在本篇图文中,我们一步步地构造使用 K 最邻近分类器的手写识别系统。 为了简单起见,这里构造的系统只能识别数字 0 到 9,如下图所示。需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小,高宽是32像素 × 32像素的黑白图像。尽管采用文本格式存储图像不能有效地利用内存空间,但是为了方便理解,我们还是将图像转换为文本格式。
目录 trainingDigits 中包含了大约 2000个 例子,每个例子的内容如下图所示,每个数字大约有 200个 样本,目录 testDigits 中包含了大约 900个 测试数据。我们使用目录 trainingDigits 中的数据训练分类器,使用目录 testDigits 中的数据测试分类器的效果,两组数据没有覆盖。

以上是《机器学习实战》中介绍 K 最邻近算法给出的示例,通过该示例我们可以了解到 K 最邻近算法应用的一个场景:解决数字识别问题。
我们在前面已经通过一篇图文介绍了 K 最邻近算法:如何利用 C# 实现 K 最邻近算法? 也通过另一篇图文介绍了用于提升搜索速度的 K-D 树结构:如何利用 C# 实现 K-D Tree 结构?,今天为大家介绍如何把两者结合起来解决上面的手写数字识别问题。
由于我们前面已经介绍过 K 最邻近算法和 K-D 树结构,所以这里不再重复,两者结合的代码如下:
1. 利用 K-D 树对 K 最邻近算法的封装。
public class KNearestNeighbors : KNearestNeighbors
{
private readonly KDTree _tree;
public KNearestNeighbors(int k, int classes, double[][] inputs, int[] outputs)
: base(k, classes, inputs, outputs, new Euclidean())
{
_tree = new KDTree(inputs, outputs, new Euclidean());
}
public KNearestNeighbors(int k, double[][] inputs, int[] outputs)
: base(k, inputs, outputs, new Euclidean())
{
_tree = new KDTree(inputs, outputs, new Euclidean());
}
public KNearestNeighbors(int k, int classes, double[][] inputs, int[] outputs,
IMetric distance)
: base(k, classes, inputs, outputs, distance)
{
_tree = new KDTree(inputs, outputs, distance);
}
public override int Compute(double[] input)
{
double[] scores;
return Compute(input, out scores);
}
public override int Compute(double[] input, out double[] scores)
{
KDTreeNodeCollection neighbors = _tree.Nearest(input, K);
scores = new double[ClassCount];
foreach (KDTreeNodeDistance point in neighbors)
{
int label = point.Node.Value;
double d = point.Distance;
scores[label] += 1.0 / (1.0 + d);
}
int result;
scores.Max(out result);
return result;
}
}
2. 利用 K 最邻近算法处理手写数字识别问题。
初始化数据的代码如下:
private static void InitData(string[] files, ref int[] outputs, ref double[][] inputs)
{
for (int i = 0; i < files.Length; i++)
{
string fileName = Path.GetFileName(files[i]);
if (fileName != null)
{
outputs[i] = Convert.ToInt32(fileName.Substring(0, 1));
string[] fonts = File.ReadAllLines(files[i]);
string font = string.Empty;
for (int j = 0; j < fonts.Length; j++)
{
font += fonts[j];
}
double[] temp = new double[font.Length];
for (int j = 0; j < font.Length; j++)
{
temp[j] = Convert.ToInt32(font[j].ToString());
}
inputs[i] = temp;
}
}
}
主程序代码如下:
static void main(string[] args)
{
string pathTrains = Environment.CurrentDirectory + @".\Data\trainingDigits";
string pathTest = Environment.CurrentDirectory + @".\Data\testDigits";
string[] fileTrains = Directory.GetFiles(pathTrains);
string[] fileTest = Directory.GetFiles(pathTest);
double[][] inputTrains = new double[fileTrains.Length][];
int[] outputTains = new int[fileTrains.Length];
double[][] inputTests = new double[fileTest.Length][];
int[] outputTests = new int[fileTest.Length];
InitData(fileTrains, ref outputTains, ref inputTrains);
InitData(fileTest, ref outputTests, ref inputTests);
//K的选择
KNearestNeighbors knn = new KNearestNeighbors(1, 10, inputTrains, outputTains);
for (int k = 1; k <= 10; k++)
{
knn.K = k;
int r = 0;
for (int i = 0; i < outputTests.Length; i++)
{
int answer = knn.Compute(inputTests[i]);
if (answer == outputTests[i])
r++;
}
double a = r * 1.0 / outputTests.Length;
if (a * 100 >= 97.50)
Console.WriteLine(@"k = {0},准确率 = {1}", k, a * 100);
}
}
3. 验证算法的结果展示。
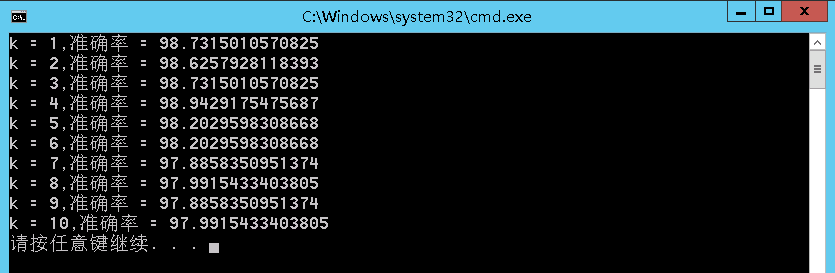
通过最后的验证,我们发现当 K=4 时有最高的准确率 99.94%。从而说明该算法能够处理该种监督分类问题。
到此为止,有关 K 最邻近算法就全部介绍完了。虽然这是机器学习中最简单的算法,但要写好这块的代码也并非易事,需要掌握面向对象的基本知识、设计模式的基本知识以及 C# 语言的基本语法结构。
看懂了吗?大家尝试一下,遇到问题可以在图文下面留言,我们一起讨论。对了,今天的数据集在后台回复 20190314 即可获得。就到这里吧!See You!
相关图文
- 如何利用 C# 实现 K 最邻近算法?
- 如何利用 C# 实现 K-D Tree 结构?
