【目标检测系列】yolov3,yolov4训练自己的数据(pytorch 版本)
写在前面:坑坑洼洼,总算弄出个初步效果。适用小白学习,因为我就白啊!!!!!!!!!!!!
主要内容:部分理论。如何准备自己的数据集,训练预测。在windows下vs2017调用训练好的模型方法。
PS:yolov3与yolov4统一到一起了,不同的就是修改他们的cfg文件还有加载预训练网络。训练过程发现v4的gpu是起起伏伏的,v3是稳定在一个值,v4比v3的batchsize设置小很多训练慢。
一.代码地址:
https://github.com/ultralytics/yolov3
二.原理:主要说说网络结构吧,因为不看这个的话,与代码对应不上啊。网络输出还是一张图吧。红色部分可以看成是网络主干部分,如darknet53,蓝色部分是在13*13这个层上输出结果,橙色部分是在26*26这个层下输出的结果,绿色部分是在52*52这个层输出的结果。这个13*13的由来呢。原图416*416 缩放32倍就这样了。这张图与cfg文件中的好些参数一一对应的。对应关系看这个https://blog.csdn.net/gbz3300255/article/details/106255335。主要就是关注输入与输出,因为要与代码对应去
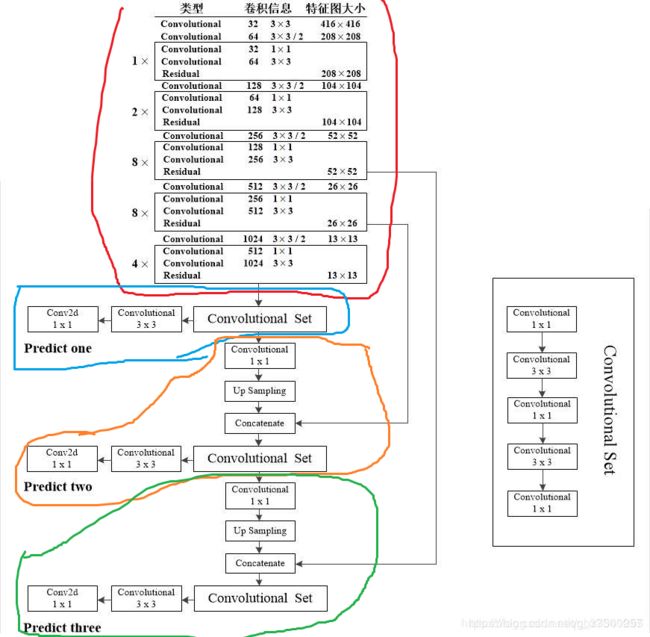
之所以有三个颜色的圈圈是为了做多尺度检测。三次检测,每次对应的感受野不同,32倍降采样的感受野最大,适合检测大的目标,16倍适合一般大小的物体,8倍的感受野最小,适合检测小目标。具体的anchor box的大小在cfg文件中设置。如下图红色表示anchor中心所在。



具体怎么算损失函数的,怎么做先验框的就不说了。这里只管输入输出。
上面代码的输入输出如下
输入:假设是一张416*416*3的图像。(这个输入尺寸程序里默认是320*640,训练自己数据时候注意一下)
输出:【1,(13*13 +26*26 + 52*52)*3, 85】 维的一个数据
(13*13 +26*26 + 52*52 *3)是啥呢 是 一共有多少个检测中心,乘3是每个中心有3种先验框。那么(13*13 +26*26 + 52*52)*3就是一共有这么多个检测框结果存在 。
85是啥呢。是上面13*13或26*26或512*512的特征图上一个点的特征值的维度。这个维度怎么来的呢,网络检测目标有80类,那么点对应的检测框有80个概率值,其对应每个类的可信度,每个点的检测框有4个关于框位置的值(x,y,w,h),还有1个此框的置信度。那么这个点对应的框的特征值就是(1 + 4 + 80 ) = 85维的.
罗里吧嗦这么多因为cfg文件中我们做自己的数据训练是要改这个值的。
三.训练自己数据集的步骤:
1.准备数据集:先明白yolov3需要的数据集长啥样。说白了它就是要一张图对应一个标签文件。一堆图和对应的一堆文件组成了图像数据集和标签数据集。标签数据集名字和图像名一一对应,标签数据集内容为:类别标号 目标框x中心, 目标框y中心, 目标框宽度值, 目标框高度值。注意,前面的类别编号直接0 1 2 3 4....等就可以了,后面的值是除以宽或高后的浮点值。如下图超级实用。
因为为了快速上手看效果。直接下载现成数据集好了。我用的是CCTSDB 数据集。用程序将其box读出来写成上图中man007.txt文本内的形式。
代码不方便贴了,实现功能说一下很简单。读取CCTSDB数据集,读取每张图片,并读取对应的json文件,将类别以及框读出来,类别按0 1 2 ..编号,框数据按上图方法计算,将其写成一列,形如:
0 0.669 0.5785714285714286 0.032 0.082857142857142851.1 准备文本文件: train.txt test.txt val.txt lables的文本文件
train.txt,记录数据集下图片名字,类似这样,数据集图片存放在/data/images/目录下。
BloodImage_00091
BloodImage_00156
BloodImage_00389
BloodImage_00030
BloodImage_00124
BloodImage_00278
BloodImage_00261test.txt,与面形式一样,内容是需要测试的图的文件名
BloodImage_00258
BloodImage_00320
BloodImage_00120
val.txt,与面形式一样,内容是验证集内图文件名
BloodImage_00777
BloodImage_00951
lables类文本,images中每张图像对应一个关于lables的文本,形式如下,名字类似这样BloodImage_00091.txt。
0 0.669 0.5785714285714286 0.032 0.08285714285714285lables文本统一放在上面代码的/data/lables/中
1.2 准备rbc.data文件,文件名随便取的,记得输入参数时候按这个文件名输入程序就好,内容如下,
第一个就是种类个数,下面的就是参与训练的图片,参与测试的图片等的路径,以及每个类的名字的文本路径了。
classes=4
train=data/train.txt
valid=data/test.txt
names=data/rbc.names
backup=backup/
eval=coco1.3 准备rbc.names文件,文件名随便取的,记得输入参数时候按这个文件名输入程序就好,内容如下。
四类的类型,犯懒 就直接写作a,b,c,d了 根据自己的类别去改吧
a
b
c
d
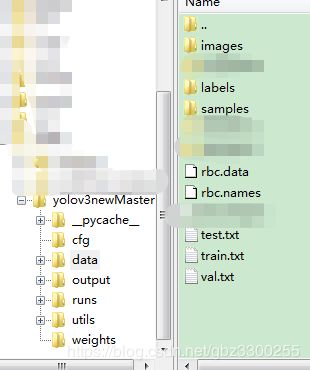
1.4 准备图片数据,训练图放入images里,测试图放入samples里。images中的图与lables中的文本一一对应。
最终的存储结构类似这样,在data文件夹下。
2.修改cfg文件:确定用哪个模型再去修改哪个cfg文件吧,例如我用yolov3做训练,那就去cfg文件夹下找到yolov3.cfg,修改它就行,我只修改了类别数以及filters的值,因为filters与类别数有关。yolov3看网络结构可知需要有3处修改。其他如anchor的大小等 如果原来的框与待检测目标差异较大,建议还是重新聚类计算一组anchors出来吧
classes = 4
#filters=3 * (5 + classes )
filters= 27 #3 * (5 + 4)修改anchors,如果自己训练集的内容与image上的不同,那必须修改啊。计算anchors代码如下。引用大神代码
# -*- coding: utf-8 -*-
import numpy as np
import random
import argparse
import os
#参数名称
parser = argparse.ArgumentParser(description='使用该脚本生成YOLO-V3的anchor boxes\n')
parser.add_argument('--input_annotation_txt_dir',required=True,type=str,help='输入存储图片的标注txt文件(注意不要有中文)')
parser.add_argument('--output_anchors_txt',required=True,type=str,help='输出的存储Anchor boxes的文本文件')
parser.add_argument('--input_num_anchors',required=True,default=6,type=int,help='输入要计算的聚类(Anchor boxes的个数)')
parser.add_argument('--input_cfg_width',required=True,type=int,help="配置文件中width")
parser.add_argument('--input_cfg_height',required=True,type=int,help="配置文件中height")
args = parser.parse_args()
'''
centroids 聚类点 尺寸是 numx2,类型是ndarray
annotation_array 其中之一的标注框
'''
def IOU(annotation_array,centroids):
#
similarities = []
#其中一个标注框
w,h = annotation_array
for centroid in centroids:
c_w,c_h = centroid
if c_w >=w and c_h >= h:#第1中情况
similarity = w*h/(c_w*c_h)
elif c_w >= w and c_h <= h:#第2中情况
similarity = w*c_h/(w*h + (c_w - w)*c_h)
elif c_w <= w and c_h >= h:#第3种情况
similarity = c_w*h/(w*h +(c_h - h)*c_w)
else:#第3种情况
similarity = (c_w*c_h)/(w*h)
similarities.append(similarity)
#将列表转换为ndarray
return np.array(similarities,np.float32) #返回的是一维数组,尺寸为(num,)
'''
k_means:k均值聚类
annotations_array 所有的标注框的宽高,N个标注框,尺寸是Nx2,类型是ndarray
centroids 聚类点 尺寸是 numx2,类型是ndarray
'''
def k_means(annotations_array,centroids,eps=0.00005,iterations=200000):
#
N = annotations_array.shape[0]#C=2
num = centroids.shape[0]
#损失函数
distance_sum_pre = -1
assignments_pre = -1*np.ones(N,dtype=np.int64)
#
iteration = 0
#循环处理
while(True):
#
iteration += 1
#
distances = []
#循环计算每一个标注框与所有的聚类点的距离(IOU)
for i in range(N):
distance = 1 - IOU(annotations_array[i],centroids)
distances.append(distance)
#列表转换成ndarray
distances_array = np.array(distances,np.float32)#该ndarray的尺寸为 Nxnum
#找出每一个标注框到当前聚类点最近的点
assignments = np.argmin(distances_array,axis=1)#计算每一行的最小值的位置索引
#计算距离的总和,相当于k均值聚类的损失函数
distances_sum = np.sum(distances_array)
#计算新的聚类点
centroid_sums = np.zeros(centroids.shape,np.float32)
for i in range(N):
centroid_sums[assignments[i]] += annotations_array[i]#计算属于每一聚类类别的和
for j in range(num):
centroids[j] = centroid_sums[j]/(np.sum(assignments==j))
#前后两次的距离变化
diff = abs(distances_sum-distance_sum_pre)
#打印结果
print("iteration: {},distance: {}, diff: {}, avg_IOU: {}\n".format(iteration,distances_sum,diff,np.sum(1-distances_array)/(N*num)))
#三种情况跳出while循环:1:循环20000次,2:eps计算平均的距离很小 3:以上的情况
if (assignments==assignments_pre).all():
print("按照前后两次的得到的聚类结果是否相同结束循环\n")
break
if diff < eps:
print("按照eps结束循环\n")
break
if iteration > iterations:
print("按照迭代次数结束循环\n")
break
#记录上一次迭代
distance_sum_pre = distances_sum
assignments_pre = assignments.copy()
if __name__=='__main__':
#聚类点的个数,anchor boxes的个数
num_clusters = args.input_num_anchors
#索引出文件夹中的每一个标注文件的名字(.txt)
names = os.listdir(args.input_annotation_txt_dir)
#标注的框的宽和高
annotations_w_h = []
for name in names:
txt_path = os.path.join(args.input_annotation_txt_dir,name)
#读取txt文件中的每一行
f = open(txt_path,'r')
for line in f.readlines():
line = line.rstrip('\n')
w,h = line.split(' ')[3:]#这时读到的w,h是字符串类型
#eval()函数用来将字符串转换为数值型
annotations_w_h.append((eval(w),eval(h)))
f.close()
#将列表annotations_w_h转换为numpy中的array,尺寸是(N,2),N代表多少框
annotations_array = np.array(annotations_w_h,dtype=np.float32)
N = annotations_array.shape[0]
#对于k-means聚类,随机初始化聚类点
random_indices = [random.randrange(N) for i in range(num_clusters)]#产生随机数
centroids = annotations_array[random_indices]
#k-means聚类
k_means(annotations_array,centroids,0.00005,200000)
#对centroids按照宽排序,并写入文件
widths = centroids[:,0]
sorted_indices = np.argsort(widths)
anchors = centroids[sorted_indices]
#将anchor写入文件并保存
f_anchors = open(args.output_anchors_txt,'w')
#
for anchor in anchors:
f_anchors.write('%d,%d'%(int(anchor[0]*args.input_cfg_width),int(anchor[1]*args.input_cfg_height)))
f_anchors.write('\n')
执行语句如下:
python kmean.py --input_annotation_txt_dir data/labels --output_anchors_txt 123456.txt --input_num_anchors 9 --input_cfg_width 640 --input_cfg_height 320结果文件如下:
12,15
14,20
18,25
24,32
24,18
33,44
39,28
59,49
115,72将它写入cfg中吧
3.修改代码:
这里感觉坑多些,例如它在train.py里写了个超参数列表,cfg里的某些值配置就不生效了。
我想改batch大小需要在train.py这个文件里改。。。。默认16...
parser.add_argument('--batch-size', type=int, default=16) # effective bs = batch_size * accumulate = 16 * 4 = 64其他还有很多,如是否是单目标检测还是多目标检测的设置。
parser.add_argument('--single-cls', action='store_false', help='train as single-class dataset')优化方法选择sgd还是adam
parser.add_argument('--adam', action='store_true', help='use adam optimizer')学习率,如果用adam会发现,如果看训练效果loss降的特别慢,看上去一直很大,就把这行打开,降低学习率看看吧
#hyp['lr0'] *= 0.1 # reduce lr (i.e. SGD=5E-3, Adam=5E-4)关键问题:有些设置在上面代码里设置了还不生效。。。。
例如,它默认是单目标检测我给改成多目标检测了,训练还是不对,后来发现参数值没生效,最后强制设置其生效了。。。。
4.训练:自己酌情去改输入吧
python train.py --data data/rbc.data --cfg cfg/yolov3.cfg --epochs 20005.训练中最常见错误:
爆显存,修改方法就是减小batchsize的大小吧。
里面加载了预训练模型,自己下载一个路径根据参数设置放好了就行,例如yolov3对应的yolov3.weights文件
parser.add_argument('--weights', type=str, default='weights/yolov3.weights', help='initial weights path')6.预测:
python detect.py --cfg cfg/yolov3-tiny.cfg --weights weights/best.pt预测碰到的坑:用两台电脑干活,一台训练,一台测试,结果报错:
RuntimeError: Error(s) in loading state_dict for Darknet原因:pytorch版本不同引进的错误
修改方法:在detect.py中将加载模型部分修改下,原理没去深学,参考大神做法
将model.load_state_dict(torch.load(weights, map_location=device)['model'])
改为:
model.load_state_dict(torch.load(weights, map_location=device)['model'], False)7.用opencv调起来岂不是很爽。
1.具体看参考文献5里面介绍很详细,我搬运一下,里面有一处错误,直接用你会发现,嘿嘿,检测结果又可信度还挺高,框的什么玩意O(∩_∩)O,已修改。上面训练的结果是best.pt,而下面vs2017工程是调用的.weights文件。转换方法代码里就有,在modle.py下有个save_weights函数,可以直接用它转换。我设定的转换完了就是best.pt变成了converted.weights。剩下的几个就是绝对路径了,具体读啥文件自己去看好了。在modle.py最后加上这个,就将pt文件转换为weights文件了。
if __name__ == '__main__':
cfg='cfg/yolov3.cfg'
weights='last136.pt'
model = Darknet(cfg)
if weights.endswith('.pt'): # if PyTorch format
model.load_state_dict(torch.load(weights, map_location='cpu')['model'], False)
save_weights(model, path='converted.weights', cutoff=-1)
print("Success: converted '%s' to 'converted.weights'" % weights)2.注意一点,下面这个对图像放缩的方法与yolov3的方法不一致,这个应该改一下,我犯懒没改。。。没改的结果就是检测不出目标来。我用的1280*720的图,将其按512放缩,结果放缩图恰好是512*288 符合32的倍数。记住一点,缩放的目的是将图的长和宽缩放成32的倍数,且不能改原图比例关系(形变是不允许的)。那么一般都需要按行或列缩放,然后在其中一个方向做填充,填成32的倍数。随手写了段代码,但是忽然发现,我用不到,放上吧有空填充齐了。
void YoloResize(Mat in, Mat &out)
{
int w = in.cols;
int h = in.rows;
int target_w = 512;
int target_h = 512;
float ratio0 = (float)target_w / w;
float ratio1 = (float)target_h / h;
float scale = min(ratio0, ratio1);//转换的最小比例
//保证长或宽,至少一个符合目标图像的尺寸
int nw = int(w * scale);
int nh = int(h * scale);
//缩放图像
cv::resize(in, out, cv::Size(nw, nh), (0, 0),(0, 0),cv::INTER_CUBIC);
//设置输出图像大小,凑足32的倍数。将缩放好的图像放在输出图中间。
if (ratio0 <= ratio1)//
{
//上下填充
int addh = nh % 32;
int newh = nh + addh;
}
else
{
//左右填充
}
}
完整调用代码在此
// This code is written at BigVision LLC.
//It is subject to the license terms in the LICENSE file found in this distribution and at http://opencv.org/license.html
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace dnn;
using namespace std;
// Initialize the parameters
float confThreshold = 0.5; // Confidence threshold
float nmsThreshold = 0.4; // Non-maximum suppression threshold
int inpWidth = 512; // Width of network's input image
int inpHeight = 192; // Height of network's input image
vector classes;
// Remove the bounding boxes with low confidence using non-maxima suppression
void postprocess(Mat& frame, const vector& out);
// Draw the predicted bounding box
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame);
// Get the names of the output layers
vector getOutputsNames(const Net& net);
int main(int argc, char** argv)
{
//*
string classesFile = "E:\\LL\\rbc.names";
ifstream ifs(classesFile.c_str());
string line;
while (getline(ifs, line)) classes.push_back(line);
// Give the configuration and weight files for the model
String modelConfiguration = "E:\\LL\\yolov3_new.cfg";
String modelWeights = "E:\\LL\\converted.weights";
// Load the network
Net net = readNetFromDarknet(modelConfiguration, modelWeights);
net.setPreferableBackend(DNN_BACKEND_OPENCV);
net.setPreferableTarget(DNN_TARGET_CPU);
// Open a video file or an image file or a camera stream.
string str, outputFile;
//VideoCapture cap("E:\\SSS.mp4");
VideoWriter video;
Mat frame, blob;
// Create a window
static const string kWinName = "Deep learning object detection in OpenCV";
namedWindow(kWinName, WINDOW_NORMAL);
// Process frames.
while (waitKey(1) != 27)
{
// get frame from the video
//cap >> frame;
frame = imread("E:\\LL\\1.jpg");
// Stop the program if reached end of video
if (frame.empty()) {
//waitKey(3000);
break;
}
// Create a 4D blob from a frame.
cout << "inpWidth = " << inpWidth << endl;
cout << "inpHeight = " << inpHeight << endl;
blobFromImage(frame, blob, 1 / 255.0, cv::Size(inpWidth, inpHeight), Scalar(0, 0, 0), true, false);
//Sets the input to the network
net.setInput(blob);
// Runs the forward pass to get output of the output layers
vector outs;
net.forward(outs, getOutputsNames(net));
// Remove the bounding boxes with low confidence
postprocess(frame, outs);
// Put efficiency information. The function getPerfProfile returns the overall time for inference(t) and the timings for each of the layers(in layersTimes)
vector layersTimes;
double freq = getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
string label = format("Inference time for a frame : %.2f ms", t);
putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 255));
// Write the frame with the detection boxes
Mat detectedFrame;
frame.convertTo(detectedFrame, CV_8U);
imshow(kWinName, frame);
waitKey(100000);
}
//cap.release();
//*/
return 0;
}
// Remove the bounding boxes with low confidence using non-maxima suppression
void postprocess(Mat& frame, const vector& outs)
{
vector classIds;
vector confidences;
vector boxes;
for (size_t i = 0; i < outs.size(); ++i)
{
// Scan through all the bounding boxes output from the network and keep only the
// ones with high confidence scores. Assign the box's class label as the class
// with the highest score for the box.
float* data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols)
{
Mat scores = outs[i].row(j).colRange(5, outs[i].cols);
Point classIdPoint;
double confidence;
// Get the value and location of the maximum score
minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (confidence > 0)
{
confidence = confidence;
}
if (confidence > confThreshold)
{
int centerX = (int)(data[0] * frame.cols);
int centerY = (int)(data[1] * frame.rows);
int width = (int)(data[2] * frame.rows);
int height = (int)(data[3] * frame.cols);
int left = centerX - width / 2;
int top = centerY - height / 2;
classIds.push_back(classIdPoint.x);
confidences.push_back((float)confidence);
boxes.push_back(Rect(left, top, width, height));
}
}
}
// Perform non maximum suppression to eliminate redundant overlapping boxes with
// lower confidences
vector indices;
NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); ++i)
{
int idx = indices[i];
Rect box = boxes[idx];
drawPred(classIds[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
}
// Draw the predicted bounding box
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame)
{
//Draw a rectangle displaying the bounding box
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(255, 178, 50), 3);
//Get the label for the class name and its confidence
string label = format("%.2f", conf);
if (!classes.empty())
{
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ":" + label;
}
//Display the label at the top of the bounding box
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
rectangle(frame, Point(left, top - round(1.5*labelSize.height)), Point(left + round(1.5*labelSize.width), top + baseLine), Scalar(255, 255, 255), FILLED);
putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0, 0, 0), 1);
}
// Get the names of the output layers
vector getOutputsNames(const Net& net)
{
static vector names;
if (names.empty())
{
//Get the indices of the output layers, i.e. the layers with unconnected outputs
vector outLayers = net.getUnconnectedOutLayers();
//get the names of all the layers in the network
vector layersNames = net.getLayerNames();
// Get the names of the output layers in names
names.resize(outLayers.size());
for (size_t i = 0; i < outLayers.size(); ++i)
names[i] = layersNames[outLayers[i] - 1];
}
return names;
}
上个结果图看看

检测的目标是个限速牌。
8.一切为了速度:openvino加速方法来也。
貌似openvino不支持darknet,找找转换的方法吧。继续~~
https://www.cnblogs.com/jsxyhelu/p/11340822.html mark一下
参考文献:
1. https://blog.csdn.net/zhangping1987/article/details/84942680 anchors计算
2.https://blog.csdn.net/sinat_34054843/article/details/88046041 导入模型错误解决方法
3.https://codeload.github.com/zqfang/YOLOv3_CPP/zip/master yolov3的C++代码
4.https://blog.csdn.net/sue_kong/article/details/104401008 出错处理,安装opencv4.0的时候
5.https://blog.csdn.net/zmdsjtu/article/details/81913927 opencv调用编好的网络权值做预测
6.https://blog.csdn.net/hzqgangtiexia/article/details/80509211 关于学习率的问题
7.https://www.cnblogs.com/lvdongjie/p/11270447.html 也是学习率
未完,待续......
带货:yolov3损失函数https://www.optbbs.com/thread-5590827-1-1.html
yolov3 损失函数https://www.cnblogs.com/pprp/p/12590801.html
https://www.cnblogs.com/king-lps/p/9497836.html 讲解focalloss的