You Look Only Once——YOLO v1
YOLO-v1:you look only once
文章目录
- YOLO-v1:you look only once
- 简介
- 名词解释
- 原理分析
- training
- 网络结构
- test time
简介
YOLO(you look only once)是CVPR2016的一篇文章,广泛运用于工业界,yolo的优点不在于精度,而在于速度。
- 与RCNN系的对比
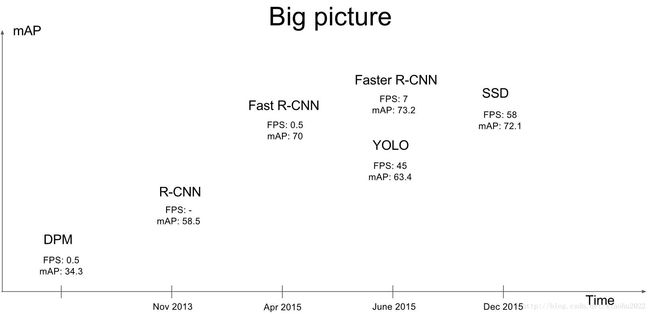
RCNN系:two-stage。先找到Region Proposal,然后分类或回归。准确度高但速度慢。
YOLO系:one-stage。只使用一个CNN网络直接预测不同目标的位置和类别。速度更快但准确率稍低。
- YOLO的主要特点
- 速度快
- 使用全图,背景错误比较少
- 泛化能力强
- YOLO的核心思想
用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
名词解释
- mAP: mean Average Precision, 即各类别AP的平均值
- AP: PR曲线下面积
- PR曲线: Precision-Recall曲线
- Precision: TP / (TP + FP)
- Recall: TP / (TP + FN)
- TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)
- FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
- FN: 没有检测到的GT的数量
原理分析
training
相较于RCNN来说,YOLO是一个同一的框架,速度更快,是end-to-end的。

- 大致流程
- 将图片resize到488*488
- 送入CNN网络
- 非极大值抑制去重
- 具体分析
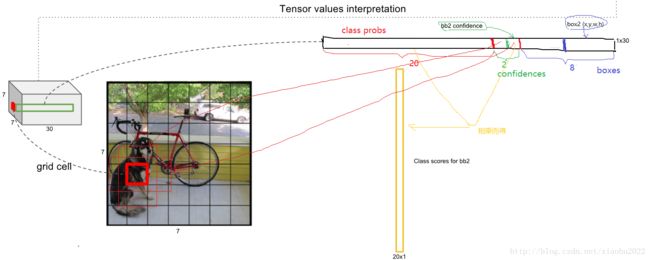
yolo首先将图像分割成S*S个grid(默认为7),对每个grid预测B个bounding box和confidence(默认为2),其中
c o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h confidence=Pr(Object)*IOU^{truth}_{pred} confidence=Pr(Object)∗IOUpredtruth
P r ( O b j e c t ) = { 0 ,grid中不存在物体 1 ,grid中存在物体 Pr(Object)=\begin{cases}0&\text{,grid中不存在物体}\\1&\text{,grid中存在物体}\end{cases} Pr(Object)={01,grid中不存在物体,grid中存在物体
由上述两个公式我们可以看出,存在物体时confidence为IOU值,否则为0。bounding box的表示与RCNN一致。
同时每个grid预测C个类别的概率,训练时产生S*S*(B*5+C)个参数的张量。
网络结构
网络结构参考GooleNet,都使用了1*1的卷积核压缩信息,构造非线性的特征。但是并未使用Inception Module。

- 预训练
在ImageNet上预训练,尺寸为224*224,然后放大为448*448。
- 激活函数
最后一层的激活函数时线性激活函数,其它层则使用leaky ReLU:
ϕ ( x ) = { x ,x>0 0.1 x ,otherwise \phi(x)=\begin{cases}x&\text{,x>0}\\0.1x&\text{,otherwise} \end{cases} ϕ(x)={x0.1x,x>0,otherwise
- 损失函数
传统的均方误差在这里效果并不好:
- bbox的维度和class预测向量的维度不同,显然不应该平权。
- 对于背景box,confidence为0,这会导致网络不稳定,甚至发散。
论文采用的方法是加权处理,即对bbox和confidence施加不同的权重。
- bbox预测赋予 λ c o o r d = 5 \lambda_{coord}=5 λcoord=5
- 对于背景box,confidence的损失为 λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5
- 有object的box,loss weight=1。
这里仍然有一个问题:尺寸小的bbox的偏移误差相对于尺寸大的bbox的偏移误差来说更难以接受。
这里作者用了一个比较巧妙的方法,将bbox的width和height取平方根,代替原本的width和height。使得发生相同偏移时,尺寸小的bbox反应大。
注:x,y,w,h均已经过归一化处理。

test time
在测试时将confidence和类别概率相乘,即 P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u t h = P r ( C l a s s i ) ∗ I O U p r e d t r u t h Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_i)*IOU^{truth}_{pred} Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth
得到的结果(class-specific confidence)既表征出class的概率,又体现出bbox的准确度。
对得到的分数设置阈值进行过滤,然后执行NMS处理,得到最终检测结果。
reference:
【深度学习YOLO V1】深刻解读YOLO V1(图解)
yoloV1,看过好多篇,这篇感觉讲的最通俗易懂