《Flowable基础二 Flowable是什么》
2.1. Flowable是什么?
Flowable是一个使用Java编写的轻量级业务流程引擎。Flowable流程引擎让你可以部署BPMN 2.0流程定义(用于定义流程的行业XML标准)、创建这些流程定义的流程实例、进行查询、访问运行中或历史的流程实例与相关数据,等等。这个章节将用一个可以在你自己的开发环境中使用的例子,逐步介绍各种概念与API。
Flowable可以十分灵活地加入你的应用/服务/构架。可以将JAR形式发布的Flowable库加入应用或服务,来嵌入引擎。以JAR形式发布使Flowable可以轻易加入任何Java环境:Java SE;Tomcat、Jetty或Spring之类的servlet容器;JBoss或WebSphere之类的Java EE服务器,等等。另外,也可以使用Flowable REST API通过HTTP通信。也有许多Flowable应用(Flowable Modeler, Flowable Admin, Flowable IDM 与 Flowable Task),提供了直接可用的UI示例,可以使用流程与任务。
所有设置Flowable方法的共同点是核心引擎。核心引擎可被看做是一组服务的集合,并暴露了管理与执行业务流程的API。下面的各种教程都以设置与使用核心引擎的介绍开始。后续章节都建立在之前章节中获取的知识之上。
-
第一节展示了以最简单的方式运行Flowable的方法:只使用Java SE的标准Java main方法。这里也会介绍许多核心概念与API。
-
Flowable REST API章节展示了如何通过REST运行及使用相同的API。
-
Flowable APP章节将介绍直接可用的Flowable UI示例的基本方法。
2.2. Flowable与Activiti (Flowable and Activiti)
Flowable是Activiti(Alfresco的注册商标)的分支。在下面的章节中,你会注意到包名,配置文件等等,都使用flowable。
2.3. 构建一个命令行程序 Building a command-line application
2.3.1. 创建一个流程引擎 Creating a process engine
在本教程中,将构建一个简单的例子,以展示如何创建一个Flowable流程引擎,介绍一些核心概念,并展示如何使用API。截图使用Eclipse,但实际上可以使用任何IDE。我们使用Maven获取Flowable依赖及管理构建,但是类似的任何其它方法也都可以使用(Gradle,Ivy,等等)。
我们将构建的例子是一个简单的请假(holiday request)流程:
-
雇员(employee)申请几天的假期
-
经理(manager)批准或驳回申请
-
模拟将申请注册到某个外部系统,并给雇员发送结果邮件
首先,通过File → New → Other → Maven Project创建一个新的Maven项目
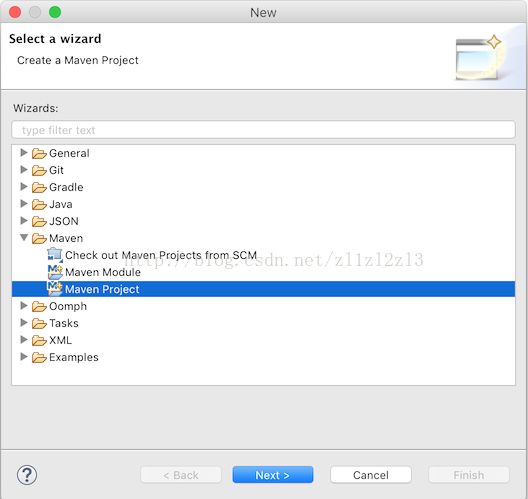
在下一界面中,选中'create a simple project (skip archetype selection)'
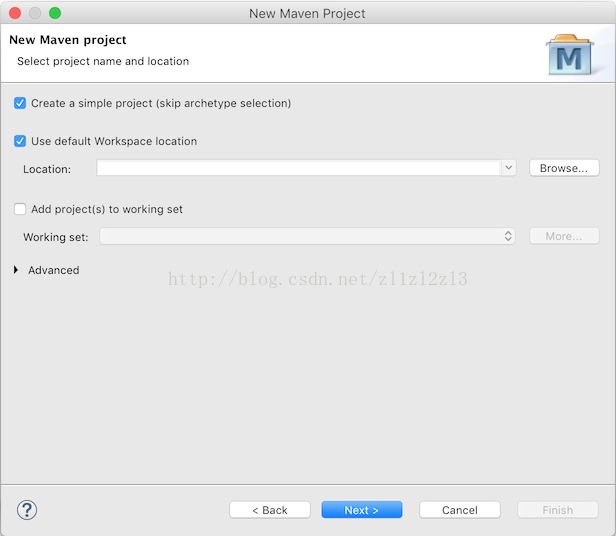
填入'Group Id'与'Artifact id':

这样就建立了空的Maven项目,然后添加两个依赖:
-
Flowable流程引擎。使我们可以创建一个ProcessEngine流程引擎对象,并访问Flowable API。
-
一个内存数据库。本例中为H2,因为Flowable引擎在运行流程实例时,需要使用数据库来存储执行与历史数据。请注意H2依赖包含了数据库及驱动。如果使用其他数据库(例如PostgreSQL,MySQL等),需要添加对应的数据库驱动依赖。
在你的pom.xml文件中添加下列行:
org.flowable flowable-engine 6.0.1 com.h2database h2 1.3.176 如果由于某些原因,依赖JAR无法自动获取,可以右键点击项目,并选择'Maven → Update Project'以强制手动刷新(一般不会需要这么操作)。在这个项目中的'Maven Dependencies'下,可以看到flowable-engine与许多其他依赖。
创建一个新的Java类,并添加标准的Java main方法:
package org.flowable; public class HolidayRequest { public static void main(String[] args) { } }
首先要做的是初始化一个ProcessEngine流程引擎实例。这是一个线程安全的对象,因此通常只需要在一个应用中初始化一次。ProcessEngine由一个ProcessEngineConfiguration实例创建。该实例可以配置与调整流程引擎的设置。通常使用一个配置XML文件创建ProcessEngineConfiguration,但是(像在这里做的一样)也可以编程方式创建它。ProcessEngineConfiguration最少需要配置一个数据库的JDBC连接:
package org.flowable; import org.flowable.engine.ProcessEngine; import org.flowable.engine.ProcessEngineConfiguration; import org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration; public class HolidayRequest { public static void main(String[] args) { ProcessEngineConfiguration cfg = new StandaloneProcessEngineConfiguration() .setJdbcUrl("jdbc:h2:mem:flowable;DB_CLOSE_DELAY=-1") .setJdbcUsername("sa") .setJdbcPassword("") .setJdbcDriver("org.h2.Driver") .setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE); ProcessEngine processEngine = cfg.buildProcessEngine(); } }
在上面的代码中,第10行创建了一个独立(standalone)配置对象。这里的'独立'指的是引擎是完全独立创建及使用的(而不是在例如Spring环境中使用,这时需要使用SpringProcessEngineConfiguration类代替)。第11至14行中,传递了一个内存H2数据库实例的JDBC连接参数。重要:请注意这样的数据库在JVM重启后会消失。如果需要永久保存数据,需要切换为持久化数据库,并相应切换连接参数。第15行中,设置了一个true标志,确保在JDBC参数连接的数据库中,数据库表结构不存在时,会创建相应的表结构。另外,Flowable也提供了一组SQL文件,可用于手动创建所有表的数据库表结构。
然后使用这个配置创建ProcessEngine对象(第17行)。
这样就可以运行了。在Eclipse中最简单的方法是右键点击类文件,选择Run As → Java Application

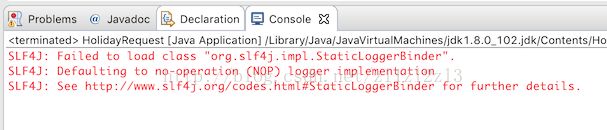
应用运行没有问题,但也没有在控制台提供有用的信息,只有一条消息提示日志没有正确配置:
Flowable使用SLF4J作为内部日志框架。在这个例子中,我们在SLF4J之上使用log4j。因此在pom.xml文件中添加下列依赖:
org.slf4j slf4j-api 1.7.21 org.slf4j slf4j-log4j12 1.7.21
Log4j需要一个配置文件。在src/main/resources文件夹下添加log4j.properties文件,并写入下列内容:
log4j.rootLogger=DEBUG, CA
log4j.appender.CA=org.apache.log4j.ConsoleAppender
log4j.appender.CA.layout=org.apache.log4j.PatternLayout
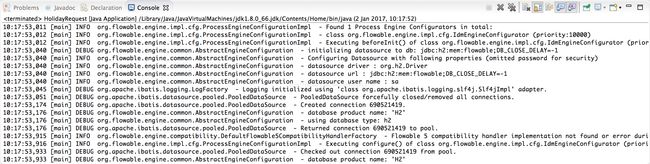
log4j.appender.CA.layout.ConversionPattern= %d{hh:mm:ss,SSS} [%t] %-5p %c %x - %m%n回到应用。应该可以看到关于引擎启动与创建数据库表结构的提示日志:
这样就得到了一个启动可用的流程引擎。接下来为它提供一个流程!
2.3.2. 部署一个流程定义 Deploying a process definition
我们要构建的流程是一个非常简单的请假流程。Flowable引擎需要流程定义为BPMN 2.0格式,这是一个业界广泛接受的XML标准。在Flowable术语中,我们将其称为一个流程定义(process definition)。一个流程定义可以启动多个流程实例(process instance)。流程定义可以看做是重复执行流程的蓝图。在这个例子中,流程定义定义了请假的各个步骤,而一个流程实例对应某个雇员提出的一个请假申请。
BPMN 2.0存储为XML,包含可视化的部分:使用标准方式定义了每个步骤类型(人工任务,自动服务调用,等等)如何呈现,以及如何互相连接。这样BPMN 2.0标准使技术人员与业务人员能用双方都能理解的方式交流业务流程。
我们要使用的流程定义为:

这个流程应该已经十分自我解释了,但为了明确起见,描述一下不同的部分:
-
我们假定启动流程需要提供一些信息,例如雇员名字、请假时长以及描述。当然,这些可以单独建模为流程中的第一步。但是如果将它们作为流程的“输入信息”,就能保证只有在实际请求时才会建立一个流程实例。否则(将提交作为流程的第一步),用户可能在提交之前改变主意并取消,但流程实例已经创建了。在某些场景中,就可能影响重要的指标(例如启动了多少申请,但还未完成),取决于业务目标。
-
左侧的圆圈叫做启动事件(start event)。这是一个流程实例的起点。
-
第一个矩形是一个用户任务(user task)。这是流程中人类用户操作的步骤。在这个例子中,经理需要批准或驳回申请。
-
取决于经理的决定,排他网关(exclusive gateway) (带叉的菱形)会将流程实例路由至批准或驳回路径。
-
如果批准,则需要将申请注册至某个外部系统,并跟着另一个用户任务,将经理的决定通知给申请人。当然也可以替换为邮件。
-
如果驳回,则为雇员发送一封邮件通知他。
一般来说,这样的流程定义使用可视化建模工具建立,如Flowable Designer(Eclipse)或Flowable Web Modeler(Web应用)。
然而,在这里,我们直接撰写XML,以熟悉BPMN 2.0及其概念。
与上面展示的流程图对应的BPMN 2.0 XML在下面显示。请注意这只包含了“流程部分”。如果使用图形化建模工具,实际的XML文件还将包含“可视化部分”,用于描述图形信息,如流程定义中各个元素的坐标(所有的图形化信息包含在XML的BPMNDiagram标签中,作为definitions标签的子元素)。
将下面的XML保存在src/main/resources文件夹下名为holiday-request.bpmn20.xml的文件中。
第2至11行看起来挺吓人,但其实在大多数的流程定义中都是一样的。这是一种样板文件,需要与BPMN 2.0标准规范完全一致。
每一个步骤(在BPMN 2.0术语中称作活动 activity)都有一个id属性,为其提供一个在XML文件中唯一的标识符。所有的活动都可选有一个名字,以提高流程图的可读性。
活动之间通过顺序流(sequence flow)连接,在流程图中是一个有向箭头。在执行流程实例时,执行(execution)会从启动事件沿着顺序流流向下一个活动。
离开排他网关(带有X的菱形)的顺序流很特别:都以表达式(expression)的形式定义了条件(condition) (见第25至32行)。当流程实例的执行到达这个网关时,会计算条件,并使用第一个计算为true的顺序流。这就是排他的含义:只选择一个。当然如果需要不同的路由策略,可以使用其他类型的网关。
这里用作条件的表达式格式为${approved},这是${approved == true}的简写。变量’approved’被称作流程变量(process variable)。流程变量是一个持久化数据,与流程实例存储在一起,并可以在流程实例的生命周期中使用。在这个例子里,我们需要在特定的地方(当经理用户任务提交时,或者以Flowable的术语来说,完成(complete)时)设置这个流程变量,因为这不是流程实例启动时就能获取的数据。
现在我们已经有了流程BPMN 2.0 XML文件,下来需要将它部署(deploy)到引擎中。部署一个流程定义意味着:
-
流程引擎会将XML文件存储在数据库中,这样可以在需要的时候获取它。
-
流程定义转换为内部的、可执行的对象模型,这样使用它就可以启动流程实例。
将流程定义部署至Flowable引擎,需要使用RepositoryService,其可以从ProcessEngine对象获取。使用RepositoryService,可以通过传递XML文件的地址创建一个新的部署(Deployment),并调用deploy()方法实际执行它:
RepositoryService repositoryService = processEngine.getRepositoryService(); Deployment deployment = repositoryService.createDeployment() .addClasspathResource("holiday-request.bpmn20.xml") .deploy();
我们现在可以通过API查询验证流程定义已经部署在引擎中(并学习一些API)。通过RepositoryService创建的ProcessDefinitionQuery对象实现。
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery() .deploymentId(deployment.getId()) .singleResult(); System.out.println("Found process definition : " + processDefinition.getName());
2.3.3. 启动一个流程实例 Starting a process instance
现在已经在流程引擎中部署了流程定义,因此可以使用这个流程定义作为“蓝图”启动流程实例。
要启动流程实例,需要提供一些初始化流程变量。一般来说,可以通过呈现给用户的表单,或者在流程由其他系统自动触发时通过REST API,来获取这些变量。在这个例子里,我们简化为使用java.util.Scanner类在命令行输入一些数据:
Scanner scanner= new Scanner(System.in); System.out.println("Who are you?"); String employee = scanner.nextLine(); System.out.println("How many holidays do you want to request?"); Integer nrOfHolidays = Integer.valueOf(scanner.nextLine()); System.out.println("Why do you need them?"); String description = scanner.nextLine();
截下来,我们使用RuntimeService启动一个流程实例。收集的数据作为一个java.util.Map实例传递,其中的键就是之后用于获取变量的标识符。这个流程实例使用key启动。这个key就是BPMN 2.0 XML文件中设置的id属性,在这个例子里是holidayRequest。
(请注意:除了使用key之外,在后面你还会看到有很多其他方式启动一个流程实例)
id="holidayRequest" name="Holiday Request" isExecutable="true"> RuntimeService runtimeService = processEngine.getRuntimeService(); Map variables = new HashMap(); variables.put("employee", employee); variables.put("nrOfHolidays", nrOfHolidays); variables.put("description", description); ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("holidayRequest", variables);
在流程实例启动后,会创建一个执行(execution),并将其放在启动事件上。从这里开始,这个执行沿着顺序流移动到经理审批的用户任务,并执行用户任务行为。这个行为将在数据库中创建一个任务,该任务可以之后使用查询找到。用户任务是一个等待状态(wait state),引擎会停止继续执行,返回API调用。
2.3.4. 另一个话题:事务性 Sidetrack: transactionality
在Flowable中,数据库事务扮演了关键角色,保证了数据一致性,并解决并发问题。当调用Flowable API时,默认情况下,所有操作都是同步的,并处于同一个事务下。这意味着,当方法调用返回时,会启动并提交一个事务。
流程启动后,会有一个数据库事务从流程实例启动时持续到下一个等待状态。在这个例子里,指的是第一个用户任务。当引擎到达这个用户任务时,状态会持久化至数据库,提交事务,并返回API调用。
在Flowable中,当一个流程实例运行时,总会有一个数据库事务从前一个等待状态持续到下一个等待状态。数据持久化之后,可能在数据库中保存很长时间,甚至几年,直到某个API调用使流程实例继续执行。请注意当流程处在等待状态时,不会消耗任何计算或内存资源。
在这个例子中,当第一个用户任务完成时,会启动一个数据库事务,从用户任务开始,经过排他网关(自动逻辑),直到第二个用户任务。或通过另一条路径直接到达结束。
2.3.5. 查询与完成任务 Querying and completing tasks
在更实际的应用中,会为雇员及经理提供用户界面,让他们可以登入并查看任务列表。其中可以看到作为流程变量存储的流程实例数据,并决定如何操作任务。在这个例子中,我们通过执行API调用模拟任务列表,通常这些API都是由UI驱动的服务在后台调用的。
我们还没有为用户任务配置办理人。我们想将第一个任务指派给"经理(managers)"组,而第二个用户任务指派给请假申请的提交人。这需要为第一个任务添加candidateGroups属性:
id="approveTask" name="Approve or reject request" flowable:candidateGroups="managers"/> 并如下所示为第二个任务添加assignee属性。请注意我们没有像上面的’managers’一样使用静态值,而是使用一个流程变量动态指派。这个流程变量是在流程实例启动时传递的:
id="holidayApprovedTask" name="Holiday approved" flowable:assignee="${employee}"/> 要获得实际的任务列表,需要通过TaskService创建一个TaskQuery。我们配置这个查询只返回’managers’组的任务:
TaskService taskService = processEngine.getTaskService(); List tasks = taskService.createTaskQuery().taskCandidateGroup("managers").list(); System.out.println("You have " + tasks.size() + " tasks:"); for (int i=0; i
可以使用任务Id获取特定流程实例的变量,并在屏幕上显示实际的申请:
System.out.println("Which task would you like to complete?"); int taskIndex = Integer.valueOf(scanner.nextLine()); Task task = tasks.get(taskIndex - 1); Map processVariables = taskService.getVariables(task.getId()); System.out.println(processVariables.get("employee") + " wants " + processVariables.get("nrOfHolidays") + " of holidays. Do you approve this?");
运行结果像下面这样:
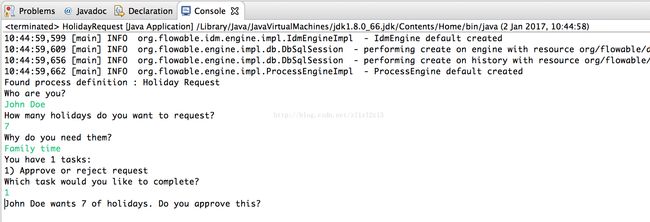
经理现在就可以完成任务了。在现实中,这通常意味着由用户提交一个表单。表单中的数据作为流程变量传递。在这里,我们在完成任务时传递带有’approved’变量(这个名字很重要,因为之后会在顺序流的条件中使用!)的map来模拟:
boolean approved = scanner.nextLine().toLowerCase().equals("y"); variables = new HashMap(); variables.put("approved", approved); taskService.complete(task.getId(), variables); 现在任务完成,并会在离开排他网关的两条路径中,基于’approved’流程变量选择一条。
2.3.6. 撰写一个JavaDelegate (Writing a JavaDelegate)
拼图还缺了一块:我们还没有实现在申请通过后执行的自动逻辑。在BPMN 2.0 XML中,这是一个服务任务(service task),长这样:
id="externalSystemCall" name="Enter holidays in external system"
flowable:class="org.flowable.CallExternalSystemDelegate"/> 在现实中,这个逻辑可以做任何事情:向某个系统发起一个HTTP REST服务调用,或调用某个使用了好几十年的系统中的遗留代码。我们不会在这里实现实际的逻辑,而只是简单的日志记录流程。
创建一个新的类(在Eclipse里File → New → Class),填入org.flowable作为包名,CallExternalSystemDelegate作为类名。让这个类实现org.flowable.engine.delegate.JavaDelegate接口,并实现execute方法:
package org.flowable; import org.flowable.engine.delegate.DelegateExecution; import org.flowable.engine.delegate.JavaDelegate; public class CallExternalSystemDelegate implements JavaDelegate { public void execute(DelegateExecution execution) { System.out.println("Calling the external system for employee " + execution.getVariable("employee")); } }
当执行到达服务任务时,会初始化并调用BPMN 2.0 XML中引用的类。
现在执行这个例子的时候,日志信息就会显示出,已经执行了自定义逻辑:
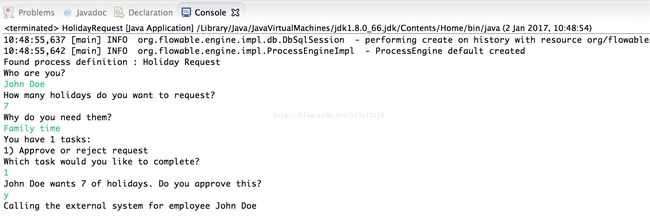
2.3.7. 使用历史数据 Working with historical data
选择使用Flowable这样的流程引擎的原因之一,是它可以自动存储所有流程实例的审计数据或历史数据。这些数据可以用于创建报告,深入展现组织运行的情况,瓶颈在哪里,等等。
例如,如果希望显示流程实例已经执行的时间,就可以从ProcessEngine获取HistoryService,并创建历史活动(historical activities)的查询。在下面的代码片段中,可以看到我们添加了一些额外的过滤:
-
只选择一个特定流程实例的活动
-
只选择已完成的活动
结果也已按照结束时间排序,意味着我们可以获取其执行顺序。
HistoryService historyService = processEngine.getHistoryService(); List activities = historyService.createHistoricActivityInstanceQuery() .processInstanceId(processInstance.getId()) .finished() .orderByHistoricActivityInstanceEndTime().asc() .list(); for (HistoricActivityInstance activity : activities) { System.out.println(activity.getActivityId() + " took " + activity.getDurationInMillis() + " milliseconds"); }
再次运行例子,可以看到控制台中显示:
startEvent took 1 milliseconds
approveTask took 2638 milliseconds
decision took 3 milliseconds
externalSystemCall took 1 milliseconds2.3.8. 小结 Conclusion
这个教程介绍了各种Flowable与BPMN 2.0的概念与术语,也展示了如何编程使用Flowable API。
当然,这只是旅程的开始。下面的章节会更深入介绍许多Flowable引擎支持的选项与特性。其他章节介绍安装与使用Flowable引擎的不同方法,并详细介绍了可用的所有BPMN 2.0结构。