Flink官方文档笔记10 Flink基础内容
文章目录
- 这个笔记的范围
- 流处理
- 并行数据流
- Timely Stream Processing
- Stateful Stream Processing
- Fault Tolerance via State Snapshots 通过状态快照实现容错性
这个笔记的范围
This training presents an introduction to Apache Flink that includes just enough to get you started writing scalable streaming ETL, analytics, and event-driven applications, while leaving out a lot of (ultimately important) details.
本笔记介绍了Apache Flink,其中包含的内容足以让您开始编写可伸缩流ETL、分析和事件驱动的应用程序,但忽略了许多(最重要的)细节。
The focus is on providing straightforward introductions to Flink’s APIs for managing state and time, with the expectation that having mastered these fundamentals, you’ll be much better equipped to pick up the rest of what you need to know from the more detailed reference documentation.
本文的重点是为管理状态和时间的Flink api提供简单的介绍,您掌握了这些基础知识,就能够更好地从更详细的参考文档中学习需要了解的其他内容。(这是一个简单的demo,具体细节还要深入研究)
The links at the end of each section will lead you to where you can learn more.
每个部分末尾的链接将引导您了解更多内容。
具体来说,你会了解以下内容
- 如何实现流数据处理管道
- Flink如何以及为什么管理状态
- 如何使用事件时间来一致地计算精确的分析
- 如何在连续流上构建事件驱动的应用程序
- Flink如何能够提供容错、有状态流处理与精确的一次语义
This training focuses on four critical concepts: continuous processing of streaming data, event time, stateful stream processing, and state snapshots. This page introduces these concepts.
该培训集中于四个关键概念:流数据的连续处理、事件时间、有状态流处理和状态快照。这一页介绍了这些概念。
Note Accompanying this training is a set of hands-on exercises that will guide you through learning how to work with the concepts being presented.
注意,伴随此培训的是一组动手练习,将指导您学习如何使用所呈现的概念。
A link to the relevant exercise is provided at the end of each section.
每个部分的末尾都提供了相关练习的链接。
流处理
Streams are data’s natural habitat.
流是数据的自然栖息地。
Whether it is events from web servers, trades from a stock exchange, or sensor readings from a machine on a factory floor, data is created as part of a stream.
无论是来自web服务器的事件、来自股票交易所的交易,还是来自工厂机器的传感器读数,数据都是作为流的一部分创建的。
But when you analyze data, you can either organize your processing around bounded or unbounded streams, and which of these paradigms you choose has profound(深厚的,意义深远的) consequences(后果,结果,影响).
但是,在分析数据时,可以围绕有界流或无界流组织处理,选择哪一种方式都会产生深远的影响。
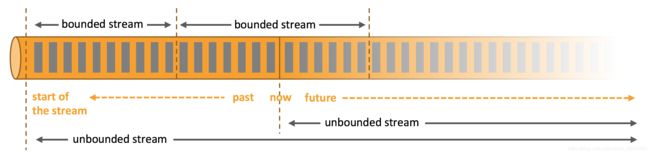
Batch processing is the paradigm at work when you process a bounded data stream.
批处理是处理有界数据流时的范例。
In this mode of operation you can choose to ingest the entire dataset before producing any results, which means that it is possible, for example, to sort the data, compute global statistics, or produce a final report that summarizes all of the input.
在这种操作模式中,您可以选择在生成任何结果之前摄入整个数据集,这意味着可以对数据进行排序、计算全局统计信息或生成汇总所有输入的最终报告。
Stream processing, on the other hand, involves unbounded data streams.
另一方面,流处理涉及到无限制的数据流。
Conceptually, at least, the input may never end, and so you are forced to continuously process the data as it arrives.
至少在概念上,输入可能永远不会结束,因此您必须在数据到达时不断地处理它。
In Flink, applications are composed of streaming dataflows that may be transformed by user-defined operators.
在Flink中,应用程序由可由用户定义的操作符转换的流数据流组成。
These dataflows form directed graphs that start with one or more sources, and end in one or more sinks.
这些数据流形成有向图,以一个或多个源开始,并以一个或多个汇聚结束。

Often there is a one-to-one correspondence between the transformations in the program and the operators in the dataflow.
通常在程序中的转换和数据流中的操作符之间存在一对一的对应关系。
Sometimes, however, one transformation may consist of multiple operators.
但是,有时一个转换可能包含多个操作符。
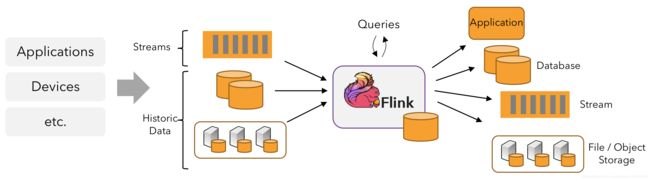
An application may consume real-time data from streaming sources such as message queues or distributed logs, like Apache Kafka or Kinesis.
应用程序可以使用来自流媒体来源的实时数据,如消息队列或分布式日志,如Apache Kafka或Kinesis。
But flink can also consume bounded, historic data from a variety of data sources.
但是flink还可以使用来自各种数据源的有限的历史数据。
Similarly, the streams of results being produced by a Flink application can be sent to a wide variety of systems that can be connected as sinks.
类似地,Flink应用程序产生的结果流可以发送到各种各样的系统,这些系统可以作为接收器连接。
并行数据流
Programs in Flink are inherently parallel and distributed.
Flink中的程序本质上是并行和分布式的。
During execution, a stream has one or more stream partitions, and each operator has one or more operator subtasks.
在执行期间,流有一个或多个流分区,每个操作符有一个或多个操作符子任务。
The operator subtasks are independent of one another, and execute in different threads and possibly on different machines or containers.
操作子任务相互独立,在不同的线程中执行,可能在不同的机器或容器上执行。
The number of operator subtasks is the parallelism of that particular operator.
运算符子任务的数量是该特定运算符的并行度。
Different operators of the same program may have different levels of parallelism.
同一个程序的不同运算符可能具有不同的并行级别。
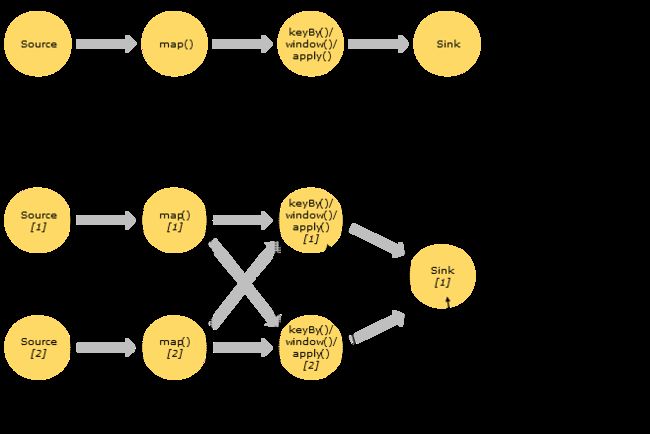
Streams can transport data between two operators in a one-to-one (or forwarding) pattern, or in a redistributing pattern:
-
One-to-one streams (for example between the Source and the map() operators in the figure above) preserve the partitioning and ordering of the elements.
一对一流(例如上图中的Source和map()操作符之间的流)保持了元素的分区和排序。
That means that subtask[1] of the map() operator will see the same elements in the same order as they were produced by subtask[1] of the Source operator.
这意味着map()操作符的子任务[1]将看到与Source操作符的子任务[1]生成的元素顺序相同的元素。 -
Redistributing streams (as between map() and keyBy/window above, as well as between keyBy/window and Sink) change the partitioning of streams.
重新分配流(就像上面的map()和keyBy/window之间,以及keyBy/window和Sink之间)改变了流的分区。
Each operator subtask sends data to different target subtasks, depending on the selected transformation.
根据所选择的转换,每个操作符子任务将数据发送到不同的目标子任务。
Examples are keyBy() (which re-partitions by hashing the key), broadcast(), or rebalance() (which re-partitions randomly).
例如keyBy()(通过散列键重新分区)、broadcast()或rebalance()(随机重新分区)。
In a redistributing exchange the ordering among the elements is only preserved within each pair of sending and receiving subtasks (for example, subtask[1] of map() and subtask[2] of keyBy/window).
在重分发交换中,元素之间的顺序只保留在每对发送和接收子任务中(例如map()的子任务[1]和keyBy/window的子任务[2])。
So, for example, the redistribution between the keyBy/window and the Sink operators shown above introduces non-determinism regarding the order in which the aggregated results for different keys arrive at the Sink.
因此,例如,上面所示的keyBy/窗口和接收操作符之间的重新分配引入了关于不同键的聚合结果到达接收的顺序的不确定性。
Timely Stream Processing
For most streaming applications it is very valuable to be able re-process historic data with the same code that is used to process live data – and to produce deterministic, consistent results, regardless.
对于大多数流媒体应用程序来说,能够使用与处理实时数据相同的代码重新处理历史数据,并生成确定性的、一致的结果是非常有价值的。
It can also be crucial to pay attention to the order in which events occurred, rather than the order in which they are delivered for processing, and to be able to reason about when a set of events is (or should be) complete.
注意事件发生的顺序(而不是交付处理的顺序),并且能够推断一组事件何时(或应该)完成,这一点也很重要。
For example, consider the set of events involved in an e-commerce transaction, or financial trade.
例如,考虑电子商务交易或金融交易中涉及的事件集。
These requirements for timely stream processing can be met by using event time timestamps that are recorded in the data stream, rather than using the clocks of the machines processing the data.
通过使用记录在数据流中的事件时间戳,而不是使用处理数据的机器的时钟,可以满足及时流处理的这些需求。
Stateful Stream Processing
Flink’s operations can be stateful.
Flink的操作可以是有状态的。
This means that how one event is handled can depend on the accumulated effect of all the events that came before it.
这意味着一个事件的处理方式取决于之前发生的所有事件的累积效果。
State may be used for something simple, such as counting events per minute to display on a dashboard, or for something more complex, such as computing features for a fraud detection model.
状态可以用于简单的事情,比如计算每分钟在仪表板上显示的事件,也可以用于更复杂的事情,比如欺诈检测模型的计算特性。
A Flink application is run in parallel on a distributed cluster.
Flink应用程序在分布式集群上并行运行。
The various parallel instances of a given operator will execute independently, in separate threads, and in general will be running on different machines.
给定操作符的各种并行实例将在单独的线程中独立执行,通常在不同的机器上运行。
The set of parallel instances of a stateful operator is effectively a sharded key-value store.
有状态操作符的并行实例集实际上是分片键值存储。
Each parallel instance is responsible for handling events for a specific group of keys, and the state for those keys is kept locally.
每个并行实例负责处理特定键组的事件,这些键的状态保存在本地。
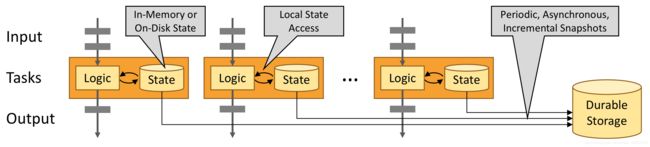
The diagram below shows a job running with a parallelism of two across the first three operators in the job graph, terminating in a sink that has a parallelism of one.
下图显示了一个作业图中前三个操作符的并行度为2的作业,终止于并行度为1的接收。
The third operator is stateful, and you can see that a fully-connected network shuffle is occurring between the second and third operators.
第三个操作符是有状态的,可以看到在第二个和第三个操作符之间发生了完全连接的网络转移。
This is being done to partition the stream by some key, so that all of the events that need to be processed together, will be.
这样做是为了按某个键对流进行分区,以便需要一起处理的所有事件都将被处理。

State is always accessed locally, which helps Flink applications achieve high throughput and low-latency.
状态总是在本地访问,这有助于Flink应用程序实现高吞吐量和低延迟。
You can choose to keep state on the JVM heap, or if it is too large, in efficiently organized on-disk data structures.
您可以选择将状态保存在JVM堆上,或者如果它太大,可以在有效组织的磁盘数据结构中保存状态。
Fault Tolerance via State Snapshots 通过状态快照实现容错性
Flink is able to provide fault-tolerant, exactly-once semantics through a combination of state snapshots and stream replay.
通过状态快照和流重播的组合,Flink能够提供精确的一次容错语义。
These snapshots capture the entire state of the distributed pipeline, recording offsets into the input queues as well as the state throughout the job graph that has resulted from having ingested the data up to that point.
这些快照捕获分布式管道的整个状态,将偏移量记录到输入队列中,以及由于摄入数据而导致的整个作业图中的状态。
When a failure occurs, the sources are rewound(倒带), the state is restored, and processing is resumed.
当发生故障时,将重绕源,恢复状态,并恢复处理。
As depicted above, these state snapshots are captured asynchronously, without impeding the ongoing processing.
如上所示,这些状态快照是异步捕获的,不会妨碍正在进行的处理。