首先下载数据集train-textloc.zip
其groundtruth文件如下所示:
158,128,412,182,"Footpath" 442,128,501,170,"To" 393,198,488,240,"and" 63,200,363,242,"Colchester" 71,271,383,313,"Greenstead"
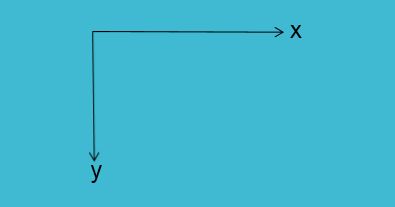
ground truth 文件格式为:xmin, ymin, xmax, ymax, label。同时,要注意,这里的坐标系是如下摆放:
将此txt文件转换成voc xml文件的代码:
icdar2voc.py


1 #! /usr/bin/python 2 #-*-coding:utf8-*- 3 4 import os, sys 5 import glob 6 from PIL import Image 7 8 # ICDAR 图像存储位置 9 src_img_dir = "train-textloc" 10 # ICDAR 图像的 ground truth 的 txt 文件存放位置 11 src_txt_dir = "train-textloc" 12 13 img_Lists = glob.glob(src_img_dir + '/*.jpg') 14 15 img_basenames = [] # e.g. 100.jpg 16 for item in img_Lists: 17 img_basenames.append(os.path.basename(item)) 18 19 img_names = [] # e.g. 100 20 for item in img_basenames: 21 temp1, temp2 = os.path.splitext(item) 22 img_names.append(temp1) 23 24 for img in img_names: 25 im = Image.open((src_img_dir + '/' + img + '.jpg')) 26 width, height = im.size 27 28 # open the crospronding txt file 29 gt = open(src_txt_dir + '/gt_' + img + '.txt').read().splitlines() 30 31 # write in xml file 32 #os.mknod(src_txt_dir + '/' + img + '.xml') 33 xml_file = open((src_txt_dir + '/' + img + '.xml'), 'w') 34 xml_file.write('\n ') 35 xml_file.write('VOC2007 \n') 36 xml_file.write('' + str(img) + '.jpg' + '\n') 37 xml_file.write(' \n ') 38 xml_file.write('' + str(width) + '\n') 39 xml_file.write(' ' + str(height) + '\n') 40 xml_file.write(' 3 \n') 41 xml_file.write(' \n') 42 43 # write the region of text on xml file 44 for img_each_label in gt: 45 spt = img_each_label.split(',') 46 xml_file.write(' ') 47 xml_file.write('text \n') 48 xml_file.write('Unspecified \n') 49 xml_file.write('0 \n') 50 xml_file.write('0 \n') 51 xml_file.write('\n ') 52 xml_file.write('' + str(spt[0]) + '\n') 53 xml_file.write(' ' + str(spt[1]) + '\n') 54 xml_file.write(' ' + str(spt[2]) + '\n') 55 xml_file.write(' ' + str(spt[3]) + '\n') 56 xml_file.write(' \n') 57 xml_file.write(' \n') 58 59 xml_file.write('')
再将xml文件转换成yolo的txt格式:
voc_label.py
1 import xml.etree.ElementTree as ET 2 import pickle 3 import os 4 from os import listdir, getcwd 5 from os.path import join 6 7 8 classes = ["text"] 9 10 11 def convert(size, box): 12 dw = 1./size[0] 13 dh = 1./size[1] 14 x = (box[0] + box[1])/2.0 15 y = (box[2] + box[3])/2.0 16 w = box[1] - box[0] 17 h = box[3] - box[2] 18 x = x*dw 19 w = w*dw 20 y = y*dh 21 h = h*dh 22 return (x,y,w,h) 23 24 for i in range(100,329): 25 in_file = open('train-textloc/%d.xml'% i ) 26 out_file = open('train-textloc/%d.txt'% i , 'w') 27 tree=ET.parse(in_file) 28 root = tree.getroot() 29 size = root.find('size') 30 w = int(size.find('width').text) 31 h = int(size.find('height').text) 32 33 for obj in root.iter('object'): 34 difficult = obj.find('difficult').text 35 cls = obj.find('name').text 36 if cls not in classes or int(difficult) == 1: 37 continue 38 cls_id = classes.index(cls) 39 xmlbox = obj.find('bndbox') 40 b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) 41 bb = convert((w,h), b) 42 out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
下面开始修改yolo的配置:
把20类改成1类
-
cfg/voc.data文件中:
- classes 改成1。
- names=data/voc.names。
- voc.names里只写一行 text 即可。
-
cfg/yolo_voc.cfg文件中 :
- 【region】层中 classes 改成1。
- 【region】层上方第一个【convolution】层,其中的filters值要进行修改,改成(classes+ coords+ 1)* (NUM) ,我的情况中:(1+4+1)* 5=30,我把filters 的值改成了30。
- 修改filters的建议来源自(https://groups.google.com/forum/#!topic/darknet/B4rSpOo84yg),我修改了之后一切正常。
-
src/yolo.c 文件中 :(经指正,步骤3,4是yolo1的内容,使用yolo_v2的话可以不用更改)
- 位置大约第14行左右改成:char *voc_names={“text”},原来里面有20类的名字,我改成了唯一1类的名字。
- 位置大约第328行左右,修改draw_detection这个函数最后一个参数:20改成1。这个函数用于把系统检测出的框给画出来,并把画完框的图片传回第一个参数im中,用于保存和显示。
- 位置大约第361行左右,demo函数中,倒数第三个参数我把20改成了1,虽然不知道有没有用,反正对结果没什么影响。
-
src/yolo_kernels.cu 文件中 :(经指正,步骤3,4是yolo1的内容,使用yolo_v2的话可以不用更改)
- 位置第62行,draw_detection这个函数最后一个参数20改成1。
-
scripts/voc_label.py 文件中(这个应该没用的) :
- 位置第9行改成:classes=[“text”],因为我只有一类。
建立一个文件夹,里面JPEGImages里放入所有的图片,labels里放入所有的标签,系统会自动识别。
然后生成train.txt
list.py
1 # -*- coding: utf-8 -*- 2 import os 3 fw = open('train.txt','w') 4 files = os.listdir('/home/mingyu_ding/darknet/voc/Table/JPEGImages') 5 for f in files: 6 file = '/home/mingyu_ding/darknet/voc/Table/JPEGImages' + os.sep + f 7 print >> fw, file
就可以开始训练了,系统默认会迭代45000次。
nohup ./darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23 > log.txt &
当然迭代次数是可以修改的,应该是在cfg/yolo_voc.cfg修改max_batches的值就行。
没训练完就可以测试啦
./darknet detector test cfg/voc.data cfg/yolo-voc.cfg backup/yolo-voc_5000.weights ../Downloads/1.jpg
参考链接:http://blog.csdn.net/hysteric314/article/details/54097845
结果如下:
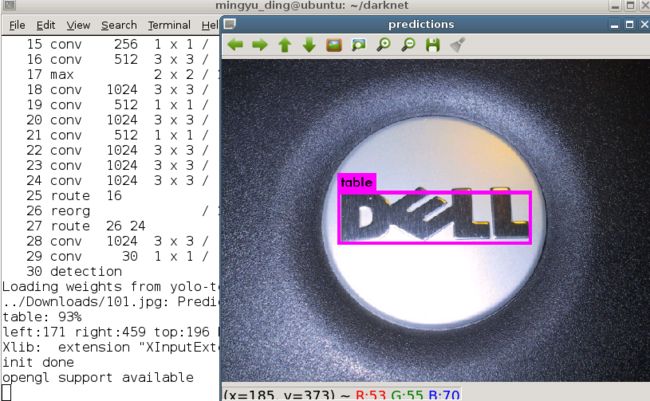
后来又训练了京东的参数图数据。
图是自己下载的,重命名后用labelimg进行标注,之后用voc_label.py修改成标签数据即可。
rename.py
1 import os 2 from os.path import join 3 4 files = os.listdir('imageset') 5 i = 0 6 for f in files: 7 i += 1 8 print os.path.join(os.getcwd() + os.sep + 'imageset' , f) 9 print os.getcwd() + os.sep + 'imageset' + os.sep + '%d.jpg' % i 10 os.rename(os.path.join(os.getcwd() + os.sep + 'imageset' , f), os.getcwd() + os.sep + 'imageset' + os.sep + '%d.jpg' % i)
训练办法和上面一模一样'
结果如下图:

想要输出预测框的位置的话
修改 image.c 后重新 make 就可以了
1 printf("left:%d right:%d top:%d bot:%d\n",left,right,top,bot);
修改 detector.c 后 make 可以切割出想要的位置,如下图所示。
在函数draw_detections() 前面修改就可以
1 int i; 2 int j = 1; 3 for(i = 0; i < l.w*l.h*l.n; ++i){ 4 int class = max_index(probs[i], l.classes); 5 float prob = probs[i][class]; 6 if(prob > thresh){ 7 box b = boxes[i]; 8 int left = (b.x-b.w/2.)*im.w; 9 int right = (b.x+b.w/2.)*im.w; 10 int top = (b.y-b.h/2.)*im.h; 11 int bot = (b.y+b.h/2.)*im.h; 12 if(left < 0) left = 0; 13 if(right > im.w-1) right = im.w-1; 14 if(top < 0) top = 0; 15 if(bot > im.h-1) bot = im.h-1; 16 int width = right - left; 17 int height = bot - top; 18 IplImage* src = cvLoadImage(input,-1); 19 CvSize size = cvSize(width, height); 20 //printf("%d,%d",src->depth,src->nChannels); 21 IplImage* roi = cvCreateImage(size,src->depth,src->nChannels); 22 CvRect box = cvRect(left, top, size.width, size.height); 23 cvSetImageROI(src,box); 24 cvCopy(src,roi,NULL); 25 //cvNamedWindow("pic",CV_WINDOW_AUTOSIZE); 26 //cvShowImage("pic",src); 27 char name[4] = "cut"; 28 char name1[5] = ".jpg"; 29 char newname[100]; 30 sprintf(newname,"%s%d_%.0f%s",name,j,100*prob,name1); 31 //printf("%s\n",newname); 32 j++; 33 cvSaveImage(newname,roi,0); 34 //cvWaitKey(0); 35 //cvDestoryWindow("pic"); 36 cvReleaseImage(&src); 37 cvReleaseImage(&roi); 38 //printf("left:%d right:%d top:%d bot:%d\n",left,right,top,bot); 39 } 40 };

下一步就是识别出参数框里的文字了,需要数据集和标签的可以联系我。
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-chi-sim
tesseract cut1_93.jpg out -l eng+chi_sim
out.txt 就可以看了