Flink 如何保存状态数据
[部分译自]
- https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/state_backends.html
- https://towardsdatascience.com/heres-how-flink-stores-your-state-7b37fbb60e1a
[部分参考]
- https://www.infoq.cn/article/WkGozMQQExq6Xm5eJl1E
- https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh
[部分原创]
文章目录
- 一. State 存储方式
- 1.1 MemoryStateBackend
- 1.2 FsStateBackend
- 1.3 RocksDBStateBackend
- 二. Keyed State & Operator State
- 2.1 state 分类
- 2.2 使用 managed keyed state
- 如何创建
- 给 keyed state 设置过期时间
- state 的 TTL 何时被更新?
- 当 state 过期但是还未删除时,这个状态是否还可见?
- 过期的 state 何时被删除?
- 1. 从全量快照恢复时删除
- 2. 后台程序删除(flink-1.8 之后的版本支持)
- 2.3 使用 managed operator state
- CheckpointedFunction
- ListCheckpointed
- OperatorState 示例:实现带状态的 Sink Function
- OperatorState 示例:实现带状态的 Source Function
- 2.4 statebackend 如何保存 managed keyed/operator state
- 三. 配置 state backend
- 3.1 Per-job 设置
- 3.2 默认设置
- 四. 开启 checkpoint
- 五. state 文件格式
Flink 的一个重要特性就是有状态计算(stateful processing)。Flink 提供了简单易用的 API 来存储和获取状态。但是,我们还是要理解 API 背后的原理,才能更好的使用。本文分为 3 个部分:
- Flink支持的三种 State Backend
- state 文件格式
- state 持久化及故障恢复
我们首先看下 state 究竟存储在哪里。
一. State 存储方式
Flink 为 state 提供了三种开箱即用的后端存储方式(state backend):
- Memory State Backend
- File System (FS) State Backend
- RocksDB State Backend
1.1 MemoryStateBackend
MemoryStateBackend 将工作状态数据保存在 taskmanager 的 java 内存中。key/value 状态和 window 算子使用哈希表存储数值和触发器。进行快照时(checkpointing),生成的快照数据将和 checkpoint ACK 消息一起发送给 jobmanager,jobmanager 将收到的所有快照保存在 java 内存中。
MemoryStateBackend 现在被默认配置成异步的,这样避免阻塞主线程的 pipline 处理。
MemoryStateBackend 的状态存取的速度都非常快,但是不适合在生产环境中使用。这是因为 MemoryStateBackend 有以下限制:
- 每个 state 的默认大小被限制为 5 MB(这个值可以通过 MemoryStateBackend 构造函数设置)
- 每个 task 的所有 state 数据 (一个 task 可能包含一个 pipline 中的多个 Operator) 大小不能超过 RPC 系统的帧大小(akka.framesize,默认 10MB)
- jobmanager 收到的 state 数据总和不能超过 jobmanager 内存
MemoryStateBackend 适合的场景:
- 本地开发和调试
- 状态很小的作业
下图表示了 MemoryStateBackend 的数据存储位置:
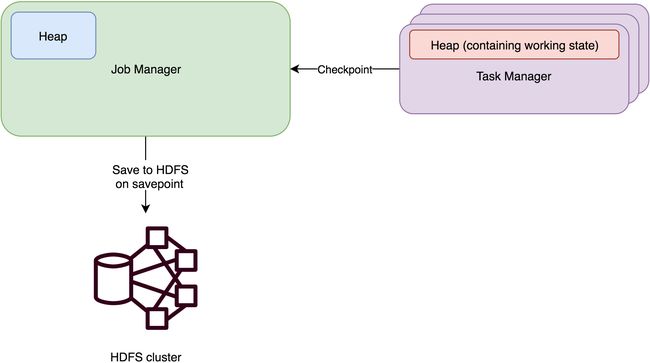
值得说明的是,当触发 savepoint 时,jobmanager 会把快照数据持久化到外部存储。
1.2 FsStateBackend
FsStateBackend 需要配置一个 checkpoint 路径,例如“hdfs://namenode:40010/flink/checkpoints” 或者 “file:///data/flink/checkpoints”,我们一般配置为 hdfs 目录
FsStateBackend 将工作状态数据保存在 taskmanager 的 java 内存中。进行快照时,再将快照数据写入上面配置的路径,然后将写入的文件路径告知 jobmanager。jobmanager 中保存所有状态的元数据信息(在 HA 模式下,元数据会写入 checkpoint 目录)。
FsStateBackend 默认使用异步方式进行快照,防止阻塞主线程的 pipline 处理。可以通过 FsStateBackend 构造函数取消该模式:
new FsStateBackend(path, false);
FsStateBackend 适合的场景:
- 大状态、长窗口、大键值(键或者值很大)状态的作业
- 适合高可用方案
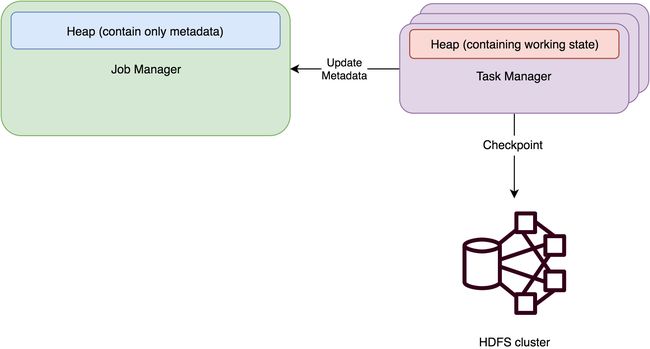
1.3 RocksDBStateBackend
RocksDBStateBackend 也需要配置一个 checkpoint 路径,例如:“hdfs://namenode:40010/flink/checkpoints” 或者 “file:///data/flink/checkpoints”,一般配置为 hdfs 路径。
RocksDB 是一种可嵌入的持久型的 key-value 存储引擎,提供 ACID 支持。由 Facebook 基于 levelDB 开发,使用 LSM 存储引擎,是内存和磁盘混合存储。
RocksDBStateBackend 将工作状态保存在 taskmanager 的 RocksDB 数据库中;checkpoint 时,RocksDB 中的所有数据会被传输到配置的文件目录,少量元数据信息保存在 jobmanager 内存中( HA 模式下,会保存在 checkpoint 目录)。
RocksDBStateBackend 使用异步方式进行快照。
RocksDBStateBackend 的限制:
- 由于 RocksDB 的 JNI bridge API 是基于 byte[] 的,RocksDBStateBackend 支持的每个 key 或者每个 value 的最大值不超过 2^31 bytes((2GB))。
- 要注意的是,有 merge 操作的状态(例如 ListState),可能会在运行过程中超过 2^31 bytes,导致程序失败。
RocksDBStateBackend 适用于以下场景:
- 超大状态、超长窗口(天)、大键值状态的作业
- 适合高可用模式
使用 RocksDBStateBackend 时,能够限制状态大小的是 taskmanager 磁盘空间(相对于 FsStateBackend 状态大小限制于 taskmanager 内存 )。这也导致 RocksDBStateBackend 的吞吐比其他两个要低一些。因为 RocksDB 的状态数据的读写都要经过反序列化/序列化。
RocksDBStateBackend 是目前三者中唯一支持增量 checkpoint 的。

二. Keyed State & Operator State
2.1 state 分类
如果我们查看 flink官方文档,可以发现 flink 将 state 分成了两大类:
- Operator State (或者non-keyed state )
每个 Operator state 绑定一个并行 Operator 实例。Kafka Connector 是使用 Operator state 的典型示例:每个并行的 kafka consumer 实例维护了每个 kafka topic 分区和该分区 offset 的映射关系,并将这个映射关系保存为 Operator state。
在算子并行度改变时,Operator State 也会重新分配。 - Keyed State
这种 State 只存在于 KeyedStream 上的函数和操作中,比如 Keyed UDF(KeyedProcessFunction…) window state 。可以把 Keyed State 想象成被分区的 Operator State。每个 Keyed State 在逻辑上可以看成与一个
每个 Keyed State 在逻辑上还会被分配到一个 Key Group。分配方法如下:
// maxParallelism 为最大并行度
MathUtils.murmurHash(key.hashCode()) % maxParallelism;
其中 maxParallelism 是 flink 程序的最大并行度,这个值一般我们不会去手动设置,使用默认的值(128)就好,这里注意下,maxParallelism 和我们运行程序时指定的算子并行度(parallelism)不同,parallelism 不能大于 maxParallelism ,parallelism 最多只能设置为 maxParallelism 。
为什么会有 Key Group 这个概念呢?举个栗子,我们通常写程序,会给算子指定一个并行度,运行一段时间后,积累了一些 state ,这时候数据量大了,需要增大并行度;我们修改并行度后重新提交,那这些已经存在的 state 该如何分配到各个 Operator 呢?这就有了最大并行度(maxParallelism ) 和 Key Group 的概念。上面计算 Key Group 的公式也说明了 Key Group 的个数最多是 maxParallelism 个。当并行度更改后,我们再计算这个 key 被分配到的 Operator:
keyGroupId * parallelism / maxParallelism;
可以看到, 一个 keyGroupId 会对应到一个 Operator,当并行度更改时,新的 Operator 会去拉取对应 Key Group 的 Keyed State,这样就把 KeyedState 尽量均匀地分配给所有的 Operator 啦!
根据 state 数据是否被 flink 托管,flink 又将 state 分类为 managed state 和 raw state:
- managed state: 被 flink 托管,保存为内部的哈希表或者 RocksDB; checkpoint 时,flink 将 state 进行序列化编码。例如 ValueState ListState…
- raw state: Operator 自行管理的数据结构,checkpoint 时,它们只能以 byte 数组写入 checkpoint。
当然建议使用 managed state 啦!使用 managed state 时, flink 会帮我们在更改并行度时重新分发 state,并且优化内存。
2.2 使用 managed keyed state
如何创建
上面提到,Keyed state 只能在 keyedStream 上使用,可以通过 stream.keyBy(…) 创建 keyedStream。我们可以创建以下几种 keyed state:
- ValueState
- ListState
- ReducingState
- AggregatingState
- MapState
- FoldingState
每种 state 都对应各自的描述符,通过描述符从 RuntimeContext 中获取对应的 State,而 RuntimeContext 只有 RichFunction 才能获取,所以要想使用 keyed state,用户编写的类必须继承 RichFunction 或者其子类。
- ValueState
getState(ValueStateDescriptor ) - ReducingState
getReducingState(ReducingStateDescriptor ) - ListState
getListState(ListStateDescriptor ) - AggregatingState
- FoldingState
- MapState
下文示例中 StatefulProcess.java 和 StatefulMapTest.java 是两个使用 managed keyed state 的例子。
给 keyed state 设置过期时间
flink-1.6.0 以后,我们还可以给 Keyed state 设置 TTL(Time-To-Live),当某一个 key 的 state 数据过期时,会被 statebackend 尽力删除。
官方给出了使用示例:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1)) // 状态存活时间
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // TTL 何时被更新,这里配置的 state 创建和写入时
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();// 设置过期的 state 不被读取
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
简单来说就是在创建状态描述符时,添加 StateTtlConfig 配置,
state 的 TTL 何时被更新?
可以进行以下配置,默认只在 key 的 state 被 modify(创建或更新) 的时候才更新 TTL:
- StateTtlConfig.UpdateType.OnCreateAndWrite: 只在一个 key 的 state 创建和写入时更新 TTL(默认)
- StateTtlConfig.UpdateType.OnReadAndWrite: 读取 state 时仍然更新 TTL
当 state 过期但是还未删除时,这个状态是否还可见?
可以进行以下配置,默认是不可见的:
- StateTtlConfig.StateVisibility.NeverReturnExpired: 不可见(默认)
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp: 可见
注意:
- 状态的最新访问时间会和状态数据保存在一起,所以开启 TTL 特性会增大 state 的大小。Heap state backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,RocksDB state backend 会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节。
- 暂时只支持基于 processing time 的 TTL。
- 尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,否则会遇到 “StateMigrationException”。
- TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效。
- 当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null。如果用户值序列化器不支持 null, 可以用 NullableSerializer 包装一层。
过期的 state 何时被删除?
默认情况下,过期的 state 数据只有被显示读取的时候才会被删除,例如,调用 ValueState.value() 时。
注意:如果过期的数据如果之后不被读取,那么这个过期数据就不会被删除,可能导致状态不断增大。目前有两种方式解决这个问题:
1. 从全量快照恢复时删除
可以配置从全量快照恢复时删除过期数据:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1)) // state 存活时间,这里设置的 1 秒过期
.cleanupFullSnapshot()
.build();
局限是正常运行的程序的过期状态还是无法删除,全量快照时,过期状态还是被备份了,只是在从上一个快照恢复时会过滤掉过期数据。
- 注意:使用 RocksDB 增量快照时,该配置无效。
- 这种清理方式可以在任何时候通过 StateTtlConfig 启用或者关闭,比如在从 savepoint 恢复时。
2. 后台程序删除(flink-1.8 之后的版本支持)
flink-1.8 引入了后台清理过期 state 的特性,通过 StateTtlConfig 开启,显式调用 cleanupInBackground(),使用示例如下:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1)) // state 存活时间,这里设置的 1 秒过期
.cleanupInBackground()
.build();
官方介绍,使用 cleanupInBackground() 时,可以让不同 statebackend 自动选择 cleanupIncrementally(heap state backend) 或者 cleanupInRocksdbCompactFilter(rocksdb state backend) 策略进行后台清理。也就是说,不同的 statebackend 的具体清理过期 state 原理也是不一样的。而且,配置为 cleanupInBackground() 时,只能使用默认配置的参数。想要更改参数时,需要显式配置上面提到的两种清理方式,并且要和 statebackend 对应:
- heap state backend 支持的增量清理
在状态访问或处理时进行。如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器。 每次触发增量清理时,从迭代器中选择已经过期的进行清理。通过 StateTtlConfig 配置,显式调用 cleanupIncrementally():
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build();
使用 cleanupIncrementally() 策略时,当 state 被访问时会触发清理逻辑。
cleanupIncrementally() 包含两个参数:第一个参数表示每次清理被触发时,要检查的 state 条目个数;第二个参数表示是否在每条数据被处理时都触发清理逻辑。如果使用 cleanupInBackground() 的话,这里的默认值是(5, false)。
还有以下几点需要注意:
a. 如果没有 state 访问,也没有处理数据,则不会清理过期数据。
b. 增量清理会增加数据处理的耗时。
c. 现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
d. 如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,从而防止并发修改问题,因此会增加内存的使用。但异步快照则没有这个问题。
e. 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
- RocksDB 进行 compaction(压缩合并) 时清理
如果使用 RocksDB state backend,可以使用 Flink 为 RocksDB 定制的 compaction filter。RocksDB 会周期性的对数据进行异步合并压缩从而减少存储空间。 Flink 压缩过滤器会在压缩时过滤掉已经过期的状态数据。
该特性默认是关闭的,可以通过 Flink 的配置项 state.backend.rocksdb.ttl.compaction.filter.enabled 或者调用 RocksDBStateBackend::enableTtlCompactionFilter 启用该特性。然后通过如下方式让任何具有 TTL 配置的状态使用过滤器:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();
使用这种策略需要注意:
a. 压缩时调用 TTL 过滤器会降低速度。TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。 对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查。
b. 对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器, 从而确定下一个未过期数据的位置。
c. 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
2.3 使用 managed operator state
我们可以通过实现 CheckpointedFunction 或 ListCheckpointed 接口来使用 managed operator state。
CheckpointedFunction
CheckpointedFunction 接口提供了访问 non-keyed state 的方法,需要实现如下两个方法:
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;
进行 checkpoint 时会调用 snapshotState()。 用户自定义函数初始化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复。 因此 initializeState() 不仅是定义不同状态类型初始化的地方,也需要包括状态恢复的逻辑。
当前,managed operator state 以 list 的形式存在。这些状态是一个 可序列化 对象的集合 List,彼此独立,方便在改变并发后进行状态的重新分派。 换句话说,这些对象是重新分配 non-keyed state 的最细粒度。根据状态的不同访问方式,有如下几种重新分配的模式:
-
Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成。当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。 比如说,算子 A 的并发读为 1,包含两个元素 element1 和 element2,当并发读增加为 2 时,element1 会被分到并发 0 上,element2 则会被分到并发 1 上。
-
Union redistribution: 每个算子保存一个列表形式的状态集合。整个状态由所有的列表拼接而成。当作业恢复或重新分配时,每个算子都将获得所有的状态数据。
ListCheckpointed
ListCheckpointed 接口是 CheckpointedFunction 的精简版,仅支持 even-split redistributuion 的 list state。同样需要实现两个方法:
List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
void restoreState(List<T> state) throws Exception;
snapshotState() 需要返回一个将写入到 checkpoint 的对象列表,restoreState 则需要处理恢复回来的对象列表。如果状态不可切分, 则可以在 snapshotState() 中返回 Collections.singletonList(MY_STATE)。
OperatorState 示例:实现带状态的 Sink Function
下面的例子中的 SinkFunction 在 CheckpointedFunction 中进行数据缓存,然后统一发送到下游,这个例子演示了列表状态数据的 event-split redistribution。
public class BufferingSink
implements SinkFunction<Tuple2<String, Integer>>,
CheckpointedFunction {
// 发送阈值
private final int threshold;
// 定义状态,只能是 ListState
private transient ListState<Tuple2<String, Integer>> checkpointedState;
// 局部变量,保存最新的数据
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
// 实现 SinkFunction 接口,每个元素都会调用一次该函数
@Override
public void invoke(Tuple2<String, Integer> value, Context contex) throws Exception {
// 把数据加入局部变量中
bufferedElements.add(value);
// 达到阈值啦!快发送
if (bufferedElements.size() == threshold) {
for (Tuple2<String, Integer> element: bufferedElements) {
// 这里实现发送逻辑
}
// 发送完注意清空缓存
bufferedElements.clear();
}
}
// checkpoint 时会调用 snapshotState() 函数
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// 清空 ListState,我们要放入最新的数据啦
checkpointedState.clear();
// 把当前局部变量中的所有元素写入到 checkpoint 中
for (Tuple2<String, Integer> element : bufferedElements) {
checkpointedState.add(element);
}
}
// 需要处理第一次自定义函数初始化和从之前的 checkpoint 恢复两种情况
// initializeState 方法接收一个 FunctionInitializationContext 参数,会用来初始化 non-keyed state 的 “容器”。这些容器是一个 ListState, 用于在 checkpoint 时保存 non-keyed state 对象。
// 就是说我们可以通过 FunctionInitializationContext 获取 ListState 状态
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
// StateDescriptor 会包括状态名字、以及状态类型相关信息
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));
// context.getOperatorStateStore().getListState(descriptor) 使用 even-split redistribution 算法
// 我们还可以通过 context.getKeyedStateStore() 获取 keyed state,当然要在 keyedStream 上使用啦!
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
// 需要处理从 checkpoint/savepoint 恢复的情况
// 通过 isRestored() 方法判断是否从之前的故障中恢复回来,如果该方法返回 true 则表示从故障中进行恢复,会执行接下来的恢复逻辑
if (context.isRestored()) {
for (Tuple2<String, Integer> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
OperatorState 示例:实现带状态的 Source Function
带状态的数据源比其他的算子需要注意更多东西。为了保证更新状态以及输出的原子性(用于在失败/恢复时支持 exactly-once 语义),用户需要在发送数据前 获取数据源的全局锁。
public static class CounterSource
extends RichParallelSourceFunction<Long>
implements ListCheckpointed<Long> {
/** current offset for exactly once semantics */
private Long offset = 0L;
/** flag for job cancellation */
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<Long> ctx) {
final Object lock = ctx.getCheckpointLock();
while (isRunning) {
// output and state update are atomic
synchronized (lock) {
ctx.collect(offset);
offset += 1;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
@Override
public List<Long> snapshotState(long checkpointId, long checkpointTimestamp) {
return Collections.singletonList(offset);
}
@Override
public void restoreState(List<Long> state) {
for (Long s : state)
offset = s;
}
}
希望订阅 checkpoint 成功消息的算子,可以参考 org.apache.flink.runtime.state.CheckpointListener 接口。
2.4 statebackend 如何保存 managed keyed/operator state
上面我们详细介绍了三种 statebackend,那么这三种 statebackend 是如何托管 keyed state 和 Operator state 的呢?
参考很多资料并查阅源码后,感觉下面的图能简单明了的表示当前 flink state 的存储方式。
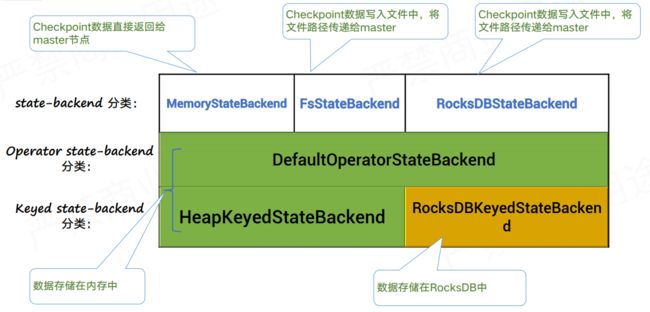
在 flink 的实际实现中,对于同一种 statebackend,不同的 state 在运行时会有细分的 statebackend 托管,例如 MemeoryStateBackend,就有 DefaultOperatorStateBackend 管理 Operator state,HeapKeydStateBackend 管理 Keyed state。我们看到 MemoryStateBackend 和 FsStateBackend 对于 keyed state 和 Operator state 的存储都符合我们之前的理解,运行时 state 数据保存于内存,checkpoint 时分别将数据备份在 jobmanager 内存和磁盘; RocksDBStateBackend 运行时 Operator state 的保存位置需要注意下,并不是保存在 RocksDB 中,而是通过 DefaultOperatorStateBackend 保存在 taskmanager 内存,创建源码如下:
// RocksDBStateBackend.java
// 创建 keyed statebackend
public <K> AbstractKeyedStateBackend<K> createKeyedStateBackend(...){
...
return new RocksDBKeyedStateBackend<>(
...);
}
// 创建 Operator statebackend
public OperatorStateBackend createOperatorStateBackend(
Environment env,
String operatorIdentifier) throws Exception {
//the default for RocksDB; eventually there can be a operator state backend based on RocksDB, too.
final boolean asyncSnapshots = true;
return new DefaultOperatorStateBackend(
...);
}
源码中也标注了,未来会提供基于 RocksDB 存储的 Operator state。所以当前即使使用 RocksDBStateBackend, Operator state 也不能超过内存限制。
Operator State 在内存中对应两种数据结构:
- ListState: 对应的实际实现类为 PartitionableListState,创建并注册的代码如下
// DefaultOperatorStateBackend.java
private <S> ListState<S> getListState(...){
partitionableListState = new PartitionableListState<>(
new RegisteredOperatorStateBackendMetaInfo<>(
name,
partitionStateSerializer,
mode));
registeredOperatorStates.put(name, partitionableListState);
}
PartitionableListState 中通过 ArrayList 来保存 state 数据:
// PartitionableListState.java
/**
* The internal list the holds the elements of the state
*/
private final ArrayList<S> internalList;
- BroadcastState:对应的实际实现类为 HeapBroadcastState,创建并注册的代码如下
public <K, V> BroadcastState<K, V> getBroadcastState(...) {
broadcastState = new HeapBroadcastState<>(
new RegisteredBroadcastStateBackendMetaInfo<>(
name,
OperatorStateHandle.Mode.BROADCAST,
broadcastStateKeySerializer,
broadcastStateValueSerializer));
registeredBroadcastStates.put(name, broadcastState);
}
HeapBroadcastState 中通过 HashMap 来保存 state 数据:
/**
* The internal map the holds the elements of the state.
*/
private final Map<K, V> backingMap;
HeapBroadcastState(RegisteredBroadcastStateBackendMetaInfo<K, V> stateMetaInfo) {
this(stateMetaInfo, new HashMap<>());
}
我们对比下 HeapKeydStateBackend 和 RocksDBKeyedStateBackend 是如何保存 keyed state 的:

对于 HeapKeydStateBackend , state 数据被保存在一个由多层 java Map 嵌套而成的数据结构中。这个图表示的是 window 中的 keyed state 保存方式,而 window-contents 是 flink 中 window 数据的 state 描述符的名称,当然描述符类型是根据实际情况变化的。比如我们经常在 window 后执行聚合操作 (aggregate),flink 就有可能创建一个名字为 window-contents 的 AggregatingStateDescriptor:
// WindowedStream.java
AggregatingStateDescriptor<T, ACC, V> stateDesc = new AggregatingStateDescriptor<>("window-contents", aggregateFunction, accumulatorType.createSerializer(getExecutionEnvironment().getConfig()));
HeadKeyedStateBackend 会通过一个叫 StateTable 的数据结构,查找 key 对应的 StateMap:
// StateTable.java
/**
* Map for holding the actual state objects. The outer array represents the key-groups.
* All array positions will be initialized with an empty state map.
*/
protected final StateMap<K, N, S>[] keyGroupedStateMaps;
根据是否开启异步 checkpoint,StateMap 会分别对应两个实现类:CopyOnWriteStateMap
对于 NestedStateMap,实际存储数据如下:
// NestedStateMap.java
private final Map<N, Map<K, S>> namespaceMap;
CopyOnWriteStateMap 是一个支持 Copy-On-Write 的 StateMap 子类,实际上参考了 HashMap 的实现,它支持渐进式哈希(incremental rehashing) 和异步快照特性。
对于 RocksDBKeyedStateBackend,每个 state 存储在一个单独的 column family 内,KeyGroup、key、namespace 进行序列化存储在 DB 作为 key,状态数据作为 value。

三. 配置 state backend
我们知道 flink 提供了三个 state backend,那么如何配置使用某个 state backend 呢?
默认的配置在 conf/flink-conf.yaml 文件中 state.backend 指定,如果没有配置该值,就会使用 MemoryStateBackend。默认的 state backend 可以被代码中的配置覆盖。
3.1 Per-job 设置
我们可以通过 StreamExecutionEnvironment 设置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
如果想使用 RocksDBStateBackend,你需要将相关依赖加入你的 flink 程序中:
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackend-rocksdb_2.11artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
3.2 默认设置
如果没有在程序中指定,flink 将使用 conf/flink-conf.yaml 文件中的 state.backend 指定的 state backend,这个值有三种配置:
- jobmanager (代表 MemoryStateBackend)
- filesystem (代表 FsStateBackend)
- rocksdb (代表 RocksDBStateBackend)
state.checkpoints.dir 定义了 checkpoint 时,state backend 将快照数据备份的目录
四. 开启 checkpoint
开启 checkpoint 后,state backend 管理的 taskmanager 上的状态数据才会被定期备份到 jobmanager 或 外部存储,这些状态数据在作业失败恢复时会用到。我们可以通过以下代码开启和配置 checkpoint:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.getConfig().disableSysoutLogging();
//每 30 秒触发一次 checkpoint,checkpoint 时间应该远小于(该值 + MinPauseBetweenCheckpoints),否则程序会一直做checkpoint,影响数据处理速度
env.enableCheckpointing(30000); // create a checkpoint every 30 seconds
// set mode to exactly-once (this is the default)
// flink 框架内保证 EXACTLY_ONCE
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// make sure 30 s of progress happen between checkpoints
// 两个 checkpoints之间最少有 30s 间隔(上一个checkpoint完成到下一个checkpoint开始,默认为0,这里建议设置为非0值)
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000);
// checkpoints have to complete within one minute, or are discarded
// checkpoint 超时时间(默认 600 s)
env.getCheckpointConfig().setCheckpointTimeout(600000);
// allow only one checkpoint to be in progress at the same time
// 同时只有一个checkpoint运行(默认)
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// enable externalized checkpoints which are retained after job cancellation
// 取消作业时是否保留 checkpoint (默认不保留)
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// checkpoint失败时 task 是否失败( 默认 true, checkpoint失败时,task会失败)
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);
// 对 FsStateBackend 刷出去的文件进行文件压缩,减小 checkpoint 体积
env.getConfig().setUseSnapshotCompression(true);
FsStateBackend 和 RocksDBStateBackend checkpoint 完成后最终保存到下面的目录:
hdfs:///your/checkpoint/path/{JOB_ID}/chk-{CHECKPOINT_ID}/
JOB_ID 是应用的唯一 ID,CHECKPOINT_ID 是每次 checkpoint 时自增的数字 ID
我们可以从备份的 checkpoint 数据恢复当时的作业状态:
flink-1x.x/bin/flink run -s hdfs:///your/checkpoint/path/{JOB_ID}/chk-{CHECKPOINT_ID}/ path/to//your/jar
我们可以实现 CheckpointedFunction 方法,在程序初始化或者 checkpoint 时修改状态:
public class StatefulProcess extends KeyedProcessFunction<String, KeyValue, KeyValue> implements CheckpointedFunction {
ValueState<Integer> processedInt;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
@Override
public void processElement(KeyValue keyValue, Context context, Collector<KeyValue> collector) throws Exception {
try{
Integer a = Integer.parseInt(keyValue.getValue());
processedInt.update(a);
collector.collect(keyValue);
}catch(Exception e){
e.printStackTrace();
}
}
@Override
public void initializeState(FunctionInitializationContext functionInitializationContext) throws Exception {
processedInt = functionInitializationContext.getKeyedStateStore().getState(new ValueStateDescriptor<>("processedInt", Integer.class));
if(functionInitializationContext.isRestored()){
//Apply logic to restore the data
}
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
processedInt.clear();
}
}
五. state 文件格式
当我们创建 state 时,数据是如何保存的呢?
对于不同的 statebackend,有不同的存储格式。但是都是使用 flink 序列化器,将键值转化为字节数组保存起来。这里使用 RocksDBStateBackend 示例。
每个 taskmanager 会创建多个 RocksDB 目录,每个目录保存一个 RocksDB 数据库;每个数据库包含多个 column famiilies,这些 column families 由 state descriptors 定义。
每个 column family 包含多个 key-value 对,key 是 Operator 的 key, value 是对应的状态数据。
让我们看个例子程序:
// TestFlink.java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
ParameterTool configuration = ParameterTool.fromArgs(args);
FlinkKafkaConsumer010<String> kafkaConsumer010 = new FlinkKafkaConsumer010<String>("test", new SimpleStringSchema(), getKafkaConsumerProperties("testing123"));
DataStream<String> srcStream = env.addSource(kafkaConsumer010);
Random random = new Random();
DataStream<String> outStream = srcStream
.map(row -> new KeyValue("testing" + random.nextInt(100000), row))
.keyBy(row -> row.getKey())
.process(new StatefulProcess()).name("stateful_process").uid("stateful_process")
.keyBy(row -> row.getKey())
.flatMap(new StatefulMapTest()).name("stateful_map_test").uid("stateful_map_test");
outStream.print();
env.execute("Test Job");
}
public static Properties getKafkaConsumerProperties(String groupId){
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092"
);
props.setProperty("group.id", groupId);
return props;
}
这个程序包含两个有状态的算子:
//StatefulMapTest.java
public class StatefulMapTest extends RichFlatMapFunction<KeyValue, String> {
ValueState<Integer> previousInt;
ValueState<Integer> nextInt;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
previousInt = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("previousInt", Integer.class));
nextInt = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("nextInt", Integer.class));
}
@Override
public void flatMap(KeyValue s, Collector<String> collector) throws Exception {
try{
Integer oldInt = Integer.parseInt(s.getValue());
Integer newInt;
if(previousInt.value() == null){
newInt = oldInt;
collector.collect("OLD INT: " + oldInt.toString());
}else{
newInt = oldInt - previousInt.value();
collector.collect("NEW INT: " + newInt.toString());
}
nextInt.update(newInt);
previousInt.update(oldInt);
}catch(Exception e){
e.printStackTrace();
}
}
}
// StatefulProcess.java
public class StatefulProcess extends KeyedProcessFunction<String, KeyValue, KeyValue> {
ValueState<Integer> processedInt;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
processedInt = getRuntimeContext().getState(new ValueStateDescriptor<>("processedInt", Integer.class));
}
@Override
public void processElement(KeyValue keyValue, Context context, Collector<KeyValue> collector) throws Exception {
try{
Integer a = Integer.parseInt(keyValue.getValue());
processedInt.update(a);
collector.collect(keyValue);
}catch(Exception e){
e.printStackTrace();
}
}
}
在 flink-conf.yaml 文件中设置 rocksdb 作为 state backend。每个 taskmanager 将在指定的 tmp 目录下(对于 onyarn 模式,tmp 目录由 yarn 指定,一般为 /path/to/nm-local-dir/usercache/user/appcache/application_xxx/flink-io-xxx),生成下面的目录:
drwxr-xr-x 4 abc 74715970 128B Sep 23 03:19 job_127b2b84f80b368b8edfe02b2762d10d_op_KeyedProcessOperator_0d49016af99997646695a030f69aa7ee__1_1__uuid_65b50444-5857-4940-9f8c-77326cc79279/db
drwxr-xr-x 4 abc 74715970 128B Sep 23 03:20 job_127b2b84f80b368b8edfe02b2762d10d_op_StreamFlatMap_11f49afc24b1cce91c7169b1e5140284__1_1__uuid_19b333d3-3278-4e51-93c8-ac6c3608507c/db
目录名含义如下:
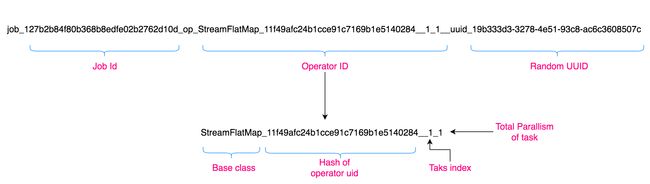
大致分为 3 部分:
- JOB_ID: JobGraph 创建时分配的随机 id
- OPERATOR_ID: 由 4 部分组成, 算子基类_Murmur3(算子 uid)_task索引_task总并行度。对于 StatefulMapTest 这个算子,4 个 部分分别为:
- StreamFlatMap
- Murmur3_128(“stateful_map_test”) -> 11f49afc24b1cce91c7169b1e5140284
- 1,因为总并行度指定了1,所以只有这一个 task
- 1,因为总并行度指定了1
- UUID: 随机的 UUID 值
每个目录都包含一个 RocksDB 实例,其文件结构如下:
-rw-r--r-- 1 abc 74715970 21K Sep 23 03:20 000011.sst
-rw-r--r-- 1 abc 74715970 21K Sep 23 03:20 000012.sst
-rw-r--r-- 1 abc 74715970 0B Sep 23 03:36 000015.log
-rw-r--r-- 1 abc 74715970 16B Sep 23 03:36 CURRENT
-rw-r--r-- 1 abc 74715970 33B Sep 23 03:18 IDENTITY
-rw-r--r-- 1 abc 74715970 0B Sep 23 03:33 LOCK
-rw-r--r-- 1 abc 74715970 34K Sep 23 03:36 LOG
-rw-r--r-- 1 abc 74715970 339B Sep 23 03:36 MANIFEST-000014
-rw-r--r-- 1 abc 74715970 10K Sep 23 03:36 OPTIONS-000017
- .sst 文件是 RocksDB 生成的 SSTable,包含真实的状态数据。
- LOG 文件包含 commit log
- MANIFEST 文件包含元数据信息,例如 column families
- OPTIONS 文件包含创建 RocksDB 实例时使用的配置
我们通过 RocksDB java API 打开这些文件:
//FlinkRocksDb.java
public class FlinkRocksDb {
public static void main(String[] args) throws Exception {
RocksDB.loadLibrary();
String previousIntColumnFamily = "previousInt";
byte[] previousIntColumnFamilyBA = previousIntColumnFamily.getBytes(StandardCharsets.UTF_8);
String nextIntcolumnFamily = "nextInt";
byte[] nextIntcolumnFamilyBA = nextIntcolumnFamily.getBytes(StandardCharsets.UTF_8);
try (final ColumnFamilyOptions cfOpts = new ColumnFamilyOptions().optimizeUniversalStyleCompaction()) {
// list of column family descriptors, first entry must always be default column family
final List<ColumnFamilyDescriptor> cfDescriptors = Arrays.asList(
new ColumnFamilyDescriptor(RocksDB.DEFAULT_COLUMN_FAMILY, cfOpts),
new ColumnFamilyDescriptor(previousIntColumnFamilyBA, cfOpts),
new ColumnFamilyDescriptor(nextIntcolumnFamilyBA, cfOpts)
);
// a list which will hold the handles for the column families once the db is opened
final List<ColumnFamilyHandle> columnFamilyHandleList = new ArrayList<>();
String dbPath = "/Users/abc/job_127b2b84f80b368b8edfe02b2762d10d_op"+
"_StreamFlatMap_11f49afc24b1cce91c7169b1e5140284__1_1__uuid_19b333d3-3278-4e51-93c8-ac6c3608507c/db/";
try (final DBOptions options = new DBOptions()
.setCreateIfMissing(true)
.setCreateMissingColumnFamilies(true);
final RocksDB db = RocksDB.open(options, dbPath, cfDescriptors, columnFamilyHandleList)) {
try {
for(ColumnFamilyHandle columnFamilyHandle : columnFamilyHandleList){
// 有些 rocksdb 版本去除了 getName 这个方法
byte[] name = columnFamilyHandle.getName();
System.out.write(name);
}
}finally {
// NOTE frees the column family handles before freeing the db
for (final ColumnFamilyHandle columnFamilyHandle :
columnFamilyHandleList) {
columnFamilyHandle.close();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
上面的程序将会输出:
default
previousInt
nextInt
我们可以打印出每个 column family 中的键值对:
// RocksdbKVIterator.java
TypeInformation<Integer> resultType = TypeExtractor.createTypeInfo(Integer.class);
TypeSerializer<Integer> serializer = resultType.createSerializer(new ExecutionConfig());
RocksIterator iterator = db.newIterator(columnFamilyHandle);
iterator.seekToFirst();
iterator.status();
while (iterator.isValid()) {
byte[] key = iterator.key();
System.out.write(key);
System.out.println(serializer.deserialize(new TestInputView(iterator.value())));
iterator.next();
}
上面的程序将会输出键值对,如 (testing123, 1423), (testing456, 1212) …