ADP(自适应动态规划)-扩展HDP
ADP
自适应动态规划(Adaptive/Approximate Dynamic Programming,ADP)是在动态规划的基础上发展起来的,最早由 Paul J. Werbos 提出。ADP 的模型框架有:启发式动态规划(Heuristic Dynamic Programming,HDP),双启发式动态规划(Dual Heuristic Programming,DHP)、全局双启发式动态规划(Globalized Dual heuristic Programming,GDHP)以及将模型网络和评价网络合并形成的 ADHDP,ADDHP, ADGDHP 三种动作依赖(Action-Dependent)的 ADP 模型。在 DHP,HDP,GDHP 中,有评价网络(Critic Network)、模型网络(Model Network)和执行网络(Action Network)。在 ADHDP,ADDHP,ADGDHP 仅有执行网络(Action Network)和评价网络(Critic Network)。
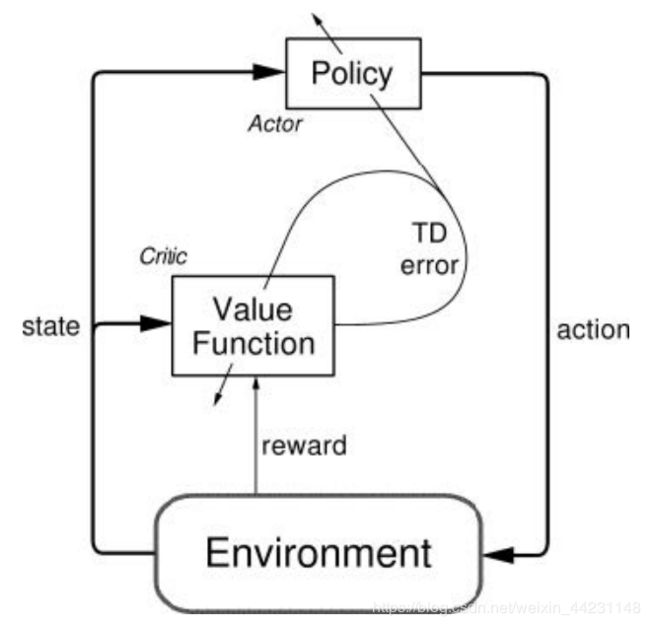
ADP 的基本框架下图所示,这与强化学习中的 Actor-Critic 框架是一致的。
上篇博客讲到HDP,此次来讲一下扩展的HDP。
扩展HDP
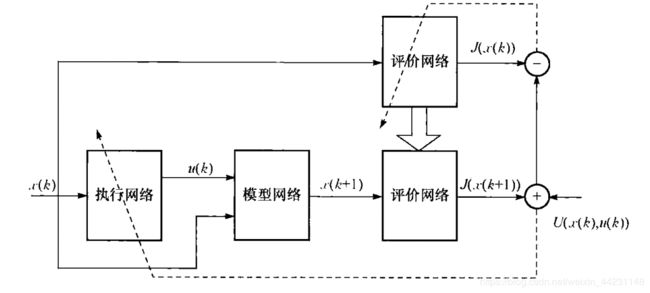
扩展的HDP在传统的HDP基础上,又添加了一个Critic Network(这个和RL中2013版DQN与2015版DQN的区别类似!对于这两个网络的作用,个人理解同RL中的思想一致:因为每次更新后,Critic Network的参数得以更新,导致该网络的Lable发生变化,从而使得训练不稳定。),每隔C次循环,将上面的Critic Network参数复制到下面的Critic Network。
同样地,定义损失函数:
L o s s = 1 2 e 2 (1) Loss=\frac{1}{2}e^2\tag{1} Loss=21e2(1)
e = J ^ 下 ( x ( k + 1 ) ) − J 上 ( x ( k + 1 ) ) (2) e = \hat{J}_下(x(k+1))-J_上(x(k+1))\tag{2} e=J^下(x(k+1))−J上(x(k+1))(2)
其中, J ^ 下 ( x ( k + 1 ) ) \hat{J}_下(x(k+1)) J^下(x(k+1))为Critic Network的实际输出。 J 上 ( x ( k + 1 ) ) J_上(x(k+1)) J上(x(k+1))为Label。根据贝尔曼最优方程:
J 上 ( x ( k + 1 ) ) = J 上 ( x ( k ) ) − l ( x ( k ) , u ∗ ( k ) ) (3) J_上(x(k+1))= J_上(x(k))-l(x(k),u^*(k))\tag{3} J上(x(k+1))=J上(x(k))−l(x(k),u∗(k))(3)
u ∗ ( k ) u^*(k) u∗(k)表示在状态为 x ( k ) x(k) x(k)时选取的最优输入(动作)。有了损失函数,则可以对Critic Network(这里只对上面的Critc Network 更新)和Action Network进行更新了。
代码实现
例子
假设非线性系统模型:
x k + 1 = g ( x k ) f ( x k ) + u k (4) x_{k+1}=g(x_k)f(x_k)+u_k\tag{4} xk+1=g(xk)f(xk)+uk(4)
其中:
f ( x k ) = [ 0.2 x k ( 1 ) e x k 2 ( 2 ) 0.3 x k 3 ( 2 ) ] (5) f(x_k)=\left[ \begin{array}{ccc} 0.2x_k(1)e^{x_k^2(2)} \\ 0.3x_k^3(2) \end{array} \right]\tag{5} f(xk)=[0.2xk(1)exk2(2)0.3xk3(2)](5)
g ( x k ) = [ 0 − 0.2 ] (6) g(x_k)=\left[ \begin{array}{ccc} 0 \\ -0.2 \end{array} \right]\tag{6} g(xk)=[0−0.2](6)
性能指标:
J = 1 2 ∫ 0 ∞ ( x T ( t ) Q ( t ) x ( t ) + u T ( t ) R ( t ) u ( t ) ) d t (7) J=\frac{1}{2}\int_{0}^{\infty}(x^T(t)Q(t)x(t)+u^T(t)R(t)u(t))dt\tag{7} J=21∫0∞(xT(t)Q(t)x(t)+uT(t)R(t)u(t))dt(7)
其中, x 1 ∈ [ − 2 , 2 ] x_1 \in[ -2,2] x1∈[−2,2] , x 2 ∈ [ − 1 , 1 ] x_2 \in[-1,1] x2∈[−1,1],初始状态为 x ( 0 ) = [ 2 , − 1 ] x(0)=[2,-1] x(0)=[2,−1],Q和R取单位矩阵。
代码
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
state_dim = 2 # 状态维度
v_dim = 1 # 价值维度
action_dim = 1 # 动作维度
learing_rate = 0.005 # 学习率
learing_num = 500 # 学习次数
sim_num = 20 # 仿真步长
x0 = np.array([2,-1]) # 初始状态
epislon = 0.0001 # 阈值
Fre_V1_Paras = 5 # 更新V1的频率
torch.manual_seed(1) # 设置随机种子,使得每次生成的随机数是确定的
########################################################################################################################
# 定义神经网络类
########################################################################################################################
class Model(torch.nn.Module):
# 初始化
def __init__(self):
super(Model, self).__init__()
self.lay1 = torch.nn.Linear(state_dim, 10, bias = False) # 线性层
self.lay1.weight.data.normal_(0,0.5) # 权重初始化
self.lay2 = torch.nn.Linear(10, 1, bias = False) # 线性层
self.lay2.weight.data.normal_(0, 0.5) # 权重初始化
def forward(self, x):
layer1 = self.lay1(x) # 第一隐层
layer1 = torch.nn.functional.relu(layer1) # relu激活函数
output = self.lay2(layer1) # 输出层
return output
########################################################################################################################
# 定义价值迭代类
########################################################################################################################
class HDP():
def __init__(self):
self.V1_model = Model() # 定义V1网络
self.V2_model = Model() # 定义V2网络
self.A_model = Model() # 定义A网络
self.criterion = torch.nn.MSELoss(reduction='mean') # 平方误差损失
# 训练一定次数,更新Critic Net的参数
# 这里只需要定义A网络和V2网络的优化器
self.optimizerV2 = torch.optim.SGD(self.V2_model.parameters(), lr=learing_rate) # 利用梯度下降算法优化model.parameters
self.optimizerA = torch.optim.SGD(self.A_model.parameters(), lr=learing_rate) # 利用梯度下降算法优化model.parameters
# 采样状态 将状态定义在x1 [-2,2] x2 [-1,1]
x = np.arange(-2, 2, 0.1)
y = np.arange(-1, 1, 0.1)
xx, yy = np.meshgrid(x, y) # 为一维的矩阵
self.state = np.transpose(np.array([xx.ravel(), yy.ravel()])) # 所有状态
self.state_num = self.state.shape[0] # 状态个数
# 动作采样 将输入定在[-10 10] 内
self.action = np.arange(-10,10,0.1)
self.cost = [] # 初始化误差矩阵
pass
####################################################################################################################
# 定义模型函数
####################################################################################################################
def model(self, current_state, u):
next_state = np.zeros([current_state.shape[0], current_state.shape[1]]) # 初始化下一个状态
for index in range(current_state.shape[0]): # 对每个样本计算下一个状态 根据输入的u
next_state[index, 0] = 0.2 * current_state[index, 0] * np.exp(current_state[index, 1] ** 2)
next_state[index, 1] = 0.3 * current_state[index, 1] ** 3 - 0.2 * u[index]
pass
return next_state
####################################################################################################################
# J_loss函数
####################################################################################################################
def J_loss(self,sk,uk,Vk_1):
Vk = np.zeros(uk.shape[0]) # x_k 的V值
for index in range(uk.shape[0]): # 对每个样本计算下一个状态 根据输入的u
Vk[index] = sk[0] ** 2 + sk[1] ** 2 + uk[index] ** 2 + Vk_1[index]
pass
return Vk
pass
####################################################################################################################
# 定义学习函数
####################################################################################################################
def learning(self):
for train_index in range(learing_num):
print('the ' , train_index+1 , ' --th learing start')
last_V_value = self.V2_model(Variable(torch.Tensor(self.state))).data
#############################################################################################################
# 更新Crictic网络
#############################################################################################################
V2_predict = self.V2_model(Variable(torch.Tensor(self.state))) # 预测值
la_u = self.A_model(Variable(torch.Tensor(self.state))) # 计算输入
la_next_state = self.model(self.state, la_u) # 计算下一时刻状态
V2_target = np.zeros([self.state_num, 1]) # 初始化V网络的标签
for index in range(self.state_num): # 循环计算所有状态的标签
next_V1 = self.V1_model(Variable(torch.Tensor(la_next_state[index, :])))
V2_target[index] = self.state[index, 0] ** 2 + self.state[index, 1] ** 2 + la_u.data[
index] ** 2 + next_V1.data
pass
V2_loss = self.criterion(V2_predict, Variable(torch.Tensor(V2_target))) # 计算损失
self.optimizerV2.zero_grad() # 对模型参数做一个优化,并且将梯度清0
V2_loss.backward() # 计算梯度
self.optimizerV2.step() # 权重更新
print(' the ' , train_index+1 , ' Critic Net have updated')
#############################################################################################################
# 更新Actor网络
#############################################################################################################
A_predict = self.A_model( Variable(torch.Tensor(self.state))) # 预测值
A_target = np.zeros([self.state_num, 1]) # 初始化A网络的标签
for index in range(self.state_num): # 循环计算所有状态的标签
new_state = np.tile(self.state[index,:], (self.action.shape[0], 1))
new_xk_1 = self.model(new_state,self.action)
next_V1 = self.V1_model(Variable(torch.Tensor(new_xk_1)))
A1 = self.J_loss(self.state[index,:], self.action , next_V1.data)
A_target_index = np.argmin(A1)
A_target[index] = self.action[A_target_index]
pass
A_loss = self.criterion(A_predict, Variable(torch.Tensor(A_target))) # 计算损失
self.optimizerA.zero_grad() # 对模型参数做一个优化,并且将梯度清0
A_loss .backward() # 计算梯度
self.optimizerA.step() # 权重更新
print(' the ', train_index+1, ' Action Net have updated')
# 训练一定次数更新V1网络
if (train_index+1) % Fre_V1_Paras == 0:
self.V1_model = self.V2_model
print(' Use V2 Net update V1 Net')
pass
print('A paras:\n', list(self.A_model.named_parameters()))
print('V1 paras:\n', list(self.V1_model.named_parameters()))
print('V2 paras:\n', list(self.V2_model.named_parameters()))
V_value = self.V2_model(Variable(torch.Tensor(self.state))).data # 计算V
# print("V:",V_value)
# print("last_V",last_V_value)
pp = np.abs(V_value)-np.abs(last_V_value)
#print(pp)
dis = np.sum(np.array(pp.reshape(self.state_num))) #平方差
self.cost.append(np.abs(dis))
print(' deta(V): ',np.abs(dis))
if np.abs(dis) < epislon:
print('loss小于阈值,退出训练')
self.V1_model = self.V2_model
break
pass
# 保存和加载整个模型
# 每次训练完可以保存模型,仿真时候 直接load训练好的模型 或者 继续训练可以接着上一次训练的结果继续训练
#torch.save(model_object, 'model.pth')
#model = torch.load('model.pth')
pass
#######################################################################################################
# 定义仿真函数
# 通过得到的Actor选择动作
# 同时利用Critic计算V
#######################################################################################################
def simulator(self):
print('the simulation is start')
#self.restore(self.path)
State_traject = np.zeros([sim_num + 1, state_dim])
State_traject[0, :] = x0
u_traject = np.zeros([sim_num, 1])
for index in range(sim_num):
print('the ', index, ' --th time start')
print('当前状态:', Variable(torch.Tensor(State_traject[index,:])).data)
sim_actor = self.A_model(Variable(torch.Tensor(State_traject[index,:])))
print('当前输入:',sim_actor)
u_traject[index] = sim_actor.data
sim_nexstate = self.model(State_traject[index, :].reshape(1, 2), sim_actor.data)
print('下一时刻状态:', sim_nexstate)
State_traject[index + 1, :] = sim_nexstate
pass
pass
V1_traject = self.V1_model(Variable(torch.Tensor(State_traject))).data
print('the simulation is over')
self.plot_curve(State_traject , u_traject , V1_traject , self.cost)
pass
#######################################################################################################
# 绘图函数
# 分别绘制状态轨迹 控制输入u轨迹 值函数V轨迹
# 并将结果保存!
#######################################################################################################
def plot_curve(self, s, u, V,cost):
# print('\nstate\n',s)
# print('\nu\n', u)
# print('\nV\n', V)
# 绘制状态轨迹
plt.figure(1)
plt.plot(s[:, 0], 'r', label='State_1')
plt.plot(s[:, 1], 'b', label='State_2')
plt.title('State_Trajecteory')
plt.xlabel('iter')
plt.ylabel('State')
plt.legend()
plt.grid()
plt.savefig(r'ADPresultfig\HDP_with_targetnet_state.png')
plt.show()
# 绘制控制输入u轨迹
plt.figure(2)
plt.plot(u, )
plt.title('U_Trajecteory')
plt.xlabel('iter')
plt.ylabel('u')
plt.grid()
plt.savefig(r'ADPresultfig\HDP_with_targetnet_u.png')
plt.show()
# 绘制值函数V的轨迹
plt.figure(3)
plt.plot(V, 'r')
plt.title('Cost_Trajecteory')
plt.xlabel('iter')
plt.ylabel('Cost')
plt.grid()
plt.savefig(r'ADPresultfig\HDP_with_targetnet_V.png')
plt.show()
# 绘制值函数V的轨迹
plt.figure(4)
plt.plot(cost, 'r')
plt.title('Train_loss_Trajecteory')
plt.xlabel('iter')
plt.ylabel('Train_loss')
plt.grid()
plt.savefig(r'ADPresultfig\HDP_with_targetnet_loss.png')
plt.show()
pass
########################################################################################################################
# 函数起始运行
# 在仿真时候,直接调用最优的模型进行仿真
# 最优的模型根据损失函数进行判断
########################################################################################################################
if __name__ == '__main__':
Agent = HDP() # 值迭代类实例化
Agent.learning() # 学习
Agent.simulator() # 仿真
代码运行说明
需要安装Pytorch
由于保存结果,因此需要在根目录先创建ADPresultfig文件夹
python文件只需要放在根目录下即可
结果
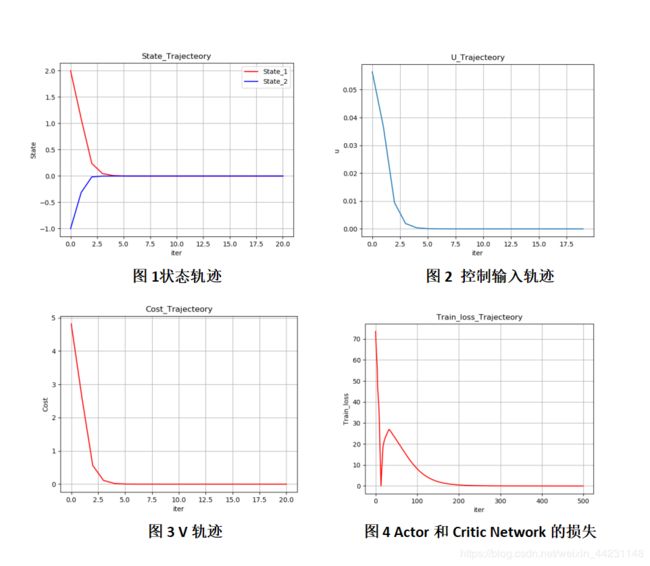
图1显示了测试阶段系统两个状态的轨迹,可以看出经过4步,系统已经收敛到稳定点。图2表明输入也收敛为0V。图3表明V(Critic)也收敛为0。图5显示了在训练阶段Actor Network和Critic Network的损失值,从下降-上升-下降,随后逐渐收敛为0。在扩展的HDP中,没有训练Model Network,直接用的原系统。
可以对比一下传统的HDP(点这里!!)。对比实验结果,扩展的HDP在状态轨迹,V曲线都更光滑!!!
The End
文中的一些原理和图摘自其他出处,若有侵权,请告知,立马删除本文。
作者也是第一次写这方面代码,有理解错误的和代码错误的地方可以一起交流学习。
!!请勿转载本文!!
觉得作者写的还行就赏个脸,打赏一毛钱呗!哈哈哈