近期deep learning做图像质量评价(image quality assessment)的论文2
1、On the use of deep learning forblind IQA (DeepBIQ) 2017-8-19
核心思想:features+ SVM (实验在LIVEwild database 失真的数据库)
该论文是值得研究一下的,如果自己在尝试用Deeplearning完成IQA任务时,论文中提到的一些设置是可以去借鉴的。主要是实验在LIVEwild database 失真的数据库,结果很棒!!!
--- 主要的探索了三个选择:
(1)-- 使用不同pre-trained CNN框架提取特征,加上SVM。
包括ImageNet-CNN,Places-CNN,ImageNet+Places-CNN。
(2)-- 如何从whole image中提取image patches以及特征融合和预测分数融合的策略。(不同的网络,输入的image patch大小是不一样的,考虑这点是和上一点相关的)
第一:输入图片的大小,比如ImageNet的输入是224*224,所以你的输入就必须是224*224。但是原始图像的大小不是224*224,就需要对输入图像做剪裁处理,可以直接resize,或者从原始图像中挑一些块出来。
第二:如果是从图像中提取图像块的话,那么块的个数又成为了一个参数。该论文从wholeimage中随机挑选sub-regions,数量范围[5,50]。
第三:获得了输入图像块之后,即可得到featurevector, 如何将这些图像块的featurevector 组合又成了一个新的问题,解决方法有:
featurepooling (min, average, max):将所有sub-regionfeature vectors组合成一个向量,用于表示wholeimage。
featureconcatenation:直接把sub-regions对应的向量连在一起。
predictionpooling:通过预测每一个sub-region的分数,再将这些分数组合起来表示wholeimage的质量分数。(min,average, max)
(3)-- image description usinga fine-tuned CNN
首先训练一个CNN分类网络,可以把image按照quality分成五类。Bad[0,20],Poor[20,40], Fair[40, 60], Good[60, 80], Excellent[80, 100]。用IQA的database训练。得到训练好的CNN网络,用来提取features,用SVM预测。(没搞懂这一步!!!)
////实验部分:
ExperimentI: 直接rescale图像成227*227,提取ImageNet等的FC7层,共4096维特征。PlCC:0.7215
ExperimentII:随机提取227*227的图像块,实验发现,从图像中提取30个图像块,然后将这30个图像块的特征进行average-pool操作。PLCC:0.7938
(特征之间的t-test)
ExperimentIII: fine-tuned CNN: PLCC:0.9082, SROCC: 0.8894
插入一篇论文(DeepSim: Deep similarity for image quality assessment, 2017NC),应该刚好介绍了On the use of Deep learning for blind image quality assessment 这篇论文,有一种思想就是用pretrain-network from imagenet提取features,加上SVM,完成IQA任务。
框架图:
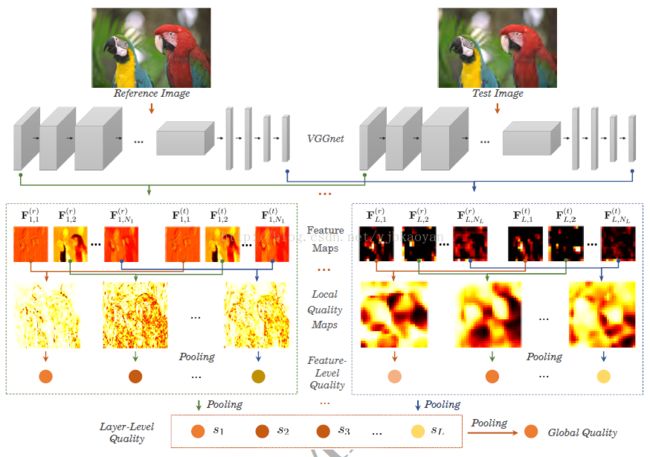
总结是:用VGGnet提features, 计算相似性。
2、2014CVPR Convolutional NeuralNetworks for No-Reference Image Quality Assessment, Le Kang
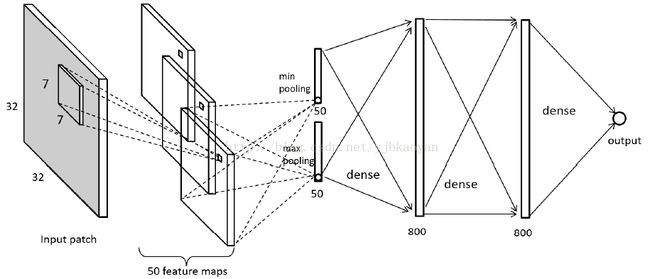
输入的块的大小是32*32,非重叠,块的分数与图像的分数一致,Pooling时,直接将featuremap 变成一个点。
数据的预处理:MSCN操作。并且输入的是灰度图。
激活函数:存在minpooling, 所以在Conv和Pooling层之后均不使用Relu,即不使用激活函数。在两层FC之后使用Relu。
损失函数:L1范式。在第二层使用Dropout。
训练时:60%train, 20% validation, 20% test。从图像中提取图像块,所以patchsize以及numberof patches 成反比的。如果patchsize越大,numberof patches 越少。所以,实际操作时,块有重复区域。
3、dipIQ: Blind image quality assessment bylearning-to-rank discriminable image pairs. Kede Ma, 2017TIP -- Opinion-unawar。(本人非常喜欢的一个工作,膜拜)
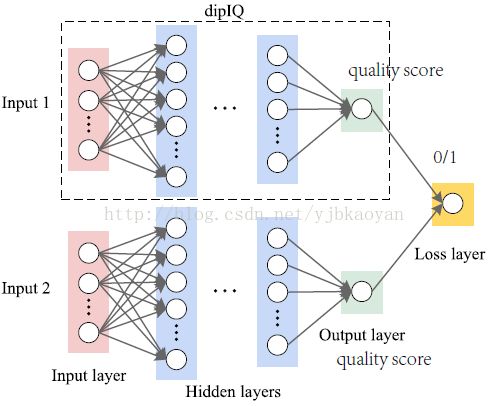
3.2 train_data: 只选了840high quality and high resolution natural images(Waterloo Exploration数据库中有4744张原图,并不是从Waterloo Exploration数据库中挑选的),手工添加了四种失真:JPEG,JP2K,WhiteGaussian noise contamination (WN), and Gaussian blur。每种失真对应五种失真类型。可以得到16800张失真图像。选140张原图像对应的失真图像做Validation,剩余的14700张图像,用来train这个模型。总共可以生成80million(八千万)幅图像对(DIP)。DIP的label通过三种常规的FRIQA方法生成:MS-SSIM,VIF,GMSD。
3.3 图像对(DIP)对应着一个uncertainty 值,指的是如果DIP中两幅图像的差别越大,可分辨的不确定性就越低;如果DIP中两幅图像的差别越小,可分辨的不确定性就越高,越不容易被区分。Uncertainty 值的定义如下:
Uncertainty的取值范围在[0,1];Tc是一个固定值。论文中给出一个固定值,20;原因有两点:第一、LIVE数据库中的MOS的标准差在9左右,不到20的一半;第二、主观实验证明,两个图像的质量分数相差20以上的话,很容易被区分。(不用过于去纠结参数的设置了,写清楚原因即可!),所以,给定DIP,可以得到他们之间的差异值(Which is equal tothe smallest score difference of the three FR models),三种FR方法算出的分数,经过逻辑回归得到与LIVE数据库中MOS同一尺度的分数范围,计算三个分数的最小差异值,赋值给T,就可以计算得到U(T)。
3.4 训练时,Framework的两路权重设置为共享。Loss设置为:
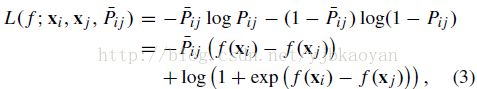

加入了Uncertainty值在LossFunction里面。
Batch size : 512, learn rate:0.0001。
3.5 dipIQ损失函数的理解: (Pi,j上面一棒)为groundtruth, (Pi,j)为预测值。 f(Xi)和f(Xj)分别为dipIQ第一路和第二路的输出。两个输出的差异可以转化成一个概率函数表达式,如下:

该函数表达式,其实就是Sigmoid函数。 (Pi,j)则可理解为image i质量比image j质量好的概率值。(Pi,j) 低于0.5,(Pi,j)表示j质量好的概率更大;(Pi,j) 大于0.5,表示i质量好的概率更大。所以,用交叉熵来定义损失函数。
3.6 实验的具体细节:Specially,the training is carried out by optimizing the cross entropy function usingmini-batch gradient descent with momentum, The weights of the two streams inRankNet are shared. The batch size is set to 512, and momentum to 0.9. Thetraining is regularized by weight decay. The learning rate is fixed to 10^-4. Sincewe have a plenty of DIPs (more than 80 million) for training, each DIP isexposed to the learning algorithm once and only once. The learning stops whenthe entire set of DIPs have been swept. The weights that achieve the lowestvalidation set loss are used for testing.
3.7 实验时,只考虑四个所用数据库中都存在的失真类型。论文只给出了一个全连接网络,20000-256-128-3-1。每次给定DIP的时候,DIP中两张图像分别输入两个网络中(权重共享),可以得到一个测试值,反向传播时,Loss用的是两者的差异groundtruth(0/1),以及差异所所得的uncertainty值。