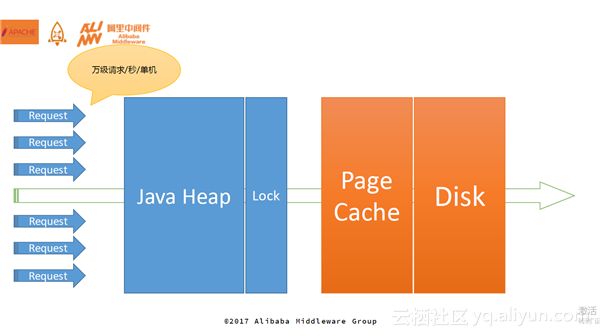
上图描述了消息过来之后需要经历的四大块:首先经过Java堆,然后经过Lock(控制读写),然后PageCache通过刷盘策略把消息刷到Disk中。RocketMQ的整个存储是基于PageCache的文件存储,经过系统地分析延迟、毛刺造成的原因,可以得出内存分配与消息读写是整个存储引擎需要优化的瓶颈点。

RocketMQ在使用内存过程中会碰到很多产生Latency的场景。比如在分配内存时,当内存触及水位watermark_low,会触发kswapd后台回收,如果分配内存的速度大于后台回收的速度,内存会逐渐减少至水位watermark_min,同时触发直接回收。直接回收对于匿名内存非常快,但是对于Page Cache来说非常慢,因为需要把脏页刷到磁盘上再去回收掉。另一方面,在访存时,如果目标内存被swap out到磁盘上,此时需要先进行内存分配,如上所述该过程可能会产生Latency,内存分配完毕后需要进行swap in将数据Load到内存当中,该过程会涉及文件IO,也会产生一定的Latency。所以,内存的延时主要来自于访问(读写)的时候以及内存分配的时候。

整个消息只有直达到磁盘里才能算写成功,可以在Lock和PageCache之间加一个Direct Memory作为缓冲,这部分内存进行池化,避免在使用内存时产生Latency。相当于消息写到Direct Memory就会返回,整个消息的响应时间得到了极大的提升。
通过上述的优化,我们获得的经验包括:操作系统Page Cache Radix Tree自旋锁,会产生几秒的大毛刺;如果遇到坏盘,可能Block若干分钟,对系统产生致命影响。操作系统内存的每个Page的阻塞锁,产生几百毫秒小毛刺。将这些进行优化之后,写入数据平均响应时间不超过1ms,写入数据最大响应时间不超过20ms(Java GC暂停线程引起)。
熔断机制
在容量保证部分,即熔断机制。如果应用中第四块消息服务器出现问题,则会将其隔离出来,隔离规则是:1.最多只能隔离30%的机器;2.响应时间过长,开始隔离1分钟;3.调用抛异常隔离1分钟;4.如果隔离的服务器超过30%,则有部分调用会进入隔离列表中最早隔离的机器。
开源HA机制改进
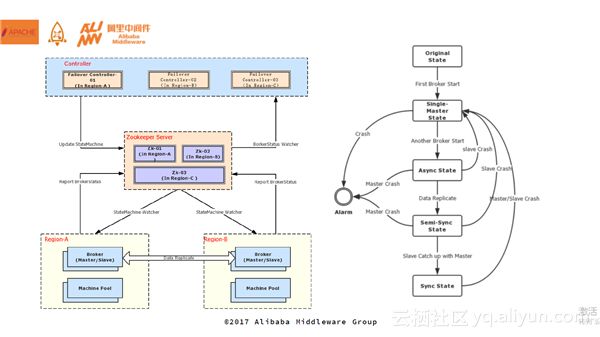
Controller是其中一个非常重要的组件,需要实时监控主备的节点状态,内部保证了三机房部署。Broker启动的时候,它会将状态进行上报,controller则会在另外一个集群中写下主备状态,最后将主备状态同步到name server上。现在,HA大部分采用同步双写,通过状态机可以进行主从同步描述。刚启动一个机器的时候,如果没有发现别的master那么它就是master,然后通过异步状态对外提供服务。再来一台机器后,由于已经有了master,那么它会作为slaver,不断通过数据复制,从主到备,到达一定的阈值之后状态扭转成半同步状态,此时主和备之间的落差变得很小很小。最终,经过一段时间变成主备全部同步的状态。
LinuxOpenMessaging、ApacheRocketMQ展望
OpenMessaging

整个规范主要分为三大块:API层、线路层、高级特性和管理。上图列出了早期做消息规范需要涉及的内容。比如分布式事务,内部的话一直在用阿里的MateQ和Notify,这种分布式事务是发送者分布式事务,并没有解决发送、broker、consumer之间的分布式事务,所以在OpenMessaging中把整个的分布式事务规划进去。负载均衡也有很多的策略,比如基于时间退递的。分布式追踪主要考虑Linux CNCF中的opentracing。协议桥接主要是考虑如何和现有的规范进行桥接。在整个的消息中做一些流计算算子,在消息投递的过程中就可以把计算逻辑做进去。Benchmark主要用于把大家拉到同一起跑线做性能测试。

上图是整个RocketMQ的生态如图,下面是企业级的应用,上面是基于大数据产生的一些新的需求。
总结来说,下一代的消息引擎主要做四个方面的事情:电子商务,保证高并发;物联网领域,解决在线连接处理,即长连接;大数据领域,解决吞吐问题;金融领域,最重要的高可靠,多副本。