本文仅是翻译(翻译的准确度有待商榷),并非个人所写,文中涉及的“我”为文章作者,并非本人。
来源(转载):http : //konukoii.com/blog/2018/02/19/twitter-sentiment-analysis-using-combined-lstm-cnn-models/
说明:近期在看机器学习相关论文以及论文相关程序(GitHub),相关个人博客均为英语,因为没有习惯于英文文献的阅读,这使自己在阅读过程中,感觉有些“别扭”,虽然谷歌浏览器可以自动翻译,但是这对以后阅读英文文献存在太多弊端,所以在此先进行为期一个月的翻译练习每日打卡!
2018年2月19日 计算机科学
基于 LSTM-CNN结合模型的Twitter情感分析
一年之前,“我”写过有关神经网络课程的论文,“我”没有发表。我决定从我大部分黑客帖子中休息一下,谈一谈机器学习。这篇论文是我做的一些工作的延续,(在过去的文章中已经概述过)关于Twitter数据的情感分析。(如果你是神经网络的新手,我建议看看那篇文章)
这是我撰写的[研究论文]简化版,如果您想要了解更多细节,请随时查看。如果您只关注实现,请查看“我”的Github project
动机
Twitter现在是一个托管约3.5亿活跃用户的平台。每天发布5亿条推文!它已成为公司/组织与其客户之间的直接联系,并且正在被用于建立品牌,了解客户需求并更好的与他们沟通。从数据科学家的角度来看,Twitter是一个金矿,可以用于衡量消费者对品牌的感受。
在这个项目中,我个人的利益来源与我的好奇心,为了更好的理解神经网络,尤其是CNN与LSTM。 在先前的课程中,我创建了一个简单的前馈神经网络去解决这个问题。然而,我知道当利用更加专业的网络时候,我的结果实质上可以更好。
直觉:为什么CNN 和 LSTM?
在开始之前,对这些网络进行简要介绍,并简要分析为什么我认为他们是我的情感分析任务受益。
CNNs
卷积神经网络是最初为图片任务创建的网络,可以学习捕捉特定的特征而不管局部特征。举一个更具体的例子,假设我们使用CNN来区分Cars和Dogs的照片。由于CNN学习捕捉特征而不管这些特征在哪里,CNN将会知道车有轮子,并且每次看到车轮时,无论它在图片的那个位置,该特征将会被激活。
在我们特定的情况下,CNN可以捕捉一个消极的短语,例如“不喜欢”
而不管它在推文发生的什么位置。
- 我不喜欢这些类型的电影
- 那一件事情我真的不喜欢
-
我看过这个电影,但是不喜欢它的结局。
 来源:wildml.com
来源:wildml.com
LSTMs
长短期记忆(LSTM) 是一种网络,具有记忆来自输入的先前数据并基于该知识作出决定的存储器。这些网络更直接适用与书面数据的输入。因为在句子中的每一个单词都有基于周围的单词的含义(先前和即将出现的单词)。
在我们的具体情况中,LSTM有可能让我们能够在推文中捕捉到不断变化的情绪。例如,一个句子,例如:“At first I loved it, but then I ended up hating it.” 有相矛盾的观点,最终会导致简单的前馈网络混淆。另一方面,LSTM可以得知,在句子结尾处表达的意思比一开始表达的意思更重要。

Twitter 数据
用于此特定实验的Twitter数据是两个数据集的混合。
- 密歇根大学Kaggle竞赛数据集。
- Neik Sanders Twitter情感分析语料库。
这些数据集一共包括1578627个带标签的推文。
CNN-LSTM 模型
第一个尝试的模型是CNN-LSTM 模型,我们的CNN-LSTM 模型结合由初始的卷积层组成,这将接收word embedding(对文档中每个不同的单词都得到一个对应的向量)作为输入。然后将其输出汇集到一个较小的尺寸,然后输入到LSTM层。隐藏在这个模型后面的直觉是卷积层将提取局部特征,然后LSTM层将能够使用所述特征的排序来了解输入的文本排序。实际上,这个模型并不像我们提出的其他LSTM-CNN模型那么强大。

LSTM-CNN 模型
我们的LSTM-CNN 模型由一个初始LSTM层构成,它将接收 tweet中每一个令牌的word embedding作为输入。直觉是它输出的令牌不仅仅存储初始令牌的信息,而且还存储任何先前的令牌。换句话说,LSTM层正在为原始输入生成一个新的编码。然后将LSTM层的输出紧接着输入到我们期望可以提取局部特征卷积层中。最后卷积层的输出将被汇集到一个较小的纬度,最终输出为正或负标签。
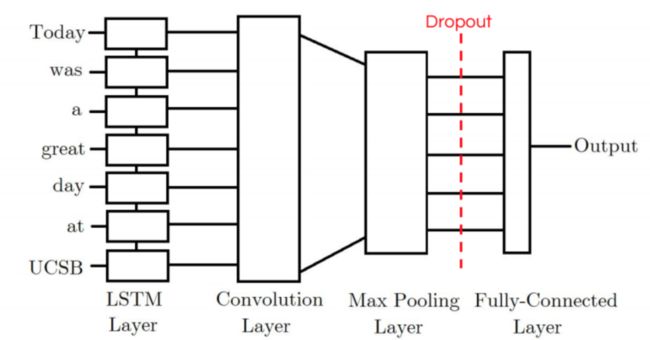
结果
我们设置了实验,使用10000条推文的训练集,2500条带有标签的推文的测试集。这些训练与测试集包括同等数量的正面与负面推文。我们重复做5次测试并报告这些测试的平均结果。
我们使用了以下通过手工测试进行微调的参数:

以下是我们准确的结果:

我们的CNN-LSTM模型比CNN模型实现了3%精准度的提高,但与此同时比LSTM模型低3.5%。我们的LSTM-CNN模型性能比CNN模型高8.5%,LSTM模型高2.7%。
这些结果似乎表明我们最初的直觉是正确的,并且通过结合CNN与LSTM,我们可以同时利用 CNN识别局部特征与 LSTM利用文本序列的能力。然而,在我们的模型中层之间的排序将在如何优化性能中承担着重要的角色。
我们相信在我们模型之间5.5%的差异不是巧合。我们CNN-LSTM最初卷积层似乎丢失了文本序列信息的一些信息。因此如果卷积层的排序没有真正的给我们任何信息,LSTM层将仅仅充当着全连接层的作用。似乎这个模型在充分利用LSTM层的能力是失败的,因此不能实现最大化的潜力。实际上,它甚至比传统的LSTM模型更差。
另一方面,LSTM-CNN模型似乎是最好的,因为初始的LSTM看起来像一个编辑器,因此对于输入中的每个标记都有一个输出标记,其中不仅包含原始标记的信息,而且还包含输出标记所有其他以前的令牌。之后,CNN层将使用原始输入的更丰富的表示来查找局部图案,从而获得更好的准确性。
进一步观察
我在测试过程中所做的一些观察(以及在论文中更详细地解释):
学习率
与LSTM和LSTM-CNN模型相反,CNN 和CNN-LSTM模型需要更多的epoch去学习和快速减少过拟合。

Drop Rates
这并不令人意外,但我注意到在CNN-LSTM和LSTM-CNN模型中的任何卷积层之后添加Dropout层是非常重要的。

预训练的Word Embeddings
我尝试使用预训练的Word Embeddings,而不是让系统从我们的数据中学习Word Embeddings,令人惊讶的是使用预训练的GloVe Word Embeddings会降低准确度。我认为这个事实可能因为tweet数据包含大量的错误拼写,表情,@,并且一些专业的推文不规则的文本在建立GloVe Embeddings 没有进行考虑。

结论与未来工作
未来工作的目标,我经测试其他类型的LSTM(例如 Bi-LSTM),并查看它对我们系统的准确性有何影响。找到更好的方法来处理在twitter语言中发现的拼写错误或其他违规行为也很有趣。我相信这可以通过构建Twitter特定的词嵌入来实现。最后,使用Twitter的特定功能(如转发,喜欢等)来提供文本数据会很有趣。
个人而言,这个项目主要是为了进一步理解CNN和LSTM模型,并尝试使用Tensorflow。此外,我很高兴看到这两个模型比我们以前的(简单的)尝试做得更好。
与往常一样,源代码和论文可以公开获取:论文和代码。如果您有任何疑问或意见,请随时与我们联系。快乐的编码!