
首发于 Vulkan 学习指南
关注专栏 写文章

第 8 章 管线以及管线状态管理
在上一章中,我们理解了 Vulkan 中的缓冲区资源,并使用它在物理设备内存上以顶点缓冲区的形式存储几何图形数据信息。 我们实现了一个 Render Pass 和 framebuffer 对象。 此外,我们知道了 SPIR-V,这是 Vulkan 中指定着色器的一种新方法。 此外,我们使用 SPIR-V 工具库在编译时将 GLSL 着色器转换为 SPIR-V 中间语言。
之前学到的内容先告一段落,在这一章中, 我们将理解管线和管线状态管理的概念。 在本章中,我们会介绍一下 Vulkan API 支持的管线类型。 有两种类型的管线:计算和图形。 这些管线是使用管线缓存对象创建的,这是下一个主题。 在本章结束时,我们将实现图形管线,并彻底了解与之相关的管线状态的各种类型。.
在本章中,我们将涵盖以下主题:
- 管线入门
- 使用管线缓存对象 pipeline cache object(PCO)缓存管线对象
- 创建图形管线
- 了解计算管线
- Vulkan 中的管线状态对象
- 实现管线
管线入门
管线是指数据输入流经的一系列固定阶段;每个阶段都处理传入的数据并将其传递到下一个阶段。 最终产品或是一个 2D 栅格绘图图像(图形管线),或是 使用计算逻辑和计算操作(计算管线)更新后的资源(缓冲区或图像)。
Vulkan 支持两种类型的管线,即图形和计算。
- 图形管线:graphics pipeline,该管线通过命令缓冲区接收若干 Vulkan 命令并绘制 2D / 3D 场景的 2D 光栅化图像。
- 计算管线:compute pipeline,该管线通过命令缓冲区接收 Vulkan 命令并处理它们以进行相关的计算工作。
如下的图示(来自 Vulkan 官方规范(https://www.khronos.org/registry/vulkan/specs/1.0/xhtml/vkspec.html#pipelines-block- diagram)显示了 Vulkan 图形管线和计算管线:
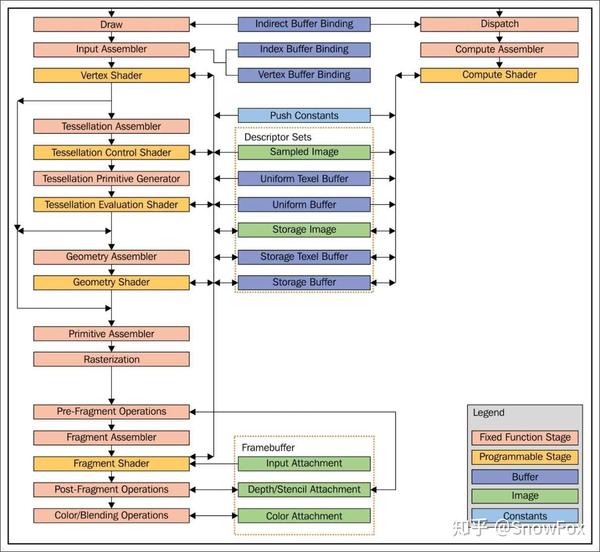

管线行程从 Input Assembler开始,输入的顶点数据根据指定的基本拓扑结构以点、线和三角形的形式进行组装。 使用顶点着色器 Vertex Shader可编程阶段,输入的顶点数据被转换到一个剪辑空间。 几何图形在Tessellation Control Shader和Tessellation Evaluation Shader装配器中进行细分。 几何图形着色器 Geometry Shader 具有从单个传入图元中生成多个图元的独特功能。
接下来,Primitive Assembler从前一阶段获取转换过的所有坐标,并按照输入阶段提供的指定绘图操作或原始类型(点,线和三角形)信息有序地对它们进行排列。 当关联的顶点坐标落在视景体之外时,图元就会被裁剪掉,当发生这种情况时,裁剪掉的片段(视野之外)会被丢弃。
栅格化 Rasterization 是将变换后的屏幕空间图元(点,线和三角形)转换为称之为片段的离散元素的过程。 这些片段由下一个阶段控制,称为片段着色器 Fragment Shader。 片段着色器在单个片段上执行计算。 这些片段最终会成为帧缓冲区的一部分,这个帧缓冲区全部经历了大量条件的更新,例如深度测试,模版测试和片段混合。
缓冲区和图像内存类型可以以 1D / 2D / 3D 工作组的形式 (称为计算管线)在一个单独的管线中进行处理。 计算管线在并行处理过程中完成工作的能力是非常强大的;它主要用于图像处理和物理计算领域。 计算管线可以修改(读取 / 写入)缓冲区和图像内存。
该管线大致由三个概念组成:管线状态对象,管线缓存对象和管线布局。 这些可用于有效控制底层管线的操作:
- 管线状态对象(PSO):Pipeline state objects (PSO),物理设备或 GPU 能够直接在硬件中执行多种操作。 这些操作可能包括光栅化器和条件更新,例如混合深度测试,模版测试等。 Vulkan 在 PSO 的帮助下提供了控制这些硬件设置的能力。 其他基于硬件的操作可能包括:在给定的几何形状上组装基本拓扑类型(点 / 线 / 三角形),视口控制等。
- 管线缓存对象(PCO):Pipeline cache objects (PCOs),管线缓存提供了更快地检索和重用存储过的管线的一种机制。 这为应用程序避免创建类似或重复的冗余管线对象提供了一个更好机会。
- 管线布局:Pipeline layouts,缓冲区和图像被间接连接到着色器,可以使用着色器资源变量对其进行访问。 资源变量被连接到缓冲区视图和图像视图, 这些资源变量通过描述符和描述符集布局进行管理。 在管线内,管线布局管理一系列的描述符集布局。
注意
描述符是存储的资源和着色器阶段之间的接口。 资源连接到由描述符集布局定义的逻辑布局绑定,并且管线布局提供对管线内描述符集的访问。 描述符会在第 10 章“描述符和 Push 常量”中详细介绍,我们还会在这里学习使用 uniform。
VulkanPipeline- 管线实现类
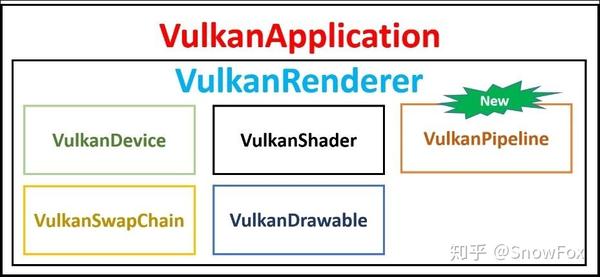
在本章中,我们将介绍一个名为 VulkanPipeline 的用户定义类。 该类会管理 Vulkan 应用程序的管线实现。 由于这个类要处理大量的管线状态管理对象,因此管线创建是性能关键点;因此,管线对象的可重用性是非常重要的。 Vulkan 管线通过 PCO 提供管线缓存机制。 这减少了创建类似管线的开销 - 驱动程序会寻找比较接近的匹配,并使用基本管线创建新管线。
管线的实现必须放置在绘制对象可以轻松访问 PCO 的集中位置,以提高管线可重用性。 为此,有两种选择:将 VulkanPipeline 类放置在 VulkanApplication 内(在应用程序级别,这可能是主线程)或 VulkanRenderer 内(用于每个独立的渲染线程)。 只要应用程序能够通过正确处理内存泄漏和线程同步合理地管理管线对象,那么这两个选项使用哪个都可以。 本书遵循后一个选项,因此我们将 VulkanPipeline 放置在 VulkanRenderer 中以避免线程的同步,使其对初学者来说更简单一些。
以下框图显示了一个图形视图,该视图表示应用程序系统与用户定义的 VulkanPipeline 类的集成:

以下是 VulkanPipeline 头文件(VulkanPipeline.h)的声明:
/************ VulkanPipeline.h ************/
class VulkanPipeline
{
public:
// Creates the pipeline cache object and stores pipeline object
void createPipelineCache();
// Returns the created pipeline object, it takes the drawable
// object which contains the vertex input rate and data
// interpretation information, shader files, Boolean flag to
// check depth is supported or not, and a flag to check if the
// vertex input are available.
bool createPipeline(VulkanDrawable* drawableObj, VkPipeline* pipeline, VulkanShader* shaderObj,
VkBool32 includeDepth, VkBool32 includeVi = true);
// Destruct the pipeline cache object
void destroyPipelineCache(); public:
// Pipeline cache object
VkPipelineCache pipelineCache;
// References to other user defined class
VulkanApplication* appObj;
VulkanDevice* deviceObj;
};
头文件声明包含了一些辅助函数,它允许您创建管线缓存对象(VkPipelineCache)并生成管线(VkPipeline)。
使用 PCO 缓存管线对象 pipeline objects
管线缓存是一个用于存储管线的池, 它使应用程序能够减少管线运行之间以及后续应用程序运行之间的管线创建开销。 以下是两者之间的区别:
- 管线 pipelines 之间:当新的管线被创建时,管线构造是可以重用的。 管线缓存对象作为参数传递给管线创建器 API(vkCreateGraphicsPipelines)。 通过这样做,底层的机制可确保在存在类似的管线时能够对其进行重用。 这在创建本质上是冗余的绘图对象时非常有用,例如绘画画笔,精灵,网格几何体等等。
- 在应用程序 applications 之间:在创建管线时,会处理大量的管线状态对象,这是一种昂贵的操作。 在正在运行的应用程序中重用是一个明智的设计,并且在执行时间和内存空间方面非常高效。 Vulkan 应用程序中的管线缓存可以通过序列化管线缓存对象来有效地进行重用。 应用程序从序列化的管线缓存中检索存储的管线对象并对其进行预初始化。 在后续运行中,可以在多个应用程序运行中重复使用相同的序列化 PCO。
有关管线缓存对象的规范和实现的更多信息,请参阅以下小节。
创建管线缓存对象 pipeline cache object
PCO 可用于创建图形管线(vkCreateGraphicsPipelines)或计算管线(vkCreateComputePipelines)。 使用 PCO 创建这些管线可确保管线对象的可重用性。 如果 PCO 不包含类似的管线,则会创建一个新的管线并将其添加到它的池中。
可以使用 vkCreatePipelineCache()API 创建 PCO。 在成功创建后,会返回一个 VkPipelineCache 对象。 此 API 接受四个参数,如下所述:
VkResult vkCreatePipelineCache(
VkDevice device,
const VkPipelineCacheCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkPipelineCache* pPipelineCache);
以下是 vkCreatePipelineCache()API 接受的各种参数:
参数 | 描述
—|---
device | 这是用于创建管线缓存对象(VkPipelineCache)的一个逻辑设备(类型为 VkDevice)对象。
pCreateInfo | 这是 VkPipelineCacheCreateInfo 控制结构,其中包含用于创建 PCO 对象的元数据或状态信息。
pAllocator | 这控制主机内存的分配。 有关更多信息,请参阅第 5 章“Vulkan 中的命令缓冲区以及内存管理”中的“主机内存”部分。 pPipelineCache | 这个返回 创建的 VkPipelineCache 对象的指针。
vkCreatePipelineCache()API 的第二个参数是 VkPipelineCacheCreateInfo 类型;此控制结构包含创建和初始化管线缓存对象所需的状态、元数据信息。 以下是这个结构的语法:
typedef struct VkPipelineCacheCreateInfo {
VkStructureType sType;
const void* pNext;
VkPipelineCacheCreateFlags flags;
size_t initialDataSize;
const void* pInitialData;
} VkPipelineCacheCreateInfo;
我们来看看这个结构的各个字段:
字段 | 描述
—|---
sType | 这是控制结构的类型信息。必须被指定为 VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO。
pNext | 这可以是指向扩展特定结构的有效指针或 NULL。
flags | 该字段保留供将来使用。
initialDataSize | 这是 initialData 指示的数据长度(以字节为单位)。 如果此字段值为 0,则表示管线缓存最初会为空。 然后 pInitialData 会被忽略。
pInitialData | 该字段表示从先前创建的管线缓存中检索到的数据。 这将用于初始化新创建的管线缓存对象的内容。 如果 pInitialData 的数据与设备不兼容,则创建的管线缓存对象的初始化内容可能会保持为空。
合并管线缓存 pipeline caches
使用 vkMergePipelineCaches()API 可以将两个管线缓存合并为一个。 该 API 将目标管线缓存合并到源管线缓存中。 它需要用到四个参数。 第一个参数 device 是要进行合并的逻辑设备。 源管线缓存的数量由 pSrcCaches 指定,计数等于 srcCacheCount。 最终合并的缓存存储在目标管线缓存中,名为 dstCache。
以下是此 API 的语法:
VkResult vkMergePipelineCaches(
VkDevice device,
VkPipelineCache dstCache,
uint32_t srcCacheCount,
const VkPipelineCache* pSrcCaches);
从管线缓存 pipeline caches 检索数据
管线缓存对象可以以字节流的形式保存其信息。 当应用程序重新运行或再次执行时,这些存储的信息可以在以后重用。 管线缓存数据可以使用 vkGetPipelineCacheData()API 检索:
VkResult vkGetPipelineCacheData(
VkDevice device,
VkPipelineCache pipelineCache,
size_t* dataSize,
void* data);
下表描述了此 API 的每个参数:
参数 | 描述
—|---
device | 这是指用于创建管线缓存对象的逻辑设备。 pipelineCache | 这是要从中检索数据的管线缓存对象。
dataSize | 当 data 为 NULL 时,此字段用于从 pipelineCache 对象查询以字节为单位的管线缓存数据的大小。
data | 当 dataSize 不为零时,此 API 从 pipelineCache 对象读取 dataSize 字节并检索数据。
在应用程序启动时,存储的 PCO 信息可以重新用于预初始化和填充管线缓存对象。 编译结果可能取决于供应商和其他设备的细节。 为了确保应用程序与管线缓存数据兼容,可以使用信息头。
检索到的数据包含一个头部和一个有效载荷。 头部提供了有关写入数据的必要信息,以确保下次应用程序运行时具有兼容性。 下图显示了存储的管线缓存对象的格式:


头部由五个字段组成,这些字段可以按照规范要求发生调整。 按照规范,头部大小不是固定的,而是从数据中读取前四个字节。 该字节信息会对整个管线缓存对象的检索数据头的长度(以字节为单位)进行编码,包括头部中的每个字段。
下表说明了这些字段的规格及其大小(以字节为单位):
偏移量 Offset | 大小 Size | 说明 -
–|—|---
0 | 4 | 这指定了管线缓存头的字节长度,使用最少有效字节写入的这 4 个字节的信息数组位于序列中的首位。
4 | 4 | 这表示管线缓存的头部版本(VkPipelineCacheHeaderVersion)。 这是使用最少有效字节的一个字节数组,放置在前面。
8 | 4 | 这个字段指定了供应商 ID,它与 VkPhysicalDeviceProperties :: vendorID 相同。 这是使用最少有效字节的一个 4 字节数组,放置在前部。
12 | 4 | 这指定了设备 ID,它与 VkPhysicalDeviceProperties :: deviceID 相同。 这也是使用最少有效字节的一个 4 字节数组,放置在前部。
16 | 4 | 这指定了表示管线缓存对象的唯一标识符。 ID 等于 VkPhysicalDeviceProperties:: pipelineCacheUUID。
实现 PCO
PCO 在 VulkanPipeline.cpp 的 createPipelinceCache()函数中实现。 VkPipelineCacheCreateInfo 被初始化并传递给 vkCreatePipelineCache()API。 initialDataSize 为 0,pInitialData 为 NULL,因为没有旧的数据,因此在创建的 PCO 的初始化中会使用可检索的 PCO 数据:
void VulkanPipeline::createPipelineCache()
{
VkResult result;
VkPipelineCacheCreateInfo pipelineCacheInfo; pipelineCacheInfo.sType = VK_STRUCTURE_TYPE_PIPELINE
_CACHE_CREATE_INFO;
pipelineCacheInfo.pNext = NULL; pipelineCacheInfo.initialDataSize = 0; pipelineCacheInfo.pInitialData = NULL; pipelineCacheInfo.flags = 0;
// Create the pipeline cache using VkPipelineCacheCreateInfo
result = vkCreatePipelineCache(deviceObj->device, &pipelineCacheInfo, NULL, &pipelineCache);
assert(result == VK_SUCCESS);
}
创建图形管线 graphics pipeline
图形管线由可编程的固定功能管线阶段,渲染通道,子通道以及管线布局组成。 可编程阶段包括多个着色器阶段,例如顶点着色器、片段着色器、表面细分着色器、几何着色器和计算着色器。 固定功能的状态由多个管线状态对象 pipeline state objects (PSO)组成,这些对象表示动态的信息:顶点输入,输入的装配,光栅化,混合,视口,多重采样和深度模板状态。
使用 vkCreateGraphicsPipelines()API 创建图形管线对象(VkPipeline)。 该 API 会通过名为 VkGraphicsPipelineCreateInfo 的元数据控制结构影响可编程阶段,固定功能管线阶段和管线布局。 以下是 vkCreateGraphicsPipelines()API 的语法:
VkResult vkCreateGraphicsPipelines(
VkDevice device,
VkPipelineCache pipelineCache,
uint32_t createInfoCount,
const VkGraphicsPipelineCreateInfo* pCreateInfos,
const VkAllocationCallbacks* pAllocator,
VkPipeline* pPipelines);
我们来看看 vkCreateGraphicsPipelines()API 的各个参数:
参数 | 描述 -
–|—
device | 这是要创建管线对象的逻辑设备。 pipelineCache | 这是一个指向管线缓存对象的有效指针。 如果此值为 NULL,则不会使用管线缓存创建管线对象。
createInfoCount | 这表示 pCreateInfos 数组中的图形管线(VkGraphicsPipelineCreateInfo)的数量。
pCreateInfos | 这是 VkGraphicsPipelineCreateInfo 数组。
pAllocator | 该参数控制主机内存的分配。 有关更多信息,请参阅第 5 章“Vulkan 中的命令缓冲区以及内存管理”中的“主机内存”部分。
pPipelines | 这将返回包含图形管线对象的 VkPipeline 对象数组。 对象的数量取决于 createInfoCount。
这是我们前面讨论过的元数据控制结构 VkGraphicsPipelineCreateInfo 的语法:
typedef struct VkGraphicsPipelineCreateInfo { VkStructureType sType;
const void* pNext;
VkPipelineCreateFlags flags;
uint32_t stageCount;
const VkPipelineShaderStageCreateInfo* pStages;
const VkPipelineVertexInputStateCreateInfo* pVertexInputState; const VkPipelineInputAssemblyStateCreateInfo* pInputAssemblyState; const VkPipelineTessellationStateCreateInfo* pTessellationState; const VkPipelineViewportStateCreateInfo* pViewportState; const VkPipelineRasterizationStateCreateInfo* pRasterizationState; const VkPipelineMultisampleStateCreateInfo* pMultisampleState; const VkPipelineDepthStencilStateCreateInfo* pDepthStencilState; const VkPipelineColorBlendStateCreateInfo* pColorBlendState; const VkPipelineDynamicStateCreateInfo* pDynamicState; VkPipelineLayout layout;
VkRenderPass renderPass;
uint32_t subpass;
VkPipeline basePipelineHandle;
int32_t basePipelineIndex;
} VkGraphicsPipelineCreateInfo;
我们来看看这个结构的各个字段:
参数 | 描述
—|---
sType | 这是这个控制结构的类型信息。 必须指定为 VK_STRUCTURE_TYPE_GRAPHICS_PIPELINE_CREATE_INFO。
pNext | 这可能是指向扩展特定结构的有效指针或 NULL。
flags | 该参数提供了一些提示,以帮助实现了解管线会如何生成。 这些提示是使用 VkPipelineCreateFlagBits 枚举提供的。
VkPipelineCreateFlagBits 枚举有三个字段:
VK_PIPELINE_CREATE_DISABLE_OPTIMIZATION_BIT:使用该标志创建的管线不会被优化。 由于没有优化路径,因此可以减少创建这种管线的总体时间。
VK_PIPELINE_CREATE_ALLOW_DERIVATIVES_BIT:使用此标志创建的管线允许成为将被创建(使用 vkCreateGraphicsPipelines()API)的后续管线的父级。VK_PIPELINE_CREATE_DERIVATIVE_BIT:使用此标志创建的管线会成为先前创建的管线的子节点。
stageCount | 这表示要在当前管线中使用的着色器数量。
pStages | 该字段表示需要包含在管线中的所有着色器阶段 ------ 使用一个 VkPipelineShaderStageCreateInfo 数组,数组的总大小等于 stageCount。
pVertexInputState | 该字段表示顶点输入管线状态 ------ 通过 VkPipelineVertexInputStateCreateInfo 指针对象。
pInputAssemblyState | 该字段用来确定输入装配状态的行为 ------ 使用 VkPipelineInputAssemblyStateCreateInfo 指针对象。
pTessellationState | 该字段表示细分控制和评估着色器阶段的状态。 这些状态是使用 VkPipelineTessellationStateCreateInfo 指针对象指定的。 如果细分控制和评估着色器阶段未包含在管线中,则该值必须为 NULL。
pViewportState | 该字段指示顶点状态 ------ 通过 VkPipelineViewportStateCreateInfo 指针对象。 如果管线禁用光栅化,则此字段必须为 NULL。 pRasterizationState | 该字段表示管线栅格化状态 ------ 使用 VkPipelineRasterizationStateCreateInfo 结构的指针对象。
pMultisampleState | 这引用的是 VkPipelineMultisampleStateCreateInfo 对象指针。 如果管线禁用光栅化,则此字段必须为 NULL。
pDepthStencilState | 该字段指示管线的深度、模板状态 ------ 通过使用一个指向 VkPipelineDepthStencilStateCreateInfo 控制结构的指针。 如果禁用光栅化或 Render Pass 中的子通道未使用深度、模板附件,则该值为 NULL。
pColorBlendState | 这是指向 VkPipelineColorBlendStateCreateInfo 的一个指针,指示管线颜色的混合状态。如果管线已禁用光栅化,或者 Render Pass 中的子通道未使用任何颜色附件,则此字段必须为 NULL。
pDynamicState | 这是指向 VkPipelineDynamicStateCreateInfo 的指针,指示管线的动态状态。 该字段可以独立于其他管线状态进行更改。 如果未指定动态的状态,则可以将此字段指定为 NULL,通知管线在此管线中不存在要考虑的动态状态。
layout | 该字段指定管线和描述符集使用的绑定位置。
renderPass | 该字段指定将由管线使用的子通道和附件。
subPass | 这个用来通知管线关于 Render Pass 的子通道索引,管线中会用到这个索引。
basePipelineHandle | 该字段指定了基本管线,从它可以派生出其他的管线。
basePipelineIndex | 该字段指定基本管线中 pCreateInfos 参数的索引, 会用来派生管线对象。
实现图形管线 graphics pipeline
图形管线在 VulkanPipeline 的 createPipeline()函数中实现。 该函数需要四个参数。 第一个参数包含顶点输入和数据解析。 第二个参数包含返回值,会在其中创建管线数组。 第三个参数是一个表示深度测试的布尔标志。 最后一个参数用于指定是否考虑顶点输入。
图形管线由几个管线状态对象,渲染通道,着色器对象和子通道组成,如下图所示。 通过创建 VkGraphicsPipelineCreateInfo 对象(pipelineInfo)并在其中指定所有的各种状态对象,着色器对象以及渲染通道对象来完成管线的实现。 最后,vkCreateGraphicsPipelines()API 使用管线对象创建管线。 下图显示了图形管线及其所有的接口控制器:


这是图形管线对象的代码实现:
bool VulkanPipeline::createPipeline(VulkanDrawable* drawableObj, VkPipeline* pipeline, VulkanShader* shaderObj, VkBool32 includeDepth, VkBool32 includeVi)
{
// Please refer to Dynamic State for more info
VkPipelineDynamicStateCreateInfo dynamicState = {};
// Please refer to Vertex Input States subsection for more info
VkPipelineVertexInputStateCreateInfo vertexInputStateInfo = {};
. . .
// Please refer to Input Assembly States subsection for more info
VkPipelineInputAssemblyStateCreateInfo inputAssemblyInfo = {};
// Please refer to Rasterization State subsection for more info
VkPipelineRasterizationStateCreateInfo rasterStateInfo = {};
// Please refer to Color Blend Attachment for more info
VkPipelineColorBlendAttachmentState
colorBlendAttachmentStateInfo[1] = {};
// Please refer to Color Blend State subsection for more info
VkPipelineColorBlendStateCreateInfo colorBlendStateInfo = {};
// Please refer to Viewport State subsection for more info
VkPipelineViewportStateCreateInfo viewportStateInfo = {};
// Please refer to Depth Stencil state subsection for more info
VkPipelineDepthStencilStateCreateInfo depthStencilStateInfo = {};
// Please refer to Multi Sample state subsection for more info
VkPipelineMultisampleStateCreateInfo multiSampleStateInfo = {};
// Populate the VkGraphicsPipelineCreateInfo structure to specify
// programmable stages, fixed- function pipeline stages render
// pass, sub- passes and pipeline layouts VkGraphicsPipelineCreateInfo pipelineInfo = {}; pipelineInfo.sType =
VK_STRUCTURE_TYPE_GRAPHICS_PIPELINE_CREATE_INFO;
pipelineInfo.pVertexInputState = &vertexInputStateInfo; pipelineInfo.pInputAssemblyState = &inputAssemblyInfo; pipelineInfo.pRasterizationState = &rasterStateInfo; pipelineInfo.pColorBlendState = &colorBlendStateInfo; pipelineInfo.pTessellationState = NULL; pipelineInfo.pMultisampleState = &multiSampleStateInfo; pipelineInfo.pDynamicState = &dynamicState; pipelineInfo.pViewportState = &viewportStateInfo; pipelineInfo.pDepthStencilState = &depthStencilStateInfo; pipelineInfo.pStages = shaderObj->shaderStages;
pipelineInfo.stageCount = 2;
pipelineInfo.renderPass = appObj->rendererObj-> renderPass;
pipelineInfo.subpass = 0;
// Create the pipeline using the meta- data store in the
// VkGraphicsPipelineCreateInfo object
if (vkCreateGraphicsPipelines(deviceObj->device, pipelineCache, 1, &pipelineInfo, NULL, pipeline) == VK_SUCCESS){
return true;
}
else {
return false;
}
}
销毁管线 pipelines
创建的管线可以使用 vkDestroyPipeline API 销毁。 这个 API 接受三个参数。 第一个参数指定要用来销毁管线的逻辑设备(VkDevice)。 第二个参数是一个 pipeline 对象(VkPipeline),这个对象会被销毁。 第三个参数 pAllocator 控制主机的内存分配。 有关更多信息,请参阅的第 5 章“Vulkan 中的命令缓冲区以及内存管理”中的“主机内存”部分:
void vkDestroyPipeline(
VkDevice device,
VkPipeline pipeline,
const VkAllocationCallbacks* pAllocator);
理解计算管线 compute pipelines
计算管线由一个静态的计算着色器阶段和管线布局组成。 计算着色器阶段能够任意进行大规模并行计算。 另一方面,管线布局使用布局绑定将计算管线连接到描述符。 vkCreateComputePipeline()API 可用于创建计算管线:
VkResult vkCreateComputePipelines(
VkDevice device,
VkPipelineCache pipelineCache,
uint32_t createInfoCount,
const VkComputePipelineCreateInfo* pCreateInfos,
const VkAllocationCallbacks* pAllocator,
VkPipeline* pPipelines);
下表介绍了 vkCreateGraphicsPipelines()API 的各个参数:
参数 | 描述
—|---
device | 这是将从中创建计算管线对象的逻辑设备(VkDevice)。 pipelineCache | 这是一个指向管线缓存对象的有效指针。 如果此值为 NULL,则该管线缓存将不会用于创建计算管线对象。
createInfoCount | 这表示 pCreateInfos 数组中计算管线的数量(VkComputePipelineCreateInfo)。
pCreateInfos | 这是指 VkComputePipelineCreateInfo 结构数组的对象。
pAllocator | 该参数控制主机内存的分配。 有关更多信息,请参阅第 5 章“Vulkan 中的命令缓冲区以及内存管理”中的“主机内存”部分。
pPipelines | 这将返回 VkPipeline 对象数组,其中包含创建的计算管线的数量。
VkComputePipelineCreateInfo 结构定义了由 vkCreateComputePipelines()API 用于创建计算管线对象的、计算管线的状态信息。 这个 API 的语法如下:
typedef struct VkComputePipelineCreateInfo {
VkStructureType type;
const void* next;
VkPipelineCreateFlags flags;
VkPipelineShaderStageCreateInfo stage;
VkPipelineLayout layout;
VkPipeline basePipelineHandle;
int32_t basePipelineIndex;
} VkComputePipelineCreateInfo;
我们来看看 VkComputePipelineCreateInfo 结构的各个字段:
字段 | 描述
—|---
sType | 这是 VkComputePipeline-CreateInfo 结构的类型信息,必须指定为 VK_STRUCTURE_TYPE_COMPUTE_PIPELINE-CREATE_INFO。
pNext | 这可以是一个指向扩展特定结构的有效指针或为 NULL。
flags | 该字段提供了用来帮助实现了解管线会如何生成的一些提示。 这些提示以 VkPipelineCreateFlagBits 枚举的形式提供。
VkPipelineCreateFlagBits 枚举有三个字段:
VK_PIPELINE_CREATE_DISABLE_OPTIMIZATION_BIT:从此标志创建的计算管线不会被优化。 在没有优化路径的情况下,创建管线的总体时间预计会减少。
VK_PIPELINE_CREATE_ALLOW_DERIVATIVES_BIT:使用此标志创建的计算管线允许成为使用 vkCreateGraphicsPipelines()API 创建的后续计算管线的父级。
VK_PIPELINE_CREATE DERIVATIVE_BIT:使用此标志创建的计算管线会成为先前创建的管线的子节点。
stage | 这指定了使用 VkPipelineShaderStageCreateInfo 结构的计算着色器。
layout | 该字段指定管线和描述符集使用的绑定位置。
basePipelineHandle | 该字段指定了管线将从何处派生的基本管线。
basePipelineIndex | 此字段指定了基本管线(将被用来派生管线对象)中的 pCreateInfos 参数的索引。
计算管线中使用的 VkPipelineShaderStageCreateInfo 结构指定了要在计算管线中使用的计算着色器相关的重要信息。 它包含着色器的类型,必须是 VK_SHADER_STAGE_COMPUTE_BIT。 此外,它还以着色器模块的形式指定了着色器源,并在计算着色器源中指定了入口点函数:
typedef struct VkPipelineShaderStageCreateInfo {
VkStructureType sType;
const void* pNext;
VkPipelineShaderStageCreateFlags flags;
VkShaderStageFlagBits stage;
VkShaderModule module;
const char* pName;
const VkSpecializationInfo* pSpecializationInfo;
} VkPipelineShaderStageCreateInfo;
我们来看看这个结构的各个字段:
字段 | 描述
—|---
sType | 这是这个结构的类型信息,必须指定为 VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO。
pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 该字段保留供将来使用。
stage | 这指定了使用 VkShaderStageFlagBits 结构的管线阶段。
Module | 这是 VkShaderModule 对象,其中包含预期的计算着色器。
pName | 这是计算着色器中入口点的名称(UTF-8 格式化字符串)。
pSpecializationInfo | 这是 VkSpecializationInfo 指针对象。
Vulkan 中的管线状态对象 Pipeline State Objects-PSO
管线中的管线状态对象是控制物理设备硬件设置的一种手段。 管线中指定了各种类型的管线状态对象;以预定义的顺序进行工作。 这些阶段中的输入数据和资源会根据用户指定的行为进行更改。 每个阶段都会处理输入并将其传递给下一个输入。 根据应用程序的要求,管线状态阶段可以根据用户的选择绕过。 这完全可以通过 VkComputePipelineCreateInfo 进行配置。
在我们详细介绍这些管线状态对象之前,先让我们对它们进行一个简单的概述:
- 动态状态:dynamic state, 它指定了在此管线中使用的动态状态。
- 顶点输入状态:vertex input state, 这指定了数据输入速率及其解释。
- 输入装配状态:input assembly state, 这个把顶点数据组装成图元的拓扑(线,点和三角形变体)。
- 光栅化状态:rasterization state, 此操作与光栅化相关,如多边形填充模式,正面信息,剔除模式信息等。
- 颜色混合状态:color blend state, 这指定源片段和目标片段之间的混合因子和操作。
- 视口状态:viewport state, 它定义了视口,裁剪器和尺寸。
- 深度 / 模板状态:depth/stencil state, 这指定了如何执行深度 / 模板操作。
- 多重采样状态:multisampling state, 这个控制着栅格化期间用于抗锯齿目的的像素描绘中使用的采样。
以下图表说明了 PSO 中的每个阶段:


在下面的小节中,我们将详细讨论每个阶段。 我们将介绍管线状态的概念,其官方规范和示例代码的实现。
我们将在 VulkanPipeline 类中的 createPipeline()函数内实现所有的管线状态对象。 这个函数首先设置管线状态对象,这些对象用来创建图形管线。
动态状态 Dynamic states
动态状态指定了当前管线中使用的动态状态的总数及其管线中的各自对象,其中包括视口,模板,线宽,混合常量,模板比较掩码等等。 Vulkan 中的每个动态状态均使用 VkDynamicState 枚举表示。
提示
动态状态的更新并不昂贵;相反静态状态反而更复杂,必须仔细设置静态状态以避免出现性能临界路径。 The following is the syntax of the dynamic state API 以下是动态状态 API 的语法:
typedef struct VkPipelineDynamicStateCreateInfo {
VkStructureType sType;
const void* pNext;
VkPipelineDynamicStateCreateFlags flags;
uint32_t dynamicStateCount;
const VkDynamicState* pDynamicStates;
} VkPipelineDynamicStateCreateInfo;
我们来看看这个结构的各个字段:
字段 | 描述
—|---
sType | 该字段指定当前结构的类型。 这个字段的值必须是 VK_STRUCTURE_TYPE_-PIPELINE_DYNAMIC_STATE_CREATE_INFO。
pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 这是一个保留字段,供将来使用。
dynamicStateCount | 这是指在 pDynamicStates 中指定的 VkDynamicState 对象的数量。
pDynamicStates | 这是一个 VkDynamicState 枚举数组,表示所有的动态状态,这些动态的状态会使用来自动态状态命令的值而不是来自管线状态的 CreateInfo 命令的值。
在下一小节中,我们将使用此 API 并实现动态状态。
实现动态状态 dynamic states
在 VulkanPipeline :: createPipeline()函数中实现的第一个管线状态是动态状态。 首先,创建一个名为 dynamicStateEnables 的 VkDynamicState 空数组,并用动态状态对其进行填充。 该数组用来通知管线可在运行时更改的那些状态的相关信息。 例如,以下实现包含两个动态状态:视口(VK_DYNAMIC_STATE_VIEWPORT)和裁剪器(VK_DYNAMIC_STATE_SCISSOR)。 此实现指定了视口和裁剪的参数,并且可以在运行时对它们进行更改。
dynamicStateEnables 会被压入 VkPipelineDynamicStateCreateInfo 控制结构对象中,稍后将被 pipelineInfo(VkGraphicsPipelineCreateInfo)用来创建图形管线。 以下是代码实现:
/********** VulkanPipeline.cpp /**********/
// Inside VulkanPipeline::createPipeline()
// Initialize the dynamic states, initially it’s empty VkDynamicState dynamicStateEnables[VK_DYNAMIC_STATE_RANGE_SIZE]; memset(dynamicStateEnables, 0, sizeof (dynamicStateEnables));
// Specify the dynamic state information to pipeline through
// VkPipelineDynamicStateCreateInfo control structure. VkPipelineDynamicStateCreateInfo dynamicState = {}; dynamicState.sType = VK_STRUCTURE_TYPE_PIPELINE_DYNAMIC_STATE_CREATE_INFO;
dynamicState.pNext = NULL; dynamicState.pDynamicStates = dynamicStateEnables; dynamicState.dynamicStateCount = 0;
// Specify the dynamic state count and VkDynamicState enum
// stating which dynamic state will use the values from dynamic
// state commands rather than from the pipeline state creation info.
dynamicStateEnables[dynamicState.dynamicStateCount++] =
VK_DYNAMIC_STATE_VIEWPORT;
dynamicStateEnables[dynamicState.dynamicStateCount++] =
VK_DYNAMIC_STATE_SCISSOR;
一旦构建了动态状态,我们就可以继续构建下一个管线状态对象。 这个过程的下一个阶段是顶点输入阶段,在下面的部分会对此进行描述。
顶点输入状态 Vertex input states
顶点输入状态指定了输入绑定(VkVertexInputBindingDescription)和顶点属性描述符(VkVertexInputAttributeDescription)。 输入绑定有助于管线通过绑定按照数据消耗的速率访问资源。 另一方面,顶点属性描述符存储了重要的信息,如位置,绑定,格式等, 这些信息用来解释顶点数据。 有关更多信息,请参阅第 7 章“缓冲区资源,渲染通道,帧缓冲区以及使用 SPIR-V 的着色器”中“实现缓冲区资源 - 为几何图形创建顶点缓冲区”部分。
上述信息被封装到 VkPipelineVertexInputStateCreateInfo 结构对象中,稍后会用它来创建图形管线。 有关此结构的详细说明,请参阅以下介绍。 下面是这个结构的语法:
typedef struct VkPipelineVertexInputStateCreateInfo {
VkStructureType sType;
const void* pNext;
VkPipelineVertexInputStateCreateFlags flags;
uint32_t vertexBindingDescriptionCount;
const VkVertexInputBindingDescription*
pVertexBindingDescriptions;
uint32_t vertexAttributeDescriptionCount;
const VkVertexInputAttributeDescription*
pVertexAttributeDescriptions;
} VkPipelineVertexInputStateCreateInfo;
下表描述了此控制结构的每个字段:
字段 | 描述
—|---
sType | 这是该结构的类型信息。 它必须指定为 VK_STRUCTURE_TYPE_PIPELINE_VERTEX_INPUT_STATE_CREATE_INFO。 pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 该参数保留,留作将来实现。
vertexBindingDescriptionCount | 这是在 VkVertexInputBindingDescription 对象(pVertexBindingDescriptions)中指定的顶点绑定实例的总数。
pVertexBindingDescriptions | 这是一个指向 VkVertexInputBindingDescription 对象数组的指针。
vertexAttributeDescriptionCount | 这是 VkVertexInputAttributeDescription 对象(pVertexAttributeDescriptions)中指定的顶点属性描述的总数。
pVertexAttributeDescriptions | 这是一个指向 VkVertexInputAttributeDescription 数组的指针。
让我们来看看下一小节中顶点输入状态的实现。
实现顶点输入状态 vertex input states
在 VulkanPipeline :: createPipeline()函数中,演示了顶点输入状态的实现,如以下代码所示。 此状态有助于管线弄清楚使用 VkVertexInputAttributeDescription 对象中指定的顶点属性描述如何解析发送的数据,其中包含的另一条信息是以什么样的速率消耗顶点数据,用于处理,这是在输入绑定描述(VkVertexInputBindingDescription)中指定的。 消耗数据有两种方法:基于每个顶点或每个实例。 最后一个 createpipelines 参数 drawableObj(VulkanDrawable 类型)包含顶点属性描述和顶点输入绑定描述:
/********** VulkanPipeline.cpp **********/
// Inside VulkanPipeline::createPipeline(VulkanDrawable*
// drawableObj, VkPipeline* pipeline, VulkanShader*
// shaderObj, VkBool32 includeDepth, VkBool32 includeVi) VkPipelineVertexInputStateCreateInfo vertexInputStateInfo = {}; vertexInputStateInfo.sType =
VK_STRUCTURE_TYPE_PIPELINE_VERTEX_INPUT_STATE_CREATE_INFO;
vertexInputStateInfo.pNext = NULL;
vertexInputStateInfo.flags = 0;
vertexInputStateInfo.vertexBindingDescriptionCount = 1; vertexInputStateInfo.pVertexBindingDescriptions =
&drawableObj->viIpBind; vertexInputStateInfo.vertexAttributeDescriptionCount = 2; vertexInputStateInfo.pVertexAttributeDescriptions =
drawableObj->viIpAttrb;
在顶点输入状态之后,我们还会有输入装配状态。 这个阶段借助基本图元(如点,线或三角形)将传入的数据组装为有意义的形状。
输入装配状态 Input assembly states
当图形管线接收到顶点数据时,它和装满了未组装的乐高积木的桶非常类似。 这些顶点以点,线和三角形变体的形式进行连接,根据用户要求组合出任意形状。 然后这个形状会影响光栅化阶段,从而产生与形状图元关联的对应片段。 整个过程类似于组装乐高积木,进而把它们组合为合理的几何形状。
在一个称之为输入装配的阶段中,把这些顶点组装成基本的图元,这是使用 VkPipelineInputAssemblyStateCreateInfo 结构来指定输入装配的。 这个结构包含必要的基本拓扑信息,帮助顶点根据指定的规则相互连接。 输入装配结构在 VkPrimitiveTopology 结构中指定了拓扑信息。 请参阅以下语法和实现:
typedef struct VkPipelineInputAssemblyStateCreateInfo {
VkStructureType sType;
const void* pNext;
VkPipelineInputAssemblyStateCreateFlags flags;
VkPrimitiveTopology topology;
VkBool32 primitiveRestartEnable;
} VkPipelineInputAssemblyStateCreateInfo;
我们来看看这个结构的各个字段:
字段 | 描述
—|---
type | 这是这个控制结构的类型信息。 它必须指定为 VK_STRUCTURE_TYPE_PIPELINE_INPUT_ASSEMBLY_STATE_CREATE_INFO。
next | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flag | 该字段留作将来实现。
topology | 该字段使用 VkPrimitiveTopology 枚举指定正在使用的基本拓扑结构的类型。
primitiveRestartEnable | 此布尔标志确定是否将特殊标记或顶点索引用作图元重启功能。 当 vkCmdBindIndexBuffer 分别为 VK_INDEX_TYPE_UINT32 或 VK_INDEX_TYPE_UINT16 时,该特殊索引值应为 0xFFFFFFFF 或 0xFFFF。 对于基于列表的拓扑,图元重启不适用。
实现输入装配状态 input assembly states
使用 VulkanPipeline :: createPipeline()中的 VkPipelineInputAssemblyStateCreateInfo 函数指定绘图对象的基本拓扑结构。 在下面的实现中,我们使用了 VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST,使用三个顶点的一个集合生成实心三角形。 接下来,我们指定是否启用图元重启功能:
/********** VulkanPipeline.cpp /**********/
// Inside VulkanPipeline::createPipeline()
VkPipelineInputAssemblyStateCreateInfo inputAssemblyInfo = {};
inputAssemblyInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_INPUT_- ASSEMBLY_STATE_CREATE_INFO;
inputAssemblyInfo.pNext = NULL; inputAssemblyInfo.flags = 0;
inputAssemblyInfo.primitiveRestartEnable = VK_FALSE;
inputAssemblyInfo.topology =VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST;
让我们来详细了解一下什么是图元重启。
图元重启 Primitive restart
图元重启仅适用于索引几何图形,并与(vkCmdDrawIndexed 和 vkCmdDrawIndexedIndirect)绘图 API 一起配合使用。
此功能在一个索引数组数据中使用一个特殊的标记来识别批处理中相同绘制类型的断开的几何图形。 如果您有许多小的绘制几何图形,并且使用了数量不多的顶点,在这种情况下这个特性就很有用;这些大量的几何图形可以组合到一个索引数组中,其中每个几何图形使用特殊的重置标记进行分隔。
图元重启特性用于分隔几何图形的标记是数据类型 unsigned short(0xFFFF(65535))或 unsigned int(0xFFFFFFFF(4294967295))的最大值;有了这些标记,也就指定了元素索引数组:
- 适用的拓扑结构:图元重启功能适用于以下拓扑结构;要记住的关键规则是,它不适用于列表类型的图元拓扑。 有关拓扑的更多信息,请参阅下一节“图元拓扑”:
- VK_PRIMITIVE_TOPOLOGY_LINE_STRIP
- VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP
- VK_PRIMITIVE_TOPOLOGY_TRIANGLE_FAN
- VK_PRIMITIVE_TOPOLOGY_LINE_STRIP_WITH_ADJACENCY
- VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP_WITH_ADJACENCY
- 用法:通过启用 VkPipelineInputAssemblyStateCreateInfo 结构的 primitiveRestartEnable 字段(使用 VK_TRUE),并在同一结构的 topology 字段中指定一个有效的拓扑,就可以使用图元重启功能。
让我们看一下图元重启对三角形条形带拓扑结构的效果。 下图使用一组 11 个连续的索引来绘制一个长条的几何形状。 这些索引不包含任何图元重启标记:


然而,有趣的是,当使用图元重启标记0xFFFF替换第五个索引(4)时,它把这一个索引列表分成了两部分。 前半部分(重置标记的左侧)是一个新的几何形状,并与后半部分(重置标记的右侧)断开连接,产生另一个新形状。 Vulkan 实现从索引列表的起始位置开始步进;当它找到重置标记时,会将访问过的索引与列表的其余部分断开连接,并将它们视为一个单独的索引列表,以形成一个新的断开连接的形状,如下图所示:


在下一节中,我们将了解 Vulkan 拓扑并了解基本的图元:点,线和三角及其相关变体。
基本拓扑 Primitive topologies
基本拓扑定义了用来连接顶点,从而产生任意形状所应用的规则。 这些形状包含一个或几个基本图元:点,线和三角形。 使用 VkPrimitiveTopology 指定基本拓扑:
typedef enum VkPrimitiveTopology {
VK_PRIMITIVE_TOPOLOGY_POINT_LIST = 0,
VK_PRIMITIVE_TOPOLOGY_LINE_LIST = 1,
VK_PRIMITIVE_TOPOLOGY_LINE_STRIP = 2,
VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST = 3,
VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP = 4,
VK_PRIMITIVE_TOPOLOGY_TRIANGLE_FAN = 5,
VK_PRIMITIVE_TOPOLOGY_LINE_LIST_WITH_ADJACENCY = 6,
VK_PRIMITIVE_TOPOLOGY_LINE_STRIP_WITH_ADJACENCY = 7,
VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST_WITH_ADJACENCY = 8,
VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP_WITH_ADJACENCY = 9,
VK_PRIMITIVE_TOPOLOGY_PATCH_LIST = 10,
} VkPrimitiveTopology;
基本拓扑结构可以分为两类:邻接关系和非邻接关系。 在前一种类型中,使用特殊的数学规则来标识用于绘制图元的一组顶点中的相邻顶点。 几何着色器中可以访问这些相邻的顶点。 另一方面,后一种类型不具有邻接顶点的概念。
没有邻接的图元拓扑 Primitives topologies with no adjacency
让我们快速浏览一下下表中的每个图元:
Primitive topology types 基本拓扑类型 | 描述
—|---
VK_PRIMITIVE_TOPOLOGY_POINT_LIST | 每个传入的顶点位置代表一个点图元。 为此,引发顶点索引是 i。


VK_PRIMITIVE_TOPOLOGY_LINE_LIST | 在这些顶点之间,每对顶点用于渲染一条线。 为此,引发顶点索引是 2i。


VK_PRIMITIVE_TOPOLOGY_LINE_STRIP | 每个顶点与它之前的顶点之间形成一条线。 为此,引发顶点索引是 i。


VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST | 三个顶点的集合用于形成一个实心三角形。 为此,引发顶点索引是 3i。


VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP | 每个顶点都与前两个顶点形成一个三角形。 为此,引发顶点索引是 i。

VK_PRIMITIVE_TOPOLOGY_TRIANGLE_FAN | 每个顶点都与第一个顶点和它之前的顶点形成一个三角形。 这会产生一个扇形图案。 为此,引发的顶点索引是 i + 1。


具有邻接关系的图元拓扑 Primitives topologies with adjacency
在本节中,我们将了解带有邻接规则的线和三角形图元:
- VK_PRIMITIVE_TOPOLOGY_LINE_LIST_WITH_ADJACENCY:此枚举类型定义一个带有邻接关系的直线列表。 在此,对于给定的 N 个顶点,4i + 1 和 4i + 2 个顶点中的每一个都用于绘制一个线段。 4i + 0 和 4i + 3 的顶点分别被认为是 4i + 1 和 4i + 2 的顶点的邻接顶点;此处,我的范围从 0 到 N-1。 如果几何图形着色器阶段处于激活状态,则可以在几何着色器中访问这些相邻顶点;如果不是,就忽略它们:


- VK_PRIMITIVE_TOPOLOGY_LINE_STRIP_WITH_ADJACENCY:这种类型的直线枚举定义了一个具有相邻性的线条带。 对于给定的 N + 3 个顶点,每个 i + 1 到 i + 2 的顶点用于绘制一个线段。 顶点的数量必须多于四个;否则,绘制就会被忽略。 对于每条线段 i,第 i + 0 和第 i + 3 个顶点分别被认为是第 i + 1 和第 4i + 2 个顶点的邻接顶点。


- VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST_WITH_ADJACENCY:此枚举类型使用邻接规则定义了三角形列表。 在这里,对于给定的 6n + k 个顶点,6i,6i +2 和 6i + 4 的顶点解析为一个三角形(参见下图:0,2 和 4),其中 i 的范围为 0,1,2, … 到 n-1,并且 k 可以是 0,1,2,3,4 或 5. 如果 k 不为零,则最后的 k 个顶点被忽略。
对于每个确定的三角形,i,6i + 1st,6i + 3rd 和 3rd + 5st 的顶点(参考下图:0,1,3 和 5)具有由顶点对 6i 和 6i + 2,6i + 2nd 和 6i + 4th,以及 6i + 4th 和 6ith 产生的邻边。 在图中,这些邻边由 0 到 2,2 到 4 和 4 到 6 表示。如果几何着色器阶段处于激活状态,则每个三角形的相邻顶点可在几何着色器中访问;如果没有,它们将被忽略。


- VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP_WITH_ADJACENCY:这是另一种类型的邻接三角形枚举。 对于给定的 2(n + 2)+ k 个顶点,可以绘制 n 个三角形以使 k 可以取 0 或 1。如果 k 等于 1,则最终顶点将被忽略。如果几何着色器阶段处于激活状态,则 每个三角形的相邻顶点都可以在几何着色器中访问;如果不是,他们被忽略。
以下规则表描述了三角形条带,其中每个三角形相邻顶点的绘制顺序:


下图显示了带有相邻规则的三角形条带下的图元渲染:


在下一节中,我们将使用光栅化 rasterization 将图元 primitives 转换为片段 fragments 。
光栅化 Rasterization
片段是在光栅化阶段使用基本的拓扑结构生成的。 光栅化的图像由称为片段的小方块组成,以网格方式排列。片段是帧缓冲区中(x,y)位置的逻辑组合,对应于深度(z)以及片段着色器添加的相关数据和属性。
每个图元都要经过光栅化过程,并根据拓扑形状确定相应的片段。 在此,计算每个图元的整数位置,从而产生帧缓冲区网格上对应的点或方块。 与位置一起,负责确定最终片段颜色的一个或多个深度值及其属性会被存储在帧缓冲区中。 每个计算点可以有一个或多个深度值;这表明存在多个重叠的图元(完全或部分)竞争相同的位置。 然后根据深度和相关属性信息解析这些片段。
片段可能是非方形的,这并不影响光栅化过程的工作方式。 栅格化与片段的高宽比无关。 由于正方形简化了抗锯齿和纹理化的过程,因此将片段假定为正方形。
最终计算出的片段是一个对应于帧缓冲区的像素。 任何属于帧缓冲区维度以外的片段都会被丢弃,并且在管线后期阶段不再考虑,包括任何早期的逐片段测试。 片段着色器处理幸存的片段,并修改现有的深度值以及与片段相关联的数据。
栅格化状态 Rasterization states
栅格化通过栅格化状态进行管理,栅格化状态可以使用 VkPipelineRasterizationStateCreateInfo 结构以编程方式进行控制。 该结构提供了与光栅化阶段相关的重要信息(例如多边形填充模式,正面朝向和剔除模式),并检查光栅化过程中是否启用了深度。 它还检查是否启用丢弃的片段。 这里是语法信息:
typedef struct VkPipelineRasterizationStateCreateInfo {
VkStructureType pType;
const void* pNext;
VkPipelineRasterizationStateCreateFlags flags;
VkBool32 depthClampEnable;
VkBool32 rasterizerDiscardEnable;
VkPolygonMode polygonMode;
VkCullModeFlags cullMode;
VkFrontFace frontFace;
VkBool32 depthBiasEnable;
float depthBiasConstantFactor;
float depthBiasClamp;
float depthBiasSlopeFactor;
float lineWidth;
} VkPipelineRasterizationStateCreateInfo;
下表描述了该结构的每个字段:
标志 | 描述
—|---
pType | 这是这个控制结构的类型信息。 必须指定为 VK_STRUCTURE_TYPE_PIPELINE_-RASTERIZATION_STATE_CREATE_INFO。 pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 该字段留作未来实现。
depthClampEnable | 此布尔标志控制片段的深度值是否使用截锥体的 z 平面进行截断,而不是通过剪切图元的形式进行裁剪。
rasterizerDiscardEnable | 在达到光栅化阶段之前,可以使用此标志值控制是否丢弃相应的图元。
polygonMode | 三角形图元可以以各种模式渲染,例如点,填充或轮廓。 此模式由 VkPolygonMode 枚举表示,其枚举值 VK_POLYGON_MODE_FILL,VK_POLYGON_MODE_LINE 和 VK_POLYGON_MODE_POINT 分别用来表示填充,线条和点。 cullMode | 这表示图元的剔除模式,通过 VkCullModeFlagBits。 它有 VK_CULL_MODE_NONE, VK_CULL_MODE_FRONT_BIT,VK_CULL_MODE_BACK_BIT 和 VK_CULL_MODE_FRONT_AND_BACK 的枚举值指定不进行剔除,三角正面剔除,三角背面剔除以及正面和背面剔除。
frontFace | 这表明视为正面的三角形顶点朝向的方向 — 通过 VkFrontFace 枚举来指定;表示顺时针方向为正面(VK_FRONT_FACE_CLOCKWISE)和逆时针方向为正面(VK_FRONT_FACE_COUNTER_CLOCKWISE)。
depthBiasEnable | 偏置片段的深度值可以使用该字段进行控制。 depthBiasConstantFactor | 对于每个片段深度值,可以使用此比例因子添加恒定的深度。
depthBiasClamp | 该字段是一个标量因子,用于表示片段的最高或最低深度偏差。
depthBiasSlopeFactor | 该字段是一个标量因子,适用于片段斜率上的深度偏差计算。
lineWidth | 这是控制栅格化的线段宽度的标量值。
实现光栅化状态 rasterization states
在本节中,我们将在 VulkanPipeline :: createPipeline()函数内实现光栅化状态。 栅格化会生成与此阶段涉及图元所关联的片段。 以下实现指定了需要进行渲染填充的图元。 会筛选出所有的背面,其中根据正面朝向的规则(该规则认为顶点按顺时针方向排序)确定了前面。
/********** VulkanPipeline.cpp **********/
// Inside VulkanPipeline::createPipeline()
VkPipelineRasterizationStateCreateInfo rasterStateInfo = {};
rasterStateInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_RASTERIZATION_STATE_CREATE_INFO;
rasterStateInfo.pNext = NULL;
rasterStateInfo.flags = 0;
rasterStateInfo.polygonMode = VK_POLYGON_MODE_FILL;
rasterStateInfo.cullMode = VK_CULL_MODE_BACK_BIT;
rasterStateInfo.frontFace = VK_FRONT_FACE_CLOCKWISE;
rasterStateInfo.depthClampEnable = includeDepth;
rasterStateInfo.rasterizerDiscardEnable = VK_FALSE;
rasterStateInfo.depthBiasEnable = VK_FALSE;
rasterStateInfo.depthBiasConstantFactor = 0;
rasterStateInfo.depthBiasClamp = 0;
rasterStateInfo.depthBiasSlopeFactor = 0;
rasterStateInfo.lineWidth = 1.0f;
在下一节中,我们来看看 Vulkan API 中的颜色混合状态及其实现。
混合 Blending
混合是一个过程,在这个过程中,根据混合因子确定的一些特殊规则,源片段会被合并目标片段中。 源片段和目标片段都由四个部分组成;其中三个对应于颜色分量(R,G,B),另一个对应于控制不透明度的 alpha 分量。
对于帧缓冲区中每个给定的采样位置,输入的源片段(Rs,Gs,Bs,As)会被合并到目标片段(Rd,Gd,Bd,Ad),并存储在帧缓冲区中的片段位置(x,y)处 。
混合计算会以更高的精度进行;它们总是以浮点为基础进行,其精度不会低于目标分量。 因此,任何有符号和无符号的归一化定点类型会先转换为浮点,以实现最高的精度。
混合由混合操作,混合因子和混合常数控制:
- 混合操作:Blending operations,这些定义了用于合并源值和目标值的基本数学公式,例如加法(VK_BLEND_OP_ADD),减法(VK_BLEND_OP_SUBTRACT)和反向减法(VK_BLEND_OP_REVERSE_SUBTRACT)。
- 混合因子:Blending factors,每个分量的权重由混合因子决定。 这些因子可用于修改所使用的混合操作。
- 混合常量:Blending constants,这是一个常量颜色分量(R,G,B,A),用于混合并生成一组新的颜色分量。
颜色混合状态 Color blend states
在图形管线中,使用 VkPipelineColorBlendStateCreateInfo 控制结构指定混合状态:
typedef struct VkPipelineColorBlendStateCreateInfo { VkStructureType sType;
const void* pNext;
VkPipelineColorBlendStateCreateFlags flags;
VkBool32 logicOpEnable;
VkLogicOp logicOp;
uint32_t pAttachmentCount;
const VkPipelineColorBlendAttachmentState* attachments;
float blendConstants[4];
} VkPipelineColorBlendStateCreateInfo;
下表描述了此结构的各个字段:
字段 | 描述
—|---
sType | 这是这个控制结构的类型信息。 必须指定为 VK_STRUCTURE_TYPE_PIPELINE_COLOR_BLEND_STATE_CREATE_INFO。
pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 该字段保留供将来使用。
logicOpEnable | 这是一个布尔标志,用于确定是否应用逻辑操作。
logicOp | 如果启用了 logicOpEnable,那么此字段指定要应用哪个逻辑操作。 attachmentCount | 这表示 pAttachments 中的对象元素的总数,其中的类型为 VkPipelineColorBlendAttachmentState。
pAttachments | 这是一个元素数组(类型为 VkPipelineColorBlend-AttachmentState)。 blendConstants | 基于所用的混合因子,这表示混合中使用的四种颜色值(R,G,B,A)。
VkPipelineColorBlendStateCreateInfo 控制结构将 VkPipelineColorBlendAttachmentState 作为输入。 它为当前管线中使用的若干子通道中的每个颜色附件指定了混合因子和混合操作。 这是它的语法:
typedef struct VkPipelineColorBlendAttachmentState {
VkBool32 blendEnable;
VkBlendFactor srcColorBlendFactor;
VkBlendFactor dstColorBlendFactor;
VkBlendOp colorBlendOp;
VkBlendFactor srcAlphaBlendFactor;
VkBlendFactor dstAlphaBlendFactor;
VkBlendOp alphaBlendOp; VkColorComponentFlags colorWriteMask;
} VkPipelineColorBlendAttachmentState;
VkPipelineColorBlendAttachmentState 的各个字段如下:
字段 | 描述
—|---
blendEnable | 这表示是否为相应的颜色附件启用混合。 混合禁用时,源片段的颜色保持不变。
srcColorBlendFactor | 该字段指定用于计算源因子(Sr,Sg,Sb)的混合因子。 dstColorBlendFactor | 此字段指定用于计算目标因子(Dr,Dg,Db)的混合因子。 colorBlendOp | 这个字段表明要对源和目标颜色应用哪个混合因子来计算最终颜色值(RGB),并将其写入颜色附件中。
srcAlphaBlendFactor | 此字段指定用于计算源的 Alpha 通道的混合因子,即 Sa。 dstAlphaBlendFactor | 此字段指定用于计算目标的 Alpha 通道的混合因子,即 Da。 alphaBlendOp | 此字段指定在源和目标的 alpha 通道上应用哪个混合因子来计算最终的 alpha 值(A),并将其写入颜色附件中。
colorWriteMask | 此字段指定颜色通道的(R,G,B,A)位掩码值,用于写入颜色附件缓冲区。
实现颜色混合状态 color blend states
颜色混合的过程在 VulkanPipeline :: createPipeline()函数中实现。 该函数使用 VkPipelineColorBlendAttachmentState 结构对象(colorBlendAttachmentStateInfo)定义颜色附件的混合属性。 此结构决定了颜色混合是启用还是禁用。 如果启用,则指定各种属性,如 alpha 和颜色混合操作。 有多个混合操作(VkBlendOp)方程可用于合并两个操作,如加法,减法,反相减法等。 另外,对于源片段和目标片段,颜色和 alpha 混合因子会在这里初始化。
接下来,创建 VkPipelineColorBlendStateCreateInfo 对象的 colorBlendStateInfo 并将 colorBlendAttachmentStateInfo 传递给它。 此结构使用颜色混合状态信息指定了要处理的颜色附件。 另外,逻辑混合操作也会使用 logicOp(VkLogicOp 类型)进行初始化。 指定的另一个重要信息是颜色混合常数。 请参阅下面的代码实现:
/********** VulkanPipeline.cpp **********/
// Inside VulkanPipeline::createPipeline()
// Create the color blend attachment information
VkPipelineColorBlendAttachmentState
colorBlendAttachmentStateInfo[1] = {}; colorBlendAttachmentStateInfo[0].colorWriteMask = 0xf; colorBlendAttachmentStateInfo[0].blendEnable = VK_FALSE;
// Define color and alpha blending operation. colorBlendAttachmentStateInfo[0].alphaBlendOp = VK_BLEND_OP_ADD; colorBlendAttachmentStateInfo[0].colorBlendOp = VK_BLEND_OP_ADD;
// Set the source and destination color/alpha blend factors
colorBlendAttachmentStateInfo[0].srcColorBlendFactor =
VK_BLEND_FACTOR_ZERO;
colorBlendAttachmentStateInfo[0].dstColorBlendFactor =
VK_BLEND_FACTOR_ZERO;
colorBlendAttachmentStateInfo[0].srcAlphaBlendFactor =
VK_BLEND_FACTOR_ZERO;
colorBlendAttachmentStateInfo[0].dstAlphaBlendFactor =
VK_BLEND_FACTOR_ZERO;
VkPipelineColorBlendStateCreateInfo colorBlendStateInfo = {}; colorBlendStateInfo.sType = VK_STRUCTURE_TYPE-
_PIPELINE_COLOR_BLEND_STATE_CREATE_INFO;
colorBlendStateInfo.flags = 0;
colorBlendStateInfo.pNext = NULL; colorBlendStateInfo.attachmentCount = 1;
// Specify the color blend attachment state object colorBlendStateInfo.pAttachments = colorBlendAttachmentStateInfo; colorBlendStateInfo.logicOpEnable = VK_FALSE; colorBlendStateInfo.blendConstants[0] = 1.0f; colorBlendStateInfo.blendConstants[1] = 1.0f; colorBlendStateInfo.blendConstants[2] = 1.0f; colorBlendStateInfo.blendConstants[3] = 1.0f;
现在我们转到管线状态, 我们先从讨论视口管理开始。
视口管理 Viewport management
视口是在其上执行图元渲染的表面区域的一部分。 它使用 VkViewport 结构定义了物理尺寸,单位为像素,该结构表示一个 2D 展示区域和深度范围。 这两个内容被合并在一起,然后用于执行视口转换。
现在关于视口转换稍稍说明一下。 在视口转换过程中,使用 VkViewport 中定义的视口的 2D 区域和深度范围将标准化的设备坐标转换为帧缓冲区坐标。
视口状态 viewport state
视口转换过程是图形管线的一部分,并使用 VkPipelineViewportStateCreateInfo 控制结构进行控制。 这个结构不仅定义了视口,而且定义了裁剪器 scissors 。
使用这个结构,可以指定多个视口。 视口的最大数量可以使用 VkPhysicalDeviceLimits :: maxViewports 减 1 来确定。 以下其语法:
typedef struct VkPipelineViewportStateCreateInfo { VkStructureType sType;
const void* pNext;
VkPipelineViewportStateCreateFlags flags;
uint32_t viewportCount;
const VkViewport* pViewports;
uint32_t scissorCount;
const VkRect2D* pScissors;
} VkPipelineViewportStateCreateInfo;
我们来看看这个结构的各个字段:
字段 | 描述
—|---
sType | 这是这个控制结构的类型信息。 必须将其指定为 VK_STRUCTURE_TYPE_PIPELINE_VIEWPORT_STATE_CREATE_INFO。 pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 该字段保留供将来实现,并且必须指定为 NULL; 该字段目前未被使用。
viewportCount | 这个字段表示管线使用的 pViewports 数组中的视口总量。
pViewports | 这是一个指向视口(VkViewport 类型)数组的指针,指示每个视口的尺寸。 如果视口状态为动态,则此值会被忽略。
scissorCount | 这表示管线中使用的裁剪器数量, 它必须等于 viewportCount 指定的视口数量。
pScissors | 这是一个指向矩形边界区域数组的指针,由 VkRect2D 控制结构为每个矩形区域指定相应的视口。
在接下来的小节中,我们将实现视口的状态对象。
实现视口状态 viewport state
以下是 VulkanPipeline :: createPipeline()函数中的视口实现。 首先,创建 VkPipelineViewportStateCreateInfo 对象并分配管线使用的视口和裁剪器的数量。 在本节的开始,我们声明的视口状态是一个动态状态,这向管线指明了视口参数可能会发生变化,并会使用 initViewport()函数中的 vkSetCmdViewport()进行设置。 因此,默认情况下,pViewports 和 pScissors 参数为 NULL:
/********** VulkanPipeline.cpp **********/
// Inside VulkanPipeline::createPipeline()
// Define the number of viewport, this must be equal to number
// of scissors should be equal.
define NUMBER_OF_VIEWPORTS 1
define NUMBER_OF_SCISSORS NUMBER_OF_VIEWPORTS
// Create the viewport state create info and provide the
// the number of viewport and scissors being used in the
// rendering pipeline.
VkPipelineViewportStateCreateInfo viewportStateInfo = {}; viewportStateInfo.sType = VK_STRUCTURE_TYPE_-
PIPELINE_VIEWPORT_STATE_ CREATE_INFO;
viewportStateInfo.pNext = NULL;
viewportStateInfo.flags = 0;
// Number of viewports must be equal to number of scissors. viewportStateInfo.viewportCount = NUMBER_OF_VIEWPORTS; viewportStateInfo.scissorCount = NUMBER_OF_SCISSORS; viewportStateInfo.pScissors = NULL; viewportStateInfo.pViewports = NULL;
深度和模版测试 Depth and stencil tests
深度测试就是存储的片段,在相同的帧缓冲区位置上可能会包含属于每个重叠图元的不同深度值,即在同一个位置有多个深度值。 会比较这些值并存储在深度缓冲区附件中。 这样做是为了根据存储在深度缓冲区附件中的值有条件地剪切片段;对于给定的片段,该值通常存储在帧缓冲区中的(xf,yf)位置处。
模板测试使用深度、模板附件,并将存储在帧缓冲区(xf,yf)位置处的值与给定的参考值进行比较。 根据模板测试状态,在模板、深度附件中模板值和模板写入掩码会被更新。
深度和模板状态使用 VkPipelineDepthStencil-StateCreateInfo 结构进行控制。 可以使用成员变量 depthBoundsTestEnable 和 stencilTestEnable 来启用或禁用深度和模板测试。
Depth and stencil states 深度和模版状态
以下是 VkPipelineDepthStencilState-CreateInfo 结构的语法和描述:
typedef struct VkPipelineDepthStencilStateCreateInfo {
VkStructureType SType;
const void* pNext;
VkPipelineDepthStencilStateCreateFlags flags;
VkBool32 depthTestEnable;
VkBool32 depthWriteEnable;
VkCompareOp depthCompareOp;
VkBool32 depthBoundsTestEnable;
VkBool32 stencilTestEnable;
VkStencilOpState front;
VkStencilOpState back;
float minDepthBounds;
float maxDepthBounds;
} VkPipelineDepthStencilStateCreateInfo;
我们来看看这个结构的各个字段:
字段 | 描述
—|---
sType | 这是这个控制结构的类型信息。 必须将其指定为 VK_STRUCTURE_TYPE_PIPELINE_DEPTH_STENCIL_STATE_CREATE_INFO。 pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 该字段保留供将来实现,并且必须指定为 NULL; 该字段目前尚未被使用。 depthTestEnable | 这是检查深度测试是否启用的布尔标志。 depthWriteEnable | 该字段检查是否启用了深度写入。
depthCompareOp | 该字段是要在深度测试中使用的比较运算符。
depthBoundsTestEnable | 这是检查深度边界测试是启用还是禁用的布尔标志。
stencilTestEnable | 这将检查模板测试是启用还是禁用。 front | 这是对应于模板测试的前端控制的参数。
back | 这是对应于模板测试的后端控制的参数。 minDepthBounds | 这是深度边界测试中使用的最小值范围。
maxDepthBounds | 这是深度边界测试中使用的最大值范围。
在这个函数(createPipeline())的开始部分,我们定义了一些动态状态(VkDynamicState),它们向管线说明在管线中会动态控制哪些状态。 如果深度状态(VK_DYNAMIC_STATE_DEPTH_BOUNDS)未动态定义,则深度边界测试由 VkPipelineDepthStencilStateCreateInfo 的 minDepthBounds 和 maxDepthBounds 成员定义。
另一方面,如果启用了动态深度边界测试,则可以在运行时使用 vkCmdSetDepthBounds API 设置深度边界范围。 这个 API 有三个参数。 第一个参数是命令缓冲区,接下来的两个参数指定最小和最大深度边界值。 以下是这个 API 的语法:
void vkCmdSetDepthBounds(
VkCommandBuffer commandBuffer,
float minDepthBounds,
float maxDepthBounds);
实现深度模版状态 depth stencil states
createPipeline()中定义的下一个状态是深度、模板状态。 在下面的代码中,创建了 VkPipelineDepthStencilStateCreateInfo,并使用 includeDepth 布尔标志确定是否启用了深度和模板测试。 在目前情况下,深度测试已启用;因此,我们应该向管线提供更多信息,说明如何进行深度和模板操作。 该信息可以包括深度比较操作,该深度比较操作说明了在深度写入启用时,深度缓冲区的值如何与传入的深度值进行比较,从而来更新深度缓冲区。 同样,定义的其他一些字段是比较掩码以及最小和最大深度范围。 请参考以下代码中的实现:
/********** VulkanPipeline.cpp **********/
// Inside VulkanPipeline::createPipeline() VkPipelineDepthStencilStateCreateInfo depthStencilStateInfo = {}; depthStencilStateInfo.sType = VK_STRUCTURE_TYPE_PIPELINE-
_DEPTH_STENCIL_STATE_CREATE_INFO;
depthStencilStateInfo.pNext = NULL;
depthStencilStateInfo.flags = 0; depthStencilStateInfo.depthTestEnable = includeDepth; depthStencilStateInfo.depthWriteEnable = includeDepth; depthStencilStateInfo.depthCompareOp = VK_COMPARE_OP_LESS
_OR_EQUAL;
depthStencilStateInfo.depthBoundsTestEnable = VK_FALSE; depthStencilStateInfo.stencilTestEnable = VK_FALSE; depthStencilStateInfo.back.failOp = VK_STENCIL_OP_KEEP; depthStencilStateInfo.back.passOp = VK_STENCIL_OP_KEEP; depthStencilStateInfo.back.compareOp = VK_COMPARE_OP_ALWAYS; depthStencilStateInfo.back.compareMask = 0;
depthStencilStateInfo.back.reference = 0; depthStencilStateInfo.back.depthFailOp = VK_STENCIL_OP_KEEP; depthStencilStateInfo.back.writeMask = 0;
depthStencilStateInfo.minDepthBounds = 0;
depthStencilStateInfo.maxDepthBounds = 0; depthStencilStateInfo.stencilTestEnable = VK_FALSE; depthStencilStateInfo.front = depthStencilStateInfo.back;
在下一节中,我们会看一下多采样状态,该状态控制着光栅图像的外观,以提高显示质量。
多重采样状态 Multisample states
多重采样是消除 Vulkan 图元光栅化过程中产生的走样效果的一种机制。 抗锯齿会从几何图形上获取多个样本,用于对给定的像素生成一个平滑的近似值,从而最小化类似阶梯一样的效果并使边缘看起来更加平滑。
抗锯齿技术是计算机图形学中的一种技术,通过最小化锯齿线或阶梯效应来改善屏幕上显示的渲染图像或视频输出的质量。 栅格帧缓冲区由数百上千个以网格格式排列的小方形像素组成。 在图像光栅化过程中,使用采样方案对几何图形的给定像素进行采样,本节后面会对此进行讨论。 基本上,抗锯齿的问题就是点采样。 这些样本由矩形像素表示,它们还不足以产生曲线形状。 图像中的边缘是圆形的(不是水平的或垂直的),它们负责这种阶梯效果,因为它们最终会像楼梯布置一样对像素着色。 当图像或场景仍然存在时,走样问题并不明显,但只要运动过程中锯齿状边缘就会变得高度可见。
一旦图元(点,线和三角形)被烘焙到最终的显示像素中,它们就会通过多重采样过程进行处理。 这让您可以通过使边缘看起来更平滑而不是锯齿状,从而使 Vulkan 原始图像变得光滑。 这种有效的技术可以节省大量的计算成本(其他抗锯齿技术也是如此)。 这种方案也是 GPU 硬件供应商的首选。 多重采样在单个通道中在对一个给定像素的计算过程中需要多于一个的采样样本。 在多重采样中,原始图元中给定的像素会被多次采样,其中每次采样都可以独立使用颜色,深度和 / 或模板值,随后将其分解为一个合并的颜色。
根据 Vulkan 规范,Vulkan 中单样本模式的光栅化规则已经定义为如下形式:它们等同于在每个像素中心使用单个样本的多重样本模式。
可以使用 VkPipelineMultisampleStateCreateInfo 结构在管线内组织多重采样。 请参阅以下小节了解 API 规范及其实现。 首先,我们来看看这个结构的语法:
typedef struct VkPipelineMultisampleStateCreateInfo { VkStructureType sType;
const void* pNext;
VkPipelineMultisampleStateCreateFlags flags; VkSampleCountFlagBits rasterizationSamples;
VkBool32 sampleShadingEnable;
float minSampleShading;
const VkSampleMask* pSampleMask;
VkBool32 alphaToCoverageEnable;
VkBool32 alphaToOneEnable;
} VkPipelineMultisampleStateCreateInfo;
我们来看看这个结构的各个字段:
字段 | 描述
—|---
sType | 这是这个控制结构的类型信息。 必须将其指定为 VK_STRUCTURE_TYPE_PIPELINE_MULTISAMPLE_STATE_CREATE_INFO。
pNext | 这可以是一个指向扩展特定结构的有效指针或 NULL。
flags | 该字段为 NULL; 它被保留供将来使用。
rasterizationSamples | 该字段表示光栅化过程中每个像素使用的样本数。 sampleShadingEnable | 布尔标志指示是否根据每个样本或每个片段为基准执行片段着色。 如果值为 VK_TRUE,则是每个样本,否则为每个片段。
minSampleShading | 这指定了为每个片段着色所需的唯一样本的最小数量。
pSampleMask | 该字段是用来将静态覆盖信息与光栅化生成的覆盖信息进行“与”运算的位掩码。
alphaToCoverageEnable | 此字段控制片段的首个 color 输出的 alpha 分量的值,是否可用于生成一个临时的覆盖值。
alphaToOneEnable | 这个字段控制多重采样覆盖是否可以替代片段首个 color 输出的 alpha 分量值。
实现多重采样状态 multisample states
VulkanPipeline :: createPipeline()函数中定义的最后一个状态就是多重采样状态。 首先,使用正确的类型信息定义 VkPipelineMultisampleStateCreateInfo 结构,以帮助底层实现了解传入的对象类型。必须将 sType 指定为 VK_STRUCTURE_TYPE_PIPELINE_MULTISAMPLE_STATE_CREATE_INFO。 接下来,说明 rasterizationSample 中每个像素用作覆盖值的样本数,在本例中为 VK_SAMPLE_COUNT_1_BIT。
存在各种像素采样方案。 当 VkPhysicalDeviceFeatures 的 standardSampleLocations 成员为 VK_TRUE 时,则使用以下屏幕截图中显示的示例定义样本数:


根据给定像素中的样本数量,可能会有不同的样本方案,这可能从 1 到 64 个取样不等。 取样包含了基于位置(相对像素左上角原点)贡献权重的多个位置的数据信息。 当 rasterizationSamples 为 VK_SAMPLE_COUNT_1_BIT 时,采样使用像素中心:
/************ VulkanPipeline.cpp *************/
// Inside VulkanPipeline::createPipeline() VkPipelineMultisampleStateCreateInfo multiSampleStateInfo = {}; multiSampleStateInfo.sType =
VK_STRUCTURE_TYPE_PIPELINE_MULTISAMPLE_STATE_CREATE_INFO;
multiSampleStateInfo.pNext = NULL;
multiSampleStateInfo.flags = 0; multiSampleStateInfo.rasterizationSamples = NUM_SAMPLES;
到目前为止,在“创建图形管线”和“Vulkan 中的管线状态对象”小节中,我们学习了如何创建图形管线并向其中指定各种管线状态对象。 在下一节中,我们将在示例应用程序中了解创建管线的执行模型。
实现管线 pipeline
图形管线是在 VulkanRenderer 类的应用程序初始化阶段实现的。 VulkanRenderer :: createPipelineStateManagement()函数负责执行管线的创建。 在此函数内部,会创建 cmdPipelineStateMgmt 命令缓冲区对象,并将管线创建过程的命令记录到该对象中。 然后将这些记录的命令提交给图形队列,即底层实现。
下图显示了执行过程。 在这里,首先分配命令缓冲区来管理管线的操作。 在此之下,使用 VulkanPipeline :: createPipelineCache()函数创建管线缓存对象;一旦完成,管线就会在 VulkanPipeline :: createPipeline()中进行创建。 下图显示了调用顺序:


每个绘图对象(我们将在下一章中实现绘图对象)与创建的管线对象(pipeline)相关联。 如果有多个绘图对象,就可以重用管线对象,而不是为每个对象创建一个新的管线对象。 因此,应用程序有责任控制与每个绘图对象关联的管线对象的冗余,即重用性:
// Create the pipeline and manage the pipeline state objects
void VulkanRenderer::createPipelineStateManagement()
{
// Create the pipeline cache
pipelineObj.createPipelineCache();
const bool depthPresent = true;
// For the each drawing object create the associated pipeline.
for each (VulkanDrawable* drawableObj in drawableList){ VkPipeline* pipeline=(VkPipeline*)malloc(sizeof(VkPipeline)); if (pipelineObj.createPipeline(drawableObj, pipeline,
&shaderObj, depthPresent)){ pipelineList.push_back(pipeline);
drawableObj->setPipeline(pipeline);
}
else
{
}
free(pipeline); pipeline = NULL;
}
}
当管线对象不再需要时,可以将其删除。 在下面的示例实现中,应用程序关闭时,就会在 deInitialization()函数中删除所有的管线对象以及关联的管线缓存:
void VulkanApplication::deInitialize(){
// Destroy all the pipeline objects
rendererObj->destroyPipeline();
// Destroy the associate pipeline cache
rendererObj->getPipelineObject()->destroyPipelineCache();
. . . .
}
// Destroy each pipeline object existing in the renderer
void VulkanRenderer::destroyPipeline(){
for each (VkPipeline* pipeline in pipelineList){ vkDestroyPipeline(deviceObj->device, *pipeline, NULL); free(pipeline);
}
pipelineList.clear();
}
// Destroy the pipeline cache object when no more required
void VulkanPipeline::destroyPipelineCache(){ vkDestroyPipelineCache(deviceObj->device, pipelineCache, NULL);
}
总结
在本章中,我们知道了 Vulkan API 中可用的各种管线。 我们学习了图形管线和计算管线,并在示例中实现了其中的一个。 我们还了解了管线缓存对象,它是一个管线池,有助于实现更好的性能。 管线缓存对象可以以二进制形式存储,稍后可以在应用程序运行时上载和重用。
图形管线包含许多管线状态对象。 在本章中,我们详细介绍了所有的状态以及它们的实现。 作为这些管线状态对象的一部分,我们接着讨论了动态状态,顶点输入状态,输入装配状态,栅格化,混合,视口管理,深度和模板测试以及多重采样状态。
最后,我们使用管线缓存对象和管线状态对象来构建图形管线对象。
在下一章中,我们将使用创建的图形管线对象并在显示屏上渲染我们的第一个 Vulkan 图形对象。 绘制对象由两个主要任务组成:准备和渲染绘图对象。 准备工作包括定义渲染通道,绑定图形管线,提供几何图形,视口 / 剪切以及构建绘图命令。 在渲染时,会获取交换链并执行准备好的绘图命令;这会把绘图对象渲染到展示层上。 另外,我们还会了解 Vulkan 的同步原语;在这里,我们会讨论栏栅,信号量和事件。