【论文翻译】GCNv2: Efficient Correspondence Prediction for Real-Time SLAM
论文原文(注意,这里作者一开始就给的orb-slam的图有问题,实际系统的特征点采集是做了分布式检测的)
源码
他人分享的阅读笔记(总结比较好)
GCN的论文翻译
摘要
以GCN一样是生成关键点及其描述子。在用于3D投影几何的GCN网络基础之上,设计了二进制的描述子(v1中写的要实现的)以便替换ORB-SLAM中的ORB特征点。并且算力效率上也比GCN(只能运行在台式机的硬件上,比如GPU)高,可以运行在TX2上。将ORB用GCNv2提出的特征替换,并且在TX2上运行,结果显示精度和GCN一样,但是对于无人机的控制更加鲁邦(应该是指无人机的控制对kp的提取与描述子的生成产生的不良影响降低了)
(ps:根据目前复现的程度来看,精度的提升并不明显,可能只是对实际SLAM的鲁棒性有提升)
Introduction
主要的贡献点
(1)GCNv2保持了GCN的精度,与当前的基于学习方法和经典方法的特征提取相比有较大改进
(2)GCN的前推可运行在低算力的平台上,比如TX2,而GCN的实时前推需要台式机的GPU
(3)GCNv2的描述子和ORB一样是二进制的,减小了匹配的计算量,提高了效率,而且方便替换其他SLAM系统的子模块,比如ORB-SLAM2或者SVO
(4)通过在真实的无人机上运行GCN-SLAM证实了GCNv2的有效性和鲁棒性,并且显示了其可以处理ORB-SLAM2失败的情况。
GCN
A. 网络结构
最初的GCN网络是由ResNet-50和双向循环网络实现的(RBNN的简单理解)。CNN是实现稠密特征提取的,BRNN是在空间信息的基础上加入时间信息的。该结构已经实现了很好的精度,但是无法实时。一方面,该网络结构本身需要大算力的平台支持,而且,双向结构需要同时对两个或多个frame进行匹配,但是KF会基于当前相机位姿进行动态更新,这进一步增加了计算量。
受SuperPoint只对单个帧进行检测的启发,作者新设计的网络对一张原始图像这种的每个cell(大小为16x16像素)进行独立的预测。(这样和ORB-SLAM中的ORB提取一样,可以使得最终提出的特征点均匀分布在图像中)在GNCv2中,所有的池化层都被改为kernel大小为4x4,步长为2,padding为1的卷积层。网络输入的图像尺寸是320x240。
GCN-SLAM在TX2上可以以20Hz运行,在Intel i7-7700HQ和NVIDIA 1070上可以以大约80Hz运行。GCNv2-tiny是较小版本的GCNv2,从第二层开始,feature map的数量被减小了一半。采用GCNv2-tiny的GCN-SLAM可以在TX2上以40Hz运行。
(ORB-SLAM中台式机上特征提取大概30多ms,可以达到30fps,构图部分大概380ms—460ms,但是前段和后端独立运行)
B. 特征提取
二进制的描述子
在网络输出的特征向量之后再加上一层,二值响应层。然后设计其误差反向传递的函数。
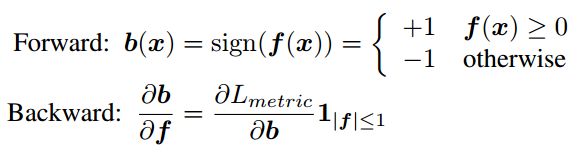
where x = (u; v) is the 2D coordinates in the image and f(·) is the feature vector at a given location. Lmetric is the loss for metric learning. 1 is the indicator function.
这种方法比让网络直接输出二进制的描述子训练起来更加高效。如果直接输出二进制的值,即使得输出在{+1,-1}两个值周围聚类,会与之后的度量学习冲突,因为度量学习需要用到距离信息来划分相似与否。这样整个网络的训练会不稳定。
特征 map f的大小为256,使得其和ORB特征具有相同的位,方便其整合到基于ORB的视觉跟踪系统中。
内嵌的度量学习
像素级的度量学习被用于以最近邻的方式来训练描述子。二进制特征的triplet的loss如下:
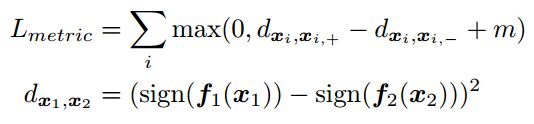

其中,m是截断的距离余量,d等价于对32字节(256位)描述子的平方hanming 距离。用平方距离可以加速收敛(是否是因为不会在正负之间条件,那么绝对值也就是一范数呢?)。
正样本的选取是通过ground truth warp到。负样本是通过mining算法得到的。

对前一帧的特征点xi,在第二帧行选择与其匹配的距离最近(前k个匹配)的k个点,分别检测xi与这k个点的距离,如果超过设定的阈值c(分为u和v两个方向,两个方向都得超过),那么该点就是负样本点,返回输出。
C. 分布式关键点检测器(检测出的kp比orb-slam2分布更加均匀)
训练loss仍然和GCN一样,仍然是对连续的两帧进行操作。
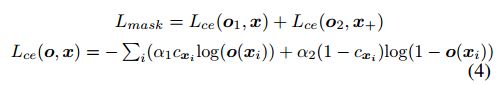
与SuperPoint不同之处是GCNv2的目的是运动估计,而SuperPoint试图实现像SIFT一样的角点检测,其性能主要得益于其优异的描述子(在本文中,用到了实际位姿R和t,而后者只用了单应性矩阵H)。然而CNN能够以比传统方法更大的感受野来提取有代表性的特征。因此,作者通过在16x16的grid中检测Shi-Tomasi 角点(所以这里用的传统方法检测出的kp作为groundtruth,可能也会对网络的效果有好或者坏的影响)并将其warp到下一张图来生成ground truth。这使得关键点分布得更好(主要是划分grid),并且目标函数直接反映了跟踪基于纹理的关键点的能力。
D.训练细节
式(2)中的三重态损耗和式(4)中的交叉熵加权分别为100,1 .在训练期间对两项进行粗略归一化。用于训练的自适应梯度下降法ADAM[41]的学习率从10 e- 4开始,每40个周期减半,共100个训练周期。GCNv2的权重可以随机初始化。将平方汉明距离映射到L2单位圆进行快速最近邻匹配。Triplet损失的margin设置为1.两个平衡权重α1; α2是0.1,1.0。
GCN-SLAM
将GCNv2整合到ORB-SLAM2中,组成一个GCN-SLAM系统。
在GCNv2中,我们向网络输入一个单一的灰度图像帧,该帧输出两个矩阵:一个1×320×240的关键点掩码和一个256×320×240的特征描述符矩阵。对关键字掩码进行阈值处理,以获得一组关键字位置、它们的置信度以及对应的256位特征描述子。与[5]一样,我们对网格大小为8×8的NMS。由于无法知道检测到的特征的方向,我们将角度设置为零。

最后,我们完整地保留了ORB-SLAM2的闭环和位姿图优化,除了通过在V-A节中提供的训练数据集中计算bow以适应GCNv2特征描述符之外。
实验
目的不是测试其优于ORB-SLAM2,而是:
1)更适合高精度的运动估计
2)计算上更高效
3)更鲁邦
A.训练数据
自己做的数据SUN-3D [43] dataset
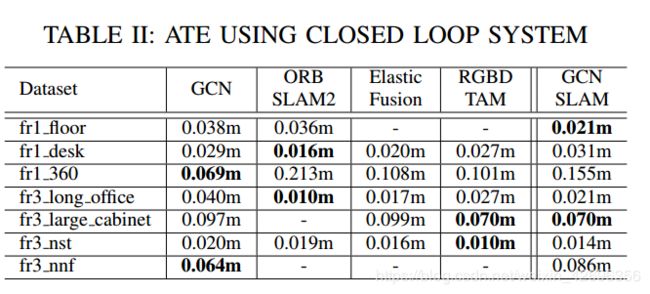
B.定量结果
采用绝对估计误差(ATE)作为标准,结果如下:
不带闭环:

不带闭环:
C.定性结果
这一结果主要是验证GCNv2的鲁棒性。
GCN比ORB更加稳定,轨迹波动小,而且在ORB丢失的地方GCN实现了很好的跟踪:
可是ORB为啥漂的那么厉害,不应该啊......
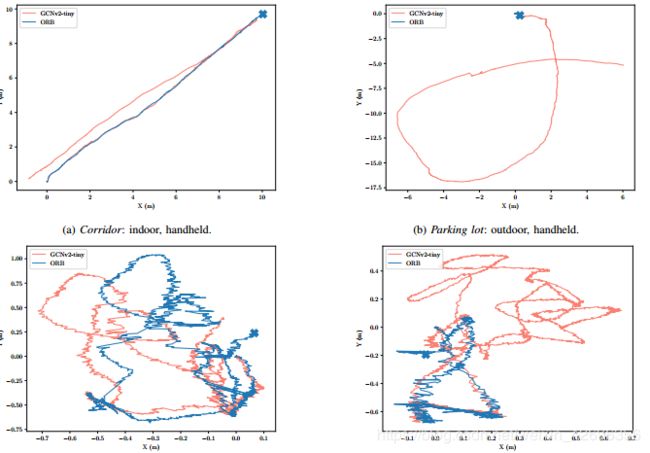
其次,GCN提取的kp中inliers占比比ORB多,而且分布更加均匀

最后,就是利用GCN提取的点来重构场景,结果如下:

总结
局限:只是对重投影几何训练,并没有对一般的特征匹配进行训练(这种可以直接利用DL进行场景的匹配来是实现回环重定位),只是对室内进行了测试,并没有进行室外的测试
改进:使用自监督学习,进一步改进系统
参考
https://blog.csdn.net/wangyangzhizhou/article/details/79798087
https://blog.csdn.net/xw20084898/article/details/21180729
https://blog.csdn.net/cshilin/article/details/52107580