预训练 Bert 【 VilBERT,LXMERT,VisualBERT,Unicoder-VL,VL-BERT,ImageBERT 】--- 记录
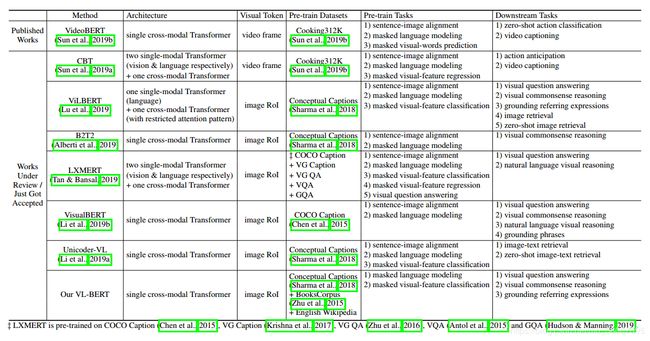
VilBERT 和 LXMERT 网络结构都是句子和图像的两个单模态的网络,然后使用一个跨模态的 Transformer 融合信息。
VisualBert , B2T2, Unicoder-VL,VL-BERT,Unified VLP,UNITER的网络结构都大致相同,不同在于预训练数据集和任务不同。
IMAGEBERT: CROSS-MODAL PRE-TRAINING WITH LARGE-SCALE WEAK-SUPERVISED IMAGE-TEXT DATA
Paper : http://arxiv.org/abs/2006.02635v1
预训练任务:Masked Language Modeling ( MLM ), Masked Object Classification ( MOC ), Masked Region Feature Regression ( MRFR ), Image Text Matching ( ITM )
预训练数据集:Large-scale weAk-supervised Image-Text ( LAIT ),Conceptual Captions ( CC ),

Embedding Modeling
Linguistic embedding
输入的句子使用 WordPiece 方法被标记为 n 个子词,每个子词 token 的最终嵌入是通过组合其原始词嵌入 (original word embedding) ,片段嵌入 (segment embedding) 和序列位置嵌入 (sequence position embedding) 生成的。
Image embedding
通过 Faster RCNN 提取 RoIs,检测到的目标不仅可以为语言部分提供整个图像的视觉环境,还可以通过详细的区域信息与特定术语相关。在 image embedding 中加入 position embedding ( 对目标的相对位置编码[左上角坐标,右下角坐标,与整张图像的面积比例 )。使用 linguistic embedding 把目标特征和location embedding 映射到相同的维度,最终的表示是 object embedding + segment embedding + image position embedding + sequence position embedding 。
Sequence position and segment embedding
Sequence position embedding 用来表示输入 tokens 中的每一个 token 的顺序。对于视觉 token 使用固定的假的位置,但是在 image embedding 中加入了目标的坐标。segment embedding 是用来区分每个输入 token 的不同模态。
Pre-training tasks
Task1: Masked Language Modeling ( MLM )
将被预测的输入 token 以15%的概率随机屏蔽。被掩码的 token 替换为特殊 token [MASK],随机 token 或保持不变的概率分别为80%,10%和10%。使用 负log 损失
Task2: Masked Object Classification ( MOC )
以 15% 的概率随机屏蔽目标 token,置 0 或者 保持不变的概率为 90%,10% 。使用交叉熵损失。
Task3: Masked Region Feature Regression ( MRFR )
屏蔽掉视觉内容。使每个被屏蔽掉的目标的嵌入特征退化。在顶端加入全连接层映射到与 RoI 目标特征相同的维度。使用 L2 损失
Task4: Image-Text Matching ( ITM )
学习图像文本对齐。给每一个图像分配负样本句子,或者给每一个句子分配负样本图像,生成负样本训练数据。对每一对图像文本对都有 {0, 1} 的标签,表明输入的样本对是否相关。在第一个 token 加入 [CLS] 来学习,在顶端加如全连接获得相似度分数。二分类损失
Fine-tuning tasks
两个 fine-tuning 目标对应与不同的负样本方法:image-to-text ( 每张图像的负样本句子 ) 和 text-to-image ( 每个句子的负样本图像 )
Binary classification Loss
保证负样本的预测是正确的:负样本的输出分数不仅是和正样本不同的,而且应该预测出正确的标签。
Multi-class Classification Loss
扩大正负样本之间的间距
Triplet Loss
最大化正样本与硬负样本之间的间距
训练方式:
先在 LAIT 数据集上预训练,在公共数据集 ( CC + SBU) 上训练,最后在现有任务上 finetune,使用 binary classification loss 达到最好的性能
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Paper : http://arxiv.org/abs/1908.07490v3
Code : https://github.com/airsplay/lxmert
三个编码:目标关系编码器 ( object relationship encoder ) ,语言编码器( language encoder ),跨模态编码器 ( cross-modality encoder )
五个预训练任务:masked language modeling, masked object prediction (feature regression and label classification), cross-modality matching, and image question answering
预训练数据集:在 COCO Caption,VG Caption,VQA,GQA,VG-QA五个数据集上预训练(6.5M image,100M words)

Input Embeddings
Word-Level Sentence Embeddings
使用 WordPiece 方法对句子编码,把单词和位置映射为向量,然后相加
Object-Level Image Embeddings
RoI 特征和位置特征分别使用全连接层学习,然后相加
Encoders
self-attention layers and cross-attention layers
Single-Modality Encoders
Cross-Modality Encoder
cross-attention 是用来交换两个模态之间的信息并且对齐实体。
Output Representations
三个输出:language, vision, and cross-modality
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Paper : http://arxiv.org/abs/1908.02265v1
Code : https://github.com/facebookresearch/vilbert-multi-task
co-attentional transformer layers
预训练数据:Conceptual Captions ( 3.3M 图片 )
预训练任务:masked multi-modal modeling and multi-modal alignment prediction

TRM ( Transformer block ), co-attention transformer layers ( Co-TRM )

Unicoder-VL: A Universal Encoder for Vision and Language by Cross-Modal Pre-Training
Paper : http://arxiv.org/abs/1908.06066v3

三个预训练任务:Masked Language Modeling ( MLM ), Masked Object Classification ( MOC ) and Visual-linguistic Matching ( VLM [ 相当于ImageBERT的 ITM ])
Linguistic Embedding 和 Image Embedding 与 ImageBERT 相同
预训练数据:3.8M image-caption pairs ( 3M Conceptual Captions and 0.8M SBU Captions)
Image-Text Retrieval
数据: MSCOCO,Flickr30K
使用 triplet loss
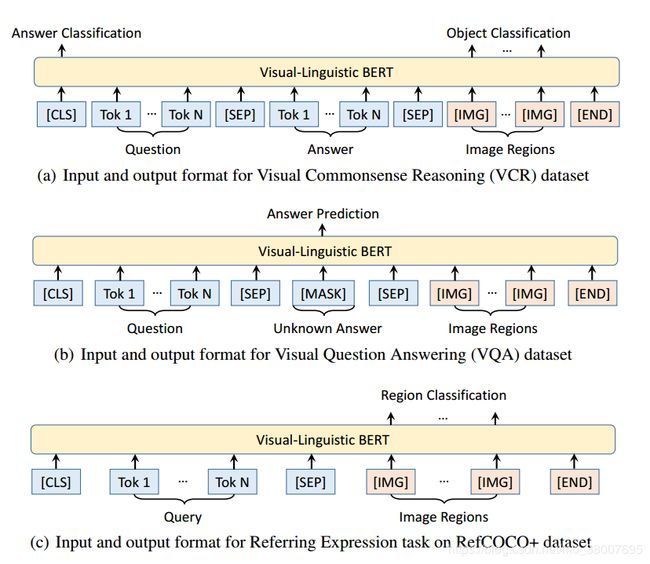
Visual Commonsense Reasoning
数据:VCR
VISUALBERT: A SIMPLE AND PERFORMANT BASELINE FOR VISION AND LANGUAGE
Paper : http://arxiv.org/abs/1908.03557v1
Code : https://github.com/uclanlp/visualbert
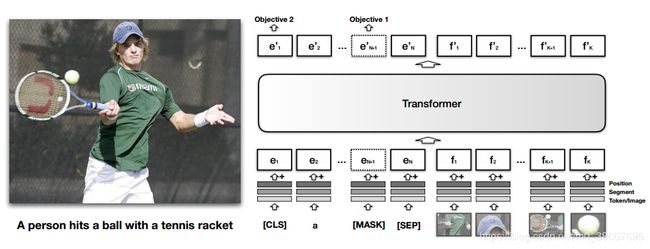
预训练数据集:COCO image caption dataset
两个预训练任务 : Masked language modeling with the image , Sentence-image prediction
四个测试任务:VQA,VCR,NLVR,Flickr30K
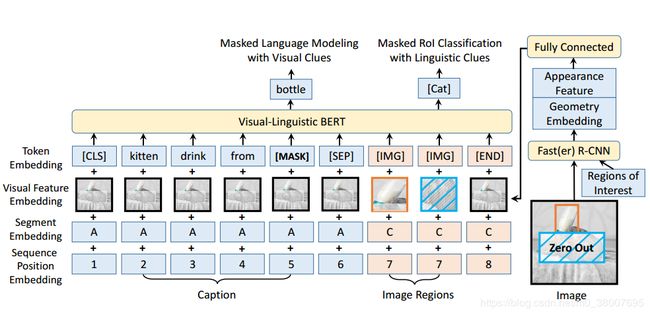
VL-BERT: PRE-TRAINING OF GENERIC VISUALLINGUISTIC REPRESENTATIONS
Paper : http://arxiv.org/abs/1908.08530v4
Code : https://github.com/jackroos/VL-BERT
预训练数据:Conceptual Captions dataset ( visual-linguistic ) and BookCorpus & English Wikipedia ( text-only )
- 句子和图像的关系的预训练没有帮助,所以没有这部分的预训练
- 在 visual-linguistic and text-only 数据集上预训练,可以提高长且复杂句子的通用性。
- 提高了视觉表示的调整。为了避免在预训练 Masked RoI Classification with Linguistic Clues 任务时,视觉线索泄露,所以输入图像上做 mask,而不是在输出的特征图上做 mask
在文字输入上也加入了视觉特征,这部分是整张图像的视觉特征。而对于图像区域部分是相对应区域的视觉特征。