先看,前一期博客,理清好思路。
爬虫概念与编程学习之如何爬取网页源代码(一)
爬虫概念与编程学习之如何爬取视频网站页面(用HttpClient)(二)
不多说,直接上代码。

编写代码


运行

- 剧集:微微一笑很倾城2016
- 30集全
- 别名:微微一笑很倾城电视剧版/A Smile Is Beautiful
- 2015-12-21
- 2016-08-22
- 评分: 9.9
- 主演:杨洋/郑爽/毛晓彤
- 导演:林玉芬
- 地区:大陆
- 类型:剧情/都市/言情
- 总播放数:17,007,967,162
- 评论:1,256,002
- 顶:13,827,796
- 指数:
- 简介:美女学霸贝微微,立志成为游戏工程师,化名“芦苇微微”跻身网游高手,因拒绝上传真实照片而惨遭侠侣“真水无香”无情抛弃,却意外得到江湖第一高手“一笑奈何”的垂青。为了赢得“侠侣挑战赛”,贝微微欣然答应与“一笑奈何”结盟并组队参赛。两人一路闯荡江湖早已心灵相通,可贝微微做梦也没想到,一路出生入死的伙伴竟然就是同校风云人物——师兄...查看详情
附上代码
Page.java(新建一个实体类,用来存储需要爬取的数据)
package zhouls.bigdata.mySpider.entity;
/**
*
* @author zhouls
* created by 2017-01-11
*
*/
public class Page {
//页面内容
private String content;
//总播放量
private String allnumber;
//每日播放总量
private String daynumber;
//评论数
private String commentnumber;
//收藏数
private String collectnumber;
//赞
private String supportnumber;
//踩
private String againstnumber;
//电视剧名称
private String tvname;
//页面url
private String url;
//子集
private String episodenumber;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getAllnumber() {
return allnumber;
}
public void setAllnumber(String allnumber) {
this.allnumber = allnumber;
}
public String getDaynumber() {
return daynumber;
}
public void setDaynumber(String daynumber) {
this.daynumber = daynumber;
}
public String getCommentnumber() {
return commentnumber;
}
public void setCommentnumber(String commentnumber) {
this.commentnumber = commentnumber;
}
public String getCollectnumber() {
return collectnumber;
}
public void setCollectnumber(String collectnumber) {
this.collectnumber = collectnumber;
}
public String getSupportnumber() {
return supportnumber;
}
public void setSupportnumber(String supportnumber) {
this.supportnumber = supportnumber;
}
public String getAgainstnumber() {
return againstnumber;
}
public void setAgainstnumber(String againstnumber) {
this.againstnumber = againstnumber;
}
public String getTvname() {
return tvname;
}
public void setTvname(String tvname) {
this.tvname = tvname;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getEpisodenumber() {
return episodenumber;
}
public void setEpisodenumber(String episodenumber) {
this.episodenumber = episodenumber;
}
}
set去赋值,get去取值
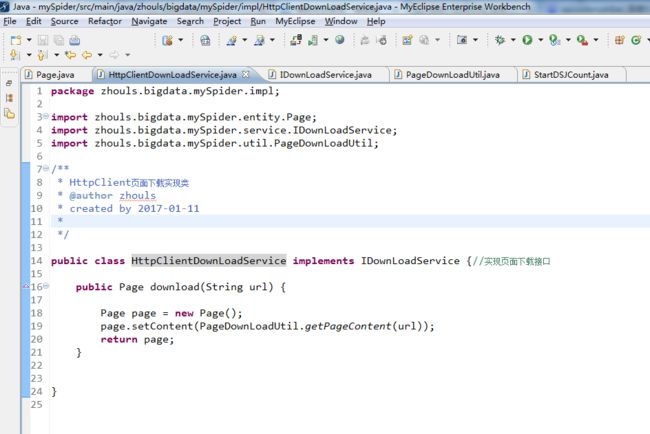
HttpClientDownLoadService.java代码(页面接口实现类HttpClientDownLoadService)
package zhouls.bigdata.mySpider.impl;
import zhouls.bigdata.mySpider.entity.Page;
import zhouls.bigdata.mySpider.service.IDownLoadService;
import zhouls.bigdata.mySpider.util.PageDownLoadUtil;
/**
* HttpClient页面下载实现类
* @author zhouls
* created by 2017-01-11
*
*/
public class HttpClientDownLoadService implements IDownLoadService {//实现页面下载接口
public Page download(String url) {
Page page = new Page();
page.setContent(PageDownLoadUtil.getPageContent(url));
return page;
}
}
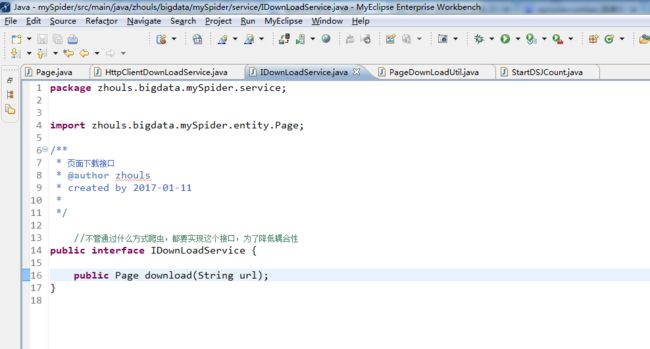
IDownLoadService.java代码(新建一个页面下载接口,给定url,返回Page,url返回的页面 内容保存在page的content属性中。接口的目的,降低代码耦合度。)
package zhouls.bigdata.mySpider.service;
import zhouls.bigdata.mySpider.entity.Page;
/**
* 页面下载接口
* @author zhouls
* created by 2017-01-11
*
*/
//不管通过什么方式爬虫,都要实现这个接口,为了降低耦合性
public interface IDownLoadService {
public Page download(String url);
}
PageDownLoadUtil.java代码(在页面下载工具类的main方法中进行测试)
package zhouls.bigdata.mySpider.util;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import zhouls.bigdata.mySpider.entity.Page;
import zhouls.bigdata.mySpider.impl.HttpClientDownLoadService;
/**
*
* @author zhouls
* created by 2017/1/11
*
*/
public class PageDownLoadUtil {
public static String getPageContent(String url){
HttpClientBuilder builder = HttpClients.custom(); //这是使用HttpClient来构造登录信息, 好的博客,见https://segmentfault.com/a/1190000003013451
CloseableHttpClient client = builder.build();
HttpGet request = new HttpGet(url);//创建一个get请求
String content = null;
try {
CloseableHttpResponse response = client.execute(request);
HttpEntity entity = response.getEntity();//获取HttpGet
content = EntityUtils.toString(entity,"utf-8");//将HttpGet转换成string
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return content;//这个值,就是我们需要的页面内容
}
public static void main(String[] args) {
//这是直接,下载网页源代码
// String url = "http://list.youku.com/show/id_z9cd2277647d311e5b692.html?spm=a2h0j.8191423.sMain.5~5~A!2.iCUyO9";
// String content = PageDownLoadUtil.getPageContent(url);
// System.out.println(content);
String url = "http://list.youku.com/show/id_z9cd2277647d311e5b692.html?spm=a2h0j.8191423.sMain.5~5~A!2.iCUyO9";
HttpClientDownLoadService down = new HttpClientDownLoadService();
Page page = down.download(url);
System.out.println(page.getContent());
}
}
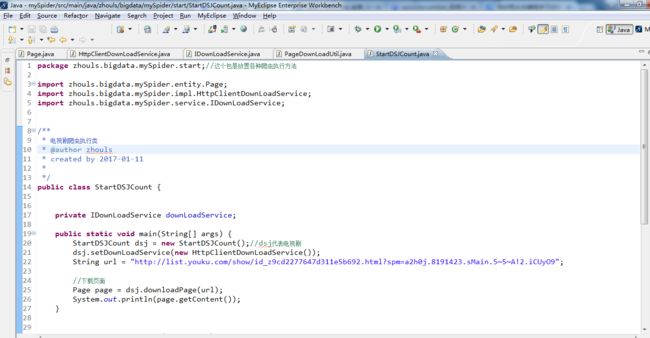
StartDSJCount代码(电视剧爬虫执行类)
package zhouls.bigdata.mySpider.start;//这个包是放置各种爬虫执行方法
import zhouls.bigdata.mySpider.entity.Page;
import zhouls.bigdata.mySpider.impl.HttpClientDownLoadService;
import zhouls.bigdata.mySpider.service.IDownLoadService;
/**
* 电视剧爬虫执行类
* @author zhouls
* created by 2017-01-11
*
*/
public class StartDSJCount {
private IDownLoadService downLoadService;
public static void main(String[] args) {
StartDSJCount dsj = new StartDSJCount();//dsj代表电视剧
dsj.setDownLoadService(new HttpClientDownLoadService());
String url = "http://list.youku.com/show/id_z9cd2277647d311e5b692.html?spm=a2h0j.8191423.sMain.5~5~A!2.iCUyO9";
//下载页面
Page page = dsj.downloadPage(url);
System.out.println(page.getContent());
}
public Page downloadPage(String url){
return this.downLoadService.download(url);
}
public IDownLoadService getDownLoadService() {
return downLoadService;
}
public void setDownLoadService(IDownLoadService downLoadService) {
this.downLoadService = downLoadService;
}
}
即,下载视频网站页面成功!下一步工作,是解析。