ES _cat/health?v详解
公司的监控系统使用了curl -s http://localhost:9200/_cat/health?v来获取集群的健康状态。
那么_cat/health?v返回的结果到底什么意思呢?每个结果对生产环境的集群健康到底有什么参考意义呢?
_cat/health?v介绍
1、用途
此命令常见的用途一般有两个:
1、验证节点之间的健康状况是否一致,
2、跟踪大型集群随时间的故障恢复情况
2、结果解析
正常情况下,执行curl -s http://localhost:9200/_cat/health?v命令得到的结果如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558506494 14:28:14 hdzx_elk green 3 3 282 141 0 0 0 0 - 100.0%
含义如下:
前两个是时间戳,不过多介绍。其余如下:
- cluster ,集群名称
- status,集群状态 green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据。
- node.total,代表在线的节点总数量
- node.data,代表在线的数据节点的数量
- shards, active_shards 存活的分片数量
- pri,active_primary_shards 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
- relo, relocating_shards 迁移中的分片数量,正常情况为 0
- init, initializing_shards 初始化中的分片数量 正常情况为 0
- unassign, unassigned_shards 未分配的分片 正常情况为 0
- pending_tasks,准备中的任务,任务指迁移分片等 正常情况为 0
- max_task_wait_time,任务最长等待时间
- active_shards_percent,正常分片百分比 正常情况为 100%
_cat/health?v测试
拿了三个节点的ES集群进行测试。
1、首先正常情况下,看head插件中的集群状态如下:
 可以看到每个索引有5个主分片,每个主分片的副本不会与主分片分布在同一个节点上。
可以看到每个索引有5个主分片,每个主分片的副本不会与主分片分布在同一个节点上。
这时执行curl -s http://localhost:9200/_cat/health?v命令得到的结果如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558506494 14:28:14 hdzx_elk green 3 3 282 141 0 0 0 0 - 100.0%
可见relo、 init 、unassign、 pending_tasks 均为0;active_shards_percent值为100.0%,一切正常。
2、这时停掉一个ES节点,此时有两个健康节点,
使用_cat/health?v命令循环查看集群的状态。
如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558520494 18:21:34 hdzx_elk yellow 2 2 201 151 0 0 101 0 - 66.6%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558520545 18:22:25 hdzx_elk yellow 2 2 289 151 0 2 11 0 - 95.7%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558520556 18:22:36 hdzx_elk green 2 2 302 151 0 0 0 0 - 100.0%
结合时间戳可以看到集群有个自恢复的过程,
- 一个节点刚停止时,集群状态变成yellow,正常分片的占比不到100%;
- 出现初始化状态(init)的分片,并随着时间的推移减少;
- 随着初始化状态分片的减少,出现迁移状态(relo)的分片;
- 慢慢的分片迁移完成,集群状态变成green,正常分片的占比达到100%。
- 按理期间会出现unassign 状态的分片,但是,没截到
我们去head页面查看集群状态如下:
 可见此时有两个节点,主分片和副分片仍不在同一个节点上。
可见此时有两个节点,主分片和副分片仍不在同一个节点上。
3、再停止一个节点,此时只有一个正常节点
使用_cat/health?v命令循环查看集群的状态。
如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558523601 19:13:21 hdzx_elk yellow 1 1 151 151 0 0 151 0 - 50.0%
- 会一直是yellow状态;
- 没有多余的节点去放副分片,active_shards_percent 将一直是50%
- init状态的分片也会一直与主分片的数量保持一致。
- 按理期间会出现unassign 状态的分片,但是,没截到
此时去head页面查看集群的状态如下:

可以看到此时只有主分片在唯一的一个节点上,所以集群状态为yellow。
4、此时恢复一个节点,将有两个节点正常运行。
使用_cat/health?v命令循环查看集群的状态。
如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558524428 19:27:08 hdzx_elk yellow 2 2 178 151 0 2 122 0 - 58.9%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558524437 19:27:17 hdzx_elk yellow 2 2 208 151 0 2 92 0 - 68.9%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558524455 19:27:35 hdzx_elk yellow 2 2 274 151 0 2 26 0 - 90.7%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558524500 19:28:20 hdzx_elk green 2 2 302 151 0 0 0 0 - 100.0%
可见随着时间的推移:
- 出现init状态的分片,数量将变小至0,
- 出现relo状态的分片,数量将变小,
- 按理期间会出现unassign 状态的分片,但是,没截到,
- 最终active_shards_percent 变为百分百,集群状态变成green,
5、恢复第三个节点
使用_cat/health?v命令循环查看集群的状态。
如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558525121 19:38:41 hdzx_elk yellow 3 3 282 151 0 0 20 1 - 93.4%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558525125 19:38:45 hdzx_elk yellow 3 3 293 151 0 2 7 0 - 97.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558525129 19:38:49 hdzx_elk green 3 3 302 151 2 0 0 0 - 100.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1558525225 19:40:25 hdzx_elk green 3 3 302 151 0 0 0
- 可以看到集群状态会从green变成yellow再变成green;
- 部分分片发生了迁移;
- 会出现init,unassign,relo状态的分片;
- active_shards_percen也会发生变化
再次看head页面会发现,虽然都是三个节点,但是分片的分布状态不一样。
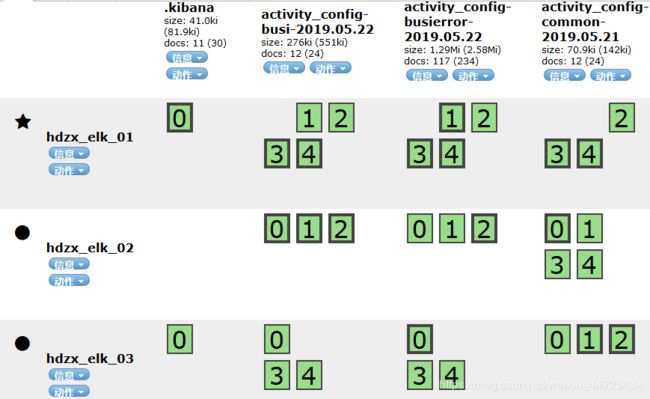
结论
- 使用_cat/health?v这个命令获取结果,不能看当时结果,需要看趋势。
- 出现init,unassign,relo状态的分片时,如果之前没有人启动es节点,那可能是有节点脱离集群,即使自动恢复,也需要确认节点数量。
- 监控时最好添加集群中节点数量的监控。