Idea开发Spark直接以yarn-cluster模式提交到Ambari集群的解决方案
一.背景介绍
许多中小型企业使用Ambari去管理自己的大数据集群,以Spark作为主要的计算框架去实现数据的分析。通用的Spark的开发调试流程是往往需要以下流程:
- Idea上进行开发,并使用spark local模式进行调试。
- 打包程序放到测试分布式环境上进行spark on yarn client模式进行调试。
- 使用spark on yarn cluster模式进行调试,成功后在正式环境中进行分布式的测试和部署。
有时候由于分布式和本地模式的差异,许多错误在分布式环境中才得以体现。但是在分布式的环境中进行测试,需要反复的打包、部署、提交、测试bug和修改源码。这个过程可能迭代很多次,浪费了大量时间。如果能够在Idea开发的时候就能够提交到分布式环境,将大大减少测试的工作量。本文讲述如何在Idea开发环境中直接以spark on yarn client的模式将代码提交到Ambari集群中。
二.集群环境
- Ambari版本2.2.2.18
- HDP-2.4.2.0-258(Hadoop2.7.1 Spark1.6.3)
因资源限制,版本相对较老,后续会增加新版本Ambari和HDP的测试,但是原理应该是相通的。
三.部署步骤:
1.修改本地的Hadoop环境
windows本地环境需要注意设置HADOOP_HOME并且保持与Ambari集群的Hadoop版本一致。比如我们使用的是Hadoop2.7.1,在windows本地设置HADOOP_HOME路径,文件夹里面包含bin子文件夹,里面需要包含hadoop.dll、winutil.exe等部分必备依赖。如下图所示:
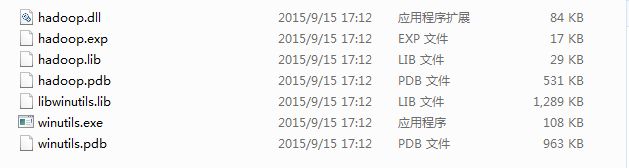
版本不一致,则可能触发org.apache.hadoop.io.nativeio.nativeio$windows.createdirectorywithmode0类的错误。具体操作可以总结为以下步骤:
- 将HADOOP_HOME文件夹在系统环境变量中设置好
- 将PATH指向${HADOOP_HOME}/bin目录,目录中需包含上图的依赖
- 将hadoop.dll拷贝到windows\system32系统目录下。
2.修改Idea开发实例
1.IDEA里修改开发源码和参数
val conf = new SparkConf().setMaster("yarn-client").setAppName("YarnTest")
conf.set("spark.driver.extraJavaOptions","-Dhdp.version=2.4.2.0-258")
conf.set("spark.yarn.am.extraJavaOptions","-Dhdp.version=2.4.2.0-258")
val sc = new SparkContext(conf)
val hiveContext = new HiveContext(sc)在setMaster的参数里面直接指定“yarn-client”模式,在conf里面设置
"spark.driver.extraJavaOptions","-Dhdp.version=2.4.2.0-258"
"spark.yarn.am.extraJavaOptions","-Dhdp.version=2.4.2.0-258"
这两个参数,指向Ambari集群的HDP具体版本。
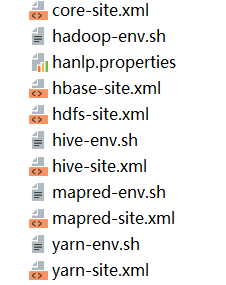
2.idea的环境变量中增加Ambari集群的配置文件,按照需要添加如下
3.pom的依赖中需要增加spark-yarn_2.10
org.apache.spark
spark-yarn_2.10
1.6.3
4.需要修改mapreduce-site文件中的${hdp.version}为实际的版本号
2.4.2.0-258
5.修改mapreduce-site.xml文件里的topology_script.py项,直接去掉
四.其他问题
1.derby的版本不兼容的问题
测试中遇到如下问题:
Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.apache.derby.jdbc.EmbeddedDriver
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient解决方法为更换derby的依赖包,直接从HDP集群拷贝的依赖包版本高于测试环境,使用如下脚本检查derby依赖:
find /usr/hdp/ -name "*.jar" -exec sh -c 'jar -tf {}|grep -H --label {} 'org.apache.derby.jdbc.EmbeddedDriver'' \;发现依赖低版本的derby,于是删除HDP的derby-10.10.2.0.jar包,从pom内增加低版本的derby依赖
org.apache.derby
derby
10.10.1.1
test
2.spark assembly依赖问题
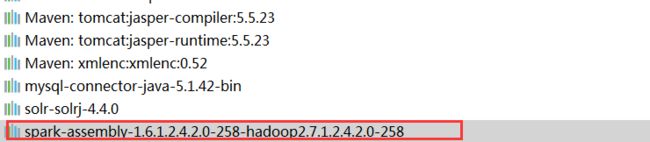
Could not find or load main class org.apache.spark.deploy.yarn.ExecutorLauncher这个问题通过查找源码发现此类位于spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar
从集群中(一般在/usr/hdp/${HDP.VERSION}/spark/lib)目录下拷贝,并且添加到idea的依赖中去即可
五.结束语
通过以上的配置改造,已经可以实现spark Idea开发直接基于分布式集群进行代码测试和运行,极大地减少了spark分布式开发的工作量。如果读者有任何问题,也欢迎留言与我沟通。